






概述
生成中会生产大量的系统日志、应用程序日志、安全日志等,通过对日志的分析可以了解服务器的负载、健康状况,可以分析客户的分布情况、客户行为,甚至基于这些分析可以做出预测
- 一般采集流程
日资产处 -> 采集(Logstash、Flume、Scribe) -> 存储 -> 分析 -> 存储(数据库、NoSQL) -> 可视化 - 开源实时日志分析ELK平台
Logstash收集日志,并存放到ElasticSearch集群中,Kibana则从ES集群中查询数据生成图表,返回浏览器端
数据提取
半结构化数据
- 日志是半结构化数据,是有组织的、有格式的数据。可以分割成行和咧,就可以当做表理解和处理了,当然也可以分析里面的数据
文本分析
- 日志是文本文件,需要依赖文件IO、字符串操作、正则表达式等技术
- 通过这些技术就能够把日志中需要的数据提取出来

- 这是最常见的日志,nginx、tomcat等WEB Server都会产生这样的日志。如何提取出数据?
这里面每一段有效的数据对后期的分析都是必须的
提取数据代码实现
# 使用正则表达式
import re
line = '''183.60.212.153 - - [19/Feb/2013:10:23:29 +0800] \
"GET /o2o/media.html?menu=3 HTTP/1.1" 200 16691 "-" \
"Mozilla/5.0 (compatible; EasouSpider; +http://www.easou.com/search/spider.html)"'''
pattern = '([\d.]{7,}) - - \[(.+)\] \
"(.+) (.+) (.+)" (\d{3}) (\d+) "[^"]+" "([^"]+)"'
regex = re.compile(pattern)
def extract(logline:str):
m = regex.match(logline)
if m :
print(m.groups())
extract(line)
# 输出结果
('183.60.212.153', '19/Feb/2013:10:23:29 +0800', 'GET',\
'/o2o/media.html?menu=3', 'HTTP/1.1', '200', '16691', \
'Mozilla/5.0 (compatible; EasouSpider; \
+http://www.easou.com/search/spider.html)')
使用上面的分组就可以提取到所有想要数据的分组
类型转换
fields中的数据是有类型的,例如时间、状态码等。对不同的field要做不同的类型转换,甚至是自定义的转换
- 19/Feb/2013:10:23:29 +0800 对应格式 %d/%b/%Y:%H:%M:%S %Z
- 使用datetime类的strptime方法
import datatime
def convert_time(timestr):
return datetime.datetime.strptime(timestr, '%d/%b/%Y:%H:%M:%S %z')
可以得到
lambda timestr:datetime.datetime.strptime(timestr, '%d/%b/%Y:%H:%M:%S %z')
- 状态码和字节数
都是整型,使用int函数转换
映射
对每一个字段命名,然后与值和类型转换的方法对应
最简单的方式,就是使用正则表达式分组
import re
import datetime
line = '''183.60.212.153 - - [19/Feb/2013:10:23:29 +0800] \
"GET /o2o/media.html?menu=3 HTTP/1.1" 200 16691 "-" \
"Mozilla/5.0 (compatible; EasouSpider; +http://www.easou.com/search/spider.html)"'''
pattern = '(?P<remote>[\d.]{7,}) - - \[(?P<datetime>.+)\] \
"(?P<method>.+) (?P<url>.+) (?P<protocol>.+)" \
(?P<status>\d{3}) (?P<size>\d+) "[^"]+" "(?P<useragent>[^"]+)"'
regex = re.compile(pattern)
conversion = {
'datetime': lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'),
'status':int,
'size':int
}
