







前言
想要从零基础成为一名资深的互联网Python开发工程师。有几个阶段是必须要进行的。第一个就是入门阶段俗称Python基础,目前在学习Python的众多人群当中,这一类的人是最多的。甚至有的朋友在这个阶段待了很久也没有实质性的突破。老师课上讲的都会,为什么自己就是想不到,为什么自己就是做不出来呢?
那么第一个阶段突破后就是第二个阶段。Python进阶,在这个阶段是真正把Python划分成了两种人群,一种是不太适合学习的,一种是比较适合学习的。因为在Python进阶这个阶段,你发现你要学习除了Python之外太多的技术了,例如网络编程、多线程多进程、数据库技术、数据分析、甚至是一些框架(Flask、Django、Scrapy...)。在这个阶段是为我们最后一个项目阶段做铺垫的。一个企业的项目用到的技术可不仅仅是Python的语法这么简单了,会Python这门语言只能是最基本的。所以,Python进阶阶段淘汰了很大一批想要做Python开发的人群。
阿喵今天就是来教一下大家Python网络编程相关的一些知识点。当然知识点没有罗列的那么全,大家也可以在此基础之上深入的学习。难道又要开始薅头发了嘛....
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:609616831
网络剖析
无状态协议
先来看一看http,它是超文本传输协议,数据在计算机中进行传输,必须要用到协议,在TCP/IP协议族中,http协议是最常见的。
http是一种无状态的协议, 什么是无状态协议呢?这里我们先对它来做一个解释。
无状态协议就是不保存状态。简单来理解就是,发送的请求和响应的报文信息不会保留, 只要有新的请求发送,就会有对应的新响应。这样做的好处就是能快速的处理大量事务
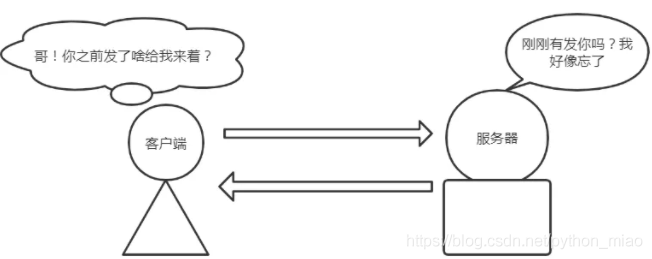
http属于无状态的协议,所以在这个里面引发出了一个问题。
比如现在我用python搭建了一个web网站,现在有一个用户,登录到了这网站页面,拿到了自己的个人用户信息。基于这个点,在用户信息里面再点击了其它的页面信息,很显然这里面的操作,需要继续保持这个登录的状态才能进行后续的操作。既然http属于无状态的协议,那么它是怎么解决这个问题的呢?
这里其实就用到了Cookie技术,使用Cookie就可以实现保持好这登录状态。用户进行请求的时候,在请求头里面会携带Cookie进行发送。
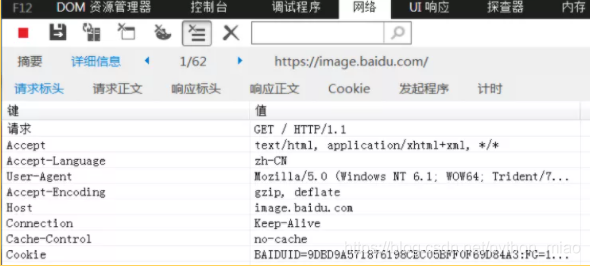
http这种无状态协议的方式,可以减少服务器的CPU以及内存资源的消耗。通过在请求和响应中写入Cookie信息来控制客户端的状态。当我请求之后,它到底是通过什么字段从服务器那边传过来的, 从图里面可以看出,是通过Set-Cookie传送过来的,同时也会通知客户端保存Cookie.