def extract(logline:str):
m = regex.match(logline)
if m :
return {k:conversion.get(k, lambda x:x)(v) for k,v in m.groupdict().items()}
print(extract(line))
# 打印结果
{'remote': '183.60.212.153', \
'datetime': datetime.datetime(2013, 2, 19, 10, 23, 29, tzinfo=datetime.timezone(datetime.timedelta(0, 28800))),\
'method': 'GET', 'url': '/o2o/media.html?menu=3', \
'protocol': 'HTTP/1.1', 'status': 200, 'size': 16691,\
'useragent': 'Mozilla/5.0 (compatible; EasouSpider; +http://www.easou.com/search/spider.html)'}
异常处理
日志中不免会出现一些不匹配的行,需要处理
这里使用re.match方法,有可能匹配不上。所以要增加一个判断
采用抛出异常的方式,让调用者获得异常并自行处理
def extract(logline:str):
"""返回字段的字典,抛出异常说明匹配失败"""
m = regex.match(logline)
if m :
return {k:conversion.get(k, lambda x:x)(v) for k,v in m.groupdict().items()}
else:
raise Exception('No match. {}'.format(line)) # 或输出日志记录
也可以采用返回一个特殊值的方式,告知调用者没有匹配
def extract(logline:str):
"""返回字段的字典,抛出异常说明匹配失败"""
m = regex.match(logline)
if m :
return {k:conversion.get(k, lambda x:x)(v) for k,v in m.groupdict().items()}
else:
return None # 或输出日志记录
通过返回值,在函数外部获取了None,同样也可以才去一些措施。本次采用返回None的实现
数据载入
对于本项目来说,数据就是日志的一行行记录,载入数据就是文件IO的读取。将获取数据的方法封装成函数
def load(path):
"""装载日志文件"""
with open(path) as f:
for line in f:
fields = extract(line)
if fields:
yield fields
else:
continue # TODO 以后处理,丢弃数据或记录在日志中
日志文件的加载
- 目前实现的代码中,只能接受一个路径,修改为接受一批路径
- 可以约定一下路径下文件的存放方式:
如果送来的是一批路径,就迭代其中路径
如果路径是一个普通文件,就直接加载这个文件
如果路径是一个目录,就遍历路径下所有指定类型的文件,每一个文件按照行处理
可以提供参数处理是否递归子目录
完整代码
from pathlib import Path
import re
import datetime
pattern = '(?P<remote>[\d.]{7,}) - - \[(?P<datetime>.+)\] \
"(?P<method>.+) (?P<url>.+) (?P<protocol>.+)" \
(?P<status>\d{3}) (?P<size>\d+) "[^"]+" "(?P<useragent>[^"]+)"'
regex = re.compile(pattern)
conversion = {
'datetime': lambda datestr:datetime.datetime.strptime(datestr,'%d/%b/%Y:%H:%M:%S %z'),
'status':int,
'size':int
}
def extract(logline:str) -> dict:
"""返回字段的字典,抛出异常说明匹配失败"""
m = regex.match(logline)
if m :
return {k:conversion.get(k, lambda x:x)(v) for k,v in m.groupdict().items()}
else:
raise Exception('No match. {}'.format(line)) # 或输出日志记录
def loadfile(filename:str,encoding='utf-8'):
"""装载日志文件"""
with open(filename,encoding=encoding) as f:
for line in f:
fields = extract(line)
if fields:
yield fields
else:
continue # TODO 以后处理,丢弃数据或记录在日志中
def load(*paths, encoding='utf-8', ext='*.log', recursive=False):
"""装载日志文件"""
for x in paths:
print(x)
p = Path(x)
if p.is_dir(): # 处理目录
if isinstance(ext, str):
ext = [ext]
else:
ext = list(ext)
for e in ext:
files = p.rglob(e) if recursive else p.glob(e) # 是否递归
for file in files:
yield from loadfile(str(file.absolute()), encoding=encoding) #file.absolute() 取文件绝对路径
elif p.is_file(): # 处理文件
yield from loadfile(str(p.absolute()), encoding=encoding)
分发
生产者消费者模型
- 一个系统的健康运行,需要监控并处理很多数据,包括日志
- 对其中已有数据进行采集、分析
- 被监控对象就是数据的生产者producer,数据的处理程序就是数据的消费者consumer
生产者消费者传统模型
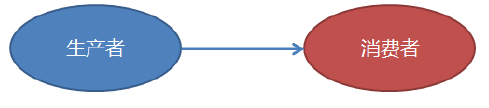
- 最不容易解决的就是生产者和消费者速度要匹配的问题
- 但是,真实情况下往往生产和消费的速度就不能够很好的匹配
解决办法
- 队列queue
作用
- 解耦、缓冲
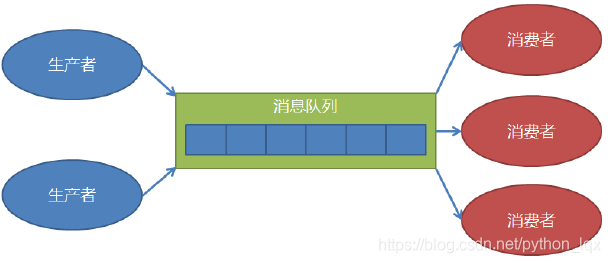
日志生产者往往会部署好几个程序,日志产生的也很多,而消费者也会有多个程序,去提取日志分析处理 - 数据的生产是最不稳定的。可能会造成短时间数据的“潮涌”,需要缓冲
- 消费者消费能力不一样,有快有慢,消费者可以自己决定消费缓冲区中的数据
- 单机时,可以使用标准库queue模块的类来构建进程内的队列,满足多个线程间的生产消费需求
- 大型系统可以使用第三方消息中间件-- RabbitMQ、RocketMQ、Kafka等
数据处理所需模块
queue模块 – 队列
- Queue先进先出,LifoQueue后进先出
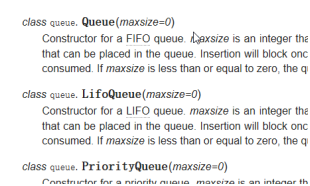
queue模块提供了一个先进先出的队列Queue
queue.Queue(maxsize=0)
- 创建FIFO队列,返回Queue对象
- maxsize 小于等于0,队列长度没有限制
queue.get(block=True, timeout=None)
- 从队列中移除元素并返回这个元素
- block为阻塞,timeout为超时
block为True,是阻塞。timeout为None就是一直阻塞
block为True但是timeout有值,就阻塞到一定秒数抛出Empty异常
block为False,是非阻塞。timeout将被忽略,要么成功返回一个元素,要么抛出empty异常
queue.put(item, block=True, timeout=None)
- 把一个元素加入到队列中去
block=True,timeout=None,一直阻塞直至有空位放元素
block=True,timeout=5,阻塞5秒就抛出Full异常
block=False,timeout失效,立即返回,能塞进去就塞,不能则返回抛出Full异常
Queue.put_nowait(item)
- 等价于put(item,False),也就是能塞进去就塞,不能则返回抛出Full异常
# Queue测试
from queue import Queue
import random
q = Queue()
q.put(random.randint(1,100)
q.put(random.randint(1,100)
print(q.get())
print(q.get())
# print(q.get()) # 阻塞
# print(q.get(timeout-3)) # 阻塞,但超时抛异常
print(q.get_nowait()) # 不阻塞,没数据立即抛异常
- 注意: Queue的数据一旦被get后,就会从队列中消失
threading模块–线程
import threading