从这个get方法的响应头中就可以看到Set-Cookie的值
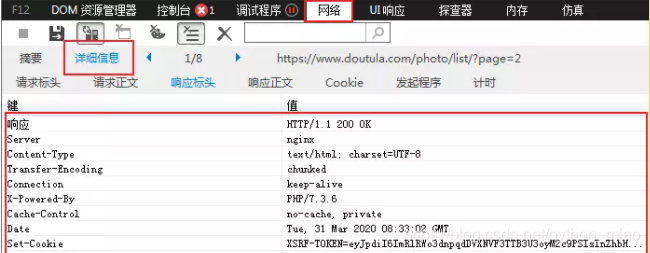
响应头字段表示的含义:
Server: 服务器版本
content-type 文本的类型
Transfer-Encoding 报文主体传输编码方式
connection 长连接
X-Powered-By 编程语言用的版本
Cache-Control 不缓存
Date 创建报文的日期时间
set-cookie 服务器给你传了个cookie
复制代码get和post方法
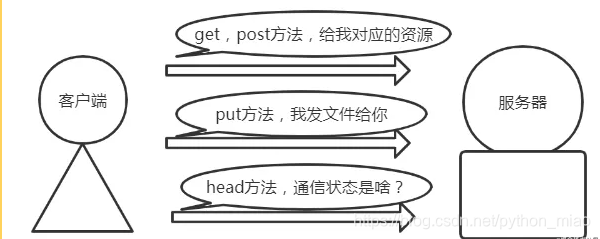
get方法跟post就不做过多的介绍,它们之间的区别来做下对比。除了它们之外,还有put,head等。
-
数据特点:get方法没有请求体,长度大小有限制。post方法有请求体,大小没有限制。
-
安全性:数据传输get方法没post请求安全,get方法的参数在地址栏可以看到参数。
head方法
它在我们的使用中,head方法是很少见的。它跟get方法类似,只是不返回对应的响应体部分。它可以确定url的有效性和资源更新的日期时间等。
状态码
在发送请求获取数据的时候,服务器会给一个状态码来提示客户端数据结果。借助状态码,用户就知道服务器是不是正常的处理了请求。
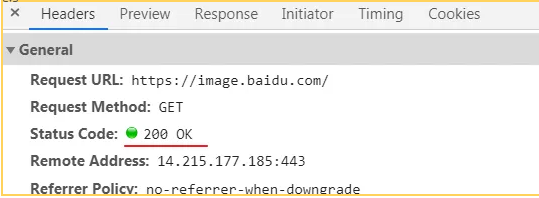
状态码有很多种,三位数字组成。第一位是它的响应类别。一般分为这5个大的种类。
1xx 信息状态码 接收的请求正在处理
2xx 成功状态码 请求正常处理
3xx 重定向状态码 要完成请求需要进行更进一步操作
4xx 客户端错误 服务器无法处理请求
5xx 服务器错误 服务器处理请求出错
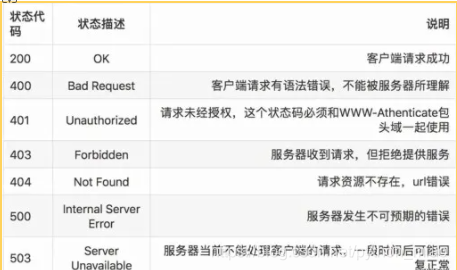
复制代码常见的状态码如下图
不管是用python来做web后端,还是其它的语言。在网络这块始终离不开一个共性的问题 ,就是信息传输的安全性问题。信息在互联网上进行传输,任何地方都存在通信内容被窃听的可能, 那我们是怎么去保证它们通信的安全性呢,其中离不开的就是https
网络安全
不管是用python来做web后端,还是其它的语言。在网络这块始终离不开一个共性的问题 ,就是信息传输的安全性问题。信息在互联网上进行传输,任何地方都存在通信内容被窃听的可能, 那我们是怎么去保证它们通信的安全性呢,其中离不开的就是https
https就是在http后面多加了个s,简单理解就是加密的。要具体对它进行学习,得回顾下前面学过的http这块了,如果有对http这块不熟悉的小伙伴,可以去翻看下前面写过的python网络这块的内容,结合起来学习更容易理解。
先来看看http的优缺点,以及了解它在进行通信的时候会带来的问题, 就知道为什么https会安全些了。
http
http优点:
- 1.传输速度快,非常的灵活。
- 2.是无状态协议,可以减少服务器的CPU以及内存资源的消耗。
- 3.每次连接只处理一个请求,处理完之后就断了,减少资源消耗。
http缺点:
- 1.不能进行大量数据的传输。
- 2.通信的时候使用的是明文,所以导致信息容易被窃听,安全性差。
- 3.通信的时候,不验证身份。如:(python爬虫里面,添加一个ua就可以伪装成浏览器进行欺骗)