def handle(a, b):
print(a, b)
print('-' * 30)
# 定义线程
# target线程中运行的函数; args这个函数运行时需要的实参的元组
t = threading.Thread(target=handle, args=(4, 5))
# 启动线程
t.start()
- 上面的代码执行一次就退出了线程,如果想让线程不退出,修改handel函数如下
import threading
import time
def handle(a, b):
while True:
print(a, b)
print('-' * 30)
time.sleep(1)
# 定义线程
# target线程中运行的函数; args这个函数运行时需要的实参的元组
t = threading.Thread(target=handle, args=(4, 5))
# 启动线程
t.start()
为了让生产者的生产数据和消费者的消费数据同时进行,可以使用不同的线程
数据处理流程
- 生产者(数据源)生产数据,缓冲到消息队列中
- 数据处理流程:

分发器的实现
- 数据分析的程序有很多,例如PV分析、IP分析、UserAgent分析等
- 同一套数据可能要被多个分析程序并行处理:
需要使用多线程来并行处理
多个分许程序又需要同一份数据,这就是一份变多分 - 数据处理流程:
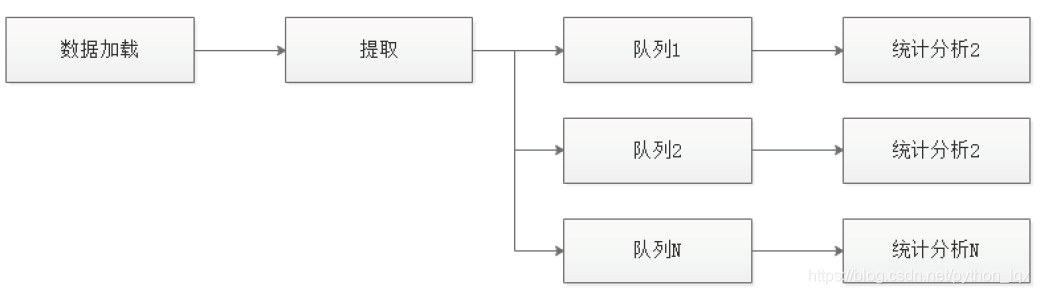
- 这是一个典型的分发器
注册统计分析函数,并为其提供一个单独的数据队列
收集日志数据
将一份日志数据发送到多个已注册的分析函数的队列中去
为了并行,每一个分析函数都在一个独立的线程中执行
from queue import Queue
import threading
# 消息队列, 分发
def dispatcher(src):
handlers = []
queues = []
def reg(handle):
q = Queue()
queues.append(q)
t = threading.Thread(target=handle, args=(q,))
handlers.append(t)
def run():
for t in handlers:
t.start() # 启动线程,运行所有的处理函数
for item in src:
for q in queues:
q.put(item)
return reg, run
reg, run = dispatcher(load('/logs'))
分析器
IP分析
分析一段时间内,不同IP字出现的次数。基于IP可以分析出用户的地理分布
# IP分析
@reg
def ip_handle(q:Queue):
ips = {}
while True:
data = q.get() # 阻塞读取
ip = data.get('remote')
if ip:
ips[ip] = ips.get(ip, 0) + 1
print(len(ips), ips.keys())
print(sorted(ips.itmes(), key=lambda x:x[1], reverse=True))
这段程序可以得到对于所有文档一个IP的统计
PV分析
PV指的是Page view,也就是页面浏览量或页面点击量
PV分析,就是按照URL分析
- 不同URL被不同的用户访问了几次?
- 两种计算:
1.同一个用户不管刷新多少下同一个页面,就算1次
2.同意用户刷新同一个页面也算1次
url分析
from urllib.parse import urlparse
urls = [
'http://www.python.org'
'/index.html'
'/index.html?id=5&age=20'
]
for i, url in enumerate(urls, 1):
t = urlparse(url)
print(i, url)
print(i, t, t.path)
# 打印结果
1 http://www.python.org/index.html/index.html?id=5&age=20
1 ParseResult(scheme='http', netloc='www.python.org',\
path='/index.html/index.html', params='', query='id=5&age=20',\
fragment='') /index.html/index.html
pv分析
@reg
def pv_handle(q:Queue):
pvs = {}
while True:
data = q.get()
ip = data.get('remote')
url = data.get('url')
if ip and url:
path = urlparse(url).path
if path not in pvs:
pvs[path] = {}
pvs[path][ip] = pvs[path].get(ip, 0) + 1
print(pvs)
useragent分析
- useragent指的是,软件按照一定的格式向远端的服务器提供一个表示自己的字符串
- 在HTTP协议中,使用user-agent字段传送这个字符串
- 注意:这个值可以被修改
格式
现在浏览器的user-agent值格式一般如下:
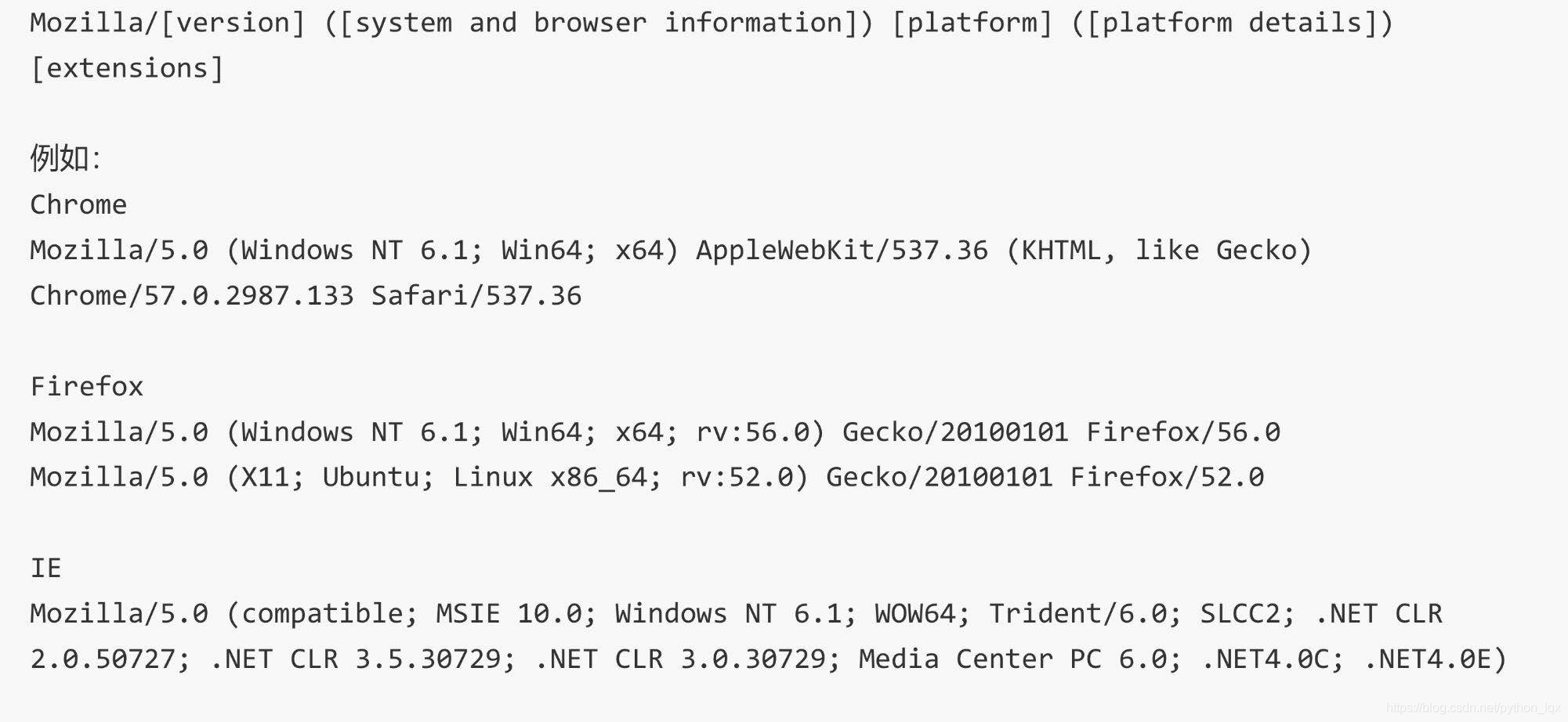
信息提取
pyyaml、ua-parser、user-agents模块
安装
$ pip install pyyaml ua-parser user-agents
使用
from user_agents import parse
useragents = [
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)\
chrome/57.0.2987.133 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2;\
.NET CLR 2.0.50727; .NET CLR 3.5.30729; NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)"
]
for uastring in useragents:
ua = parse(uastring)
print(ua.browser, ua.browser.family, ua.browser.version, ua.browser.version_string)
# 运行结果
Browser(family='Safari', version=(), version_string='') Safari ()
Browser(family='Firefox', version=(56, 0), version_string='56.0') Firefox (56, 0) 56.0
Browser(family='Firefox', version=(52, 0), version_string='52.0') Firefox (52, 0) 52.0
Browser(family='IE', version=(10, 0), version_string='10.0') IE (10, 0) 10.0
- ua.browser.famliy和ua.browser.version_string分别返回浏览器名称、版本号
数据分析
- conversion 增加对useragent的处理
from user_agents import parse
conversion = {
'datetime': lambda datestr:datetime.datetime.strptime(datestr,'%d/%b/%Y:%H:%M:%S %z'),
'status':int,
'length':int
'useragent':lambda ua:parse(ua)
}
- 增加浏览器分析函数
# UserAgent分析
@reg
def ua_handle(q:Queue):
browsers = {}
while True:
data = q.get()
ua = data.get('uaeragent')
if ua:
key = ua.browser.family, ua.browser.version_string
browsers[key] = browsers.get(key, 0) + 1
print(browsers)
完整代码
from user_agents import parse
from pathlib import Path
import datetime
import re
pattern = '(?P<remote>[\d.]{7,}) - - \[(?P<datetime>.+)\] \
"(?P<method>.+) (?P<url>.+) (?P<protocol>.+)" \
(?P<status>\d{3}) (?P<size>\d+) "[^"]+" "(?P<useragent>[^"]+)"'
regex = re.compile(pattern)
conversion = {
'datetime': lambda datestr:datetime.datetime.strptime(datestr,'%d/%b/%Y:%H:%M:%S %z'),
'status':int,
'length':int
'useragent':lambda ua:parse(ua)
}
def extract(logline:str) -> dict:
"""返回字段的字典,如果返回None说明匹配失败"""
m = regex.match(logline)
if m:
return {k:conversion.get(k, lambda x:x)(v) for k, v in m.groupdict().items()}
else:
return None # 或输出日志记录
def loadfile(filename:str, encoding='utf-8'):
"""装载日志文件"""
with open(filename, encoding=encoding) as f:
for line in f:
fields = extract(line)
if fields:
yield fields
else:
continue # TODO 以后处理,丢弃数据或记录在日志中
def load(*paths, encoding='utf-8', ext='*.log', recursive=False):
"""装载日志文件"""
for x in paths:
print(x)
p = Path(x)
if p.is_dir(): # 处理目录
if isinstance(ext, str):
ext = [ext]
else:
ext = list(ext)
for e in ext:
files = p.rglob(e) if recursive else p.glob(e) # 是否递归
for file in files:
yield from loadfile(str(file.absolute()), encoding=encoding)
elif p.is_file():
yield from loadfile(str(p.absolute()), encoding=encoding)
from queue import Queue
import threading
# 消息队列,分发
def dispatcher(src):
handlers = []
queues = []
def reg(handle):
q = Queue()
queues.append(q)
t = threading.Thread(target=handle, args=(q,))
handlers.append(t)
def run():
for t in handlers:
t.start() # 启动线程,运行所有的处理函数
for item in src: # 将数据源取到的数据分发到所有队列中
for q in queues:
q.put(item)
return reg,run
reg, run = dispatcher(load('.'))
# IP分析
@reg
def ip_handle(q:Queue):
ips = {}
while True:
data = q.get() # 阻塞读取
ip = data.get('remote')
if ip:
ips[ip] = ips.get(ip, 0) + 1
# print(len(ips), ips.key())
# print(sorted(ips.items(), key=lambda x:x[1], reverse=True))
from urllib.parse import urlparse
# PV分析
@reg
def pv_handle(q:Queue):
pvs = {}
while True:
data = q.get()
ip = data.get('remote')
url = data.get('url')
if ip and url:
path = urlparse(url).path
if path not in pvs:
pvs[path] = {}
pvs[path][ip] = pvs[path].get(ip, 0) + 1
# print(pvs)
# UserAgent分析
@reg
def ua_handle(q:Queue):
browsers = {}
while True:
data = q.get()
ua = data.get('useragent')
if ua:
key = ua.browser.family, ua.browser.version_string
browsers[key] = browsers.get(key, 0) + 1
print(browsers)
run()














 644
644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