- 4.无法验证数据传输的完整性,数据被篡改了都不知道
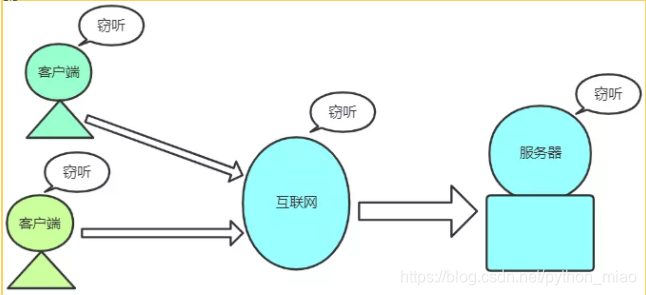
做这样的窃听很简单,使用浏览器上面的抓包工具,对网络进行抓包,就可以看到大量的数据。
http的安全性
拿http的安全性作为讨论。在互联网上,网络可以连通到全世界,在TCP/IP协议族的工作机制中,基因里面就决定了线路上面的内容都可能被窥视到,哪怕是你加过密,那些加过密的通信数据也可能被看到,只是不能破解而已。所以加密的重要性就体现出来了。
加密可以防止信息被窃取,加密的处理方式常见的有这两种:第一种是通信加密,第二种是内容加密。
通信加密其实就是https的方式,内容加密还是用的http, 只不过是把它的传输内容加密了,也有些除了内容加密之外,接口也会进行加密,这个看需求来。内容加密之后即使被你抓到了数据包也没关系,看到的是一堆乱码,这种方式在涉及到敏感信息的传输时,会采用
通信加密
通信加密的过程是怎么实现的呢?http本身没有加密机制,它可以和SSL(安全套接层)组合起来一起使用,SSL是提供了加密处理的,它可以加密http的通信内容, 利用SSL建立安全通道,http就可以在这条通道里面安全的通信,这种组合就是https。
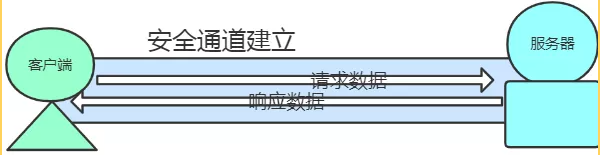
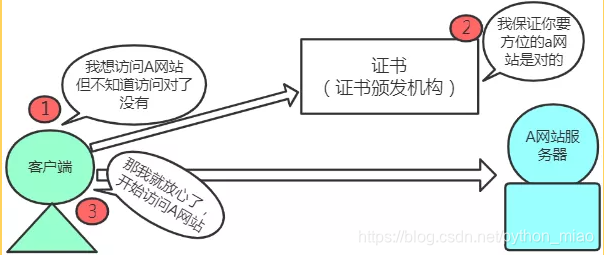
https之所以更加安全,是因为SSL不仅提供了加密的处理,同时还使用了证书来验证对方,这种证书是由可信赖的三方机构颁发的,它可以证明双方实际存在,而不是伪造的。
使用了证书之后,客户端的身份可以得到确认,服务端的身份也可以得到认证,就可以减少信息的泄露。有人可能会想到,证书要是被伪造了那咋办?这种可能性太低了,技术难度很大,所以可以放心。
内容的加密
另一种加密的方式内容的加密。http本身没加密机制,所以就会对传输的内容进行加密,加密之后再进行请求的发送。这里就引发出了一个问题,传输之前对内容进行了加密,服务器那边怎么去解密呢,所以它们之间要协商好加解密的方式。一般比较常见的是md5的方式,或者再加盐的方式都可以.内容加密这块在使用的时候,也要根据公司的业务需求来确定。
http和https的安全性对比,它们之间的区别和由来就是这些,如果要对https中的证书颁发过程做深入探讨,就要去学习互联网上常见的加解密方式了。当然在下一节也会对它进行探讨。
网络数据剖析
网络在开发中是至关重要的,很多人在写爬虫的时候,根本不知道抓包工具里面的数据包中字段的意思。网络的知识点很多,这章咱们暂且针对它的请求和传输做一个深入探讨。
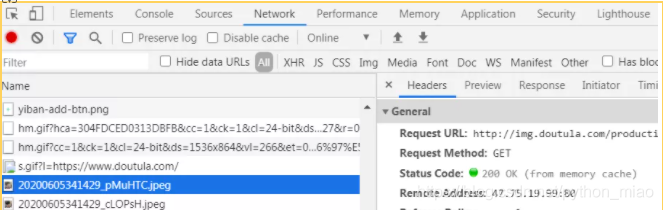
先来看一个url地址:https://image.baidu.com/,打开抓包工具, 里面有一段请求的报文。分析这段报文,报文里面有请求行和各种首部字段。
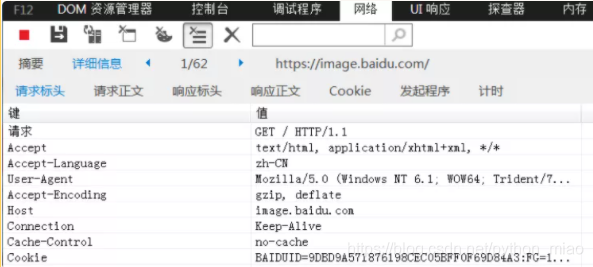
请求行里面可以看到,是get请求,协议用的是http/1.1的协议 先简单来啰嗦一个基本的问题,这是url地址的格式组成。协议://主机地址/路劲https是协议,image.baidu.com这是主机地址,也是域名。后面是接路径,路径后面接参数,有些url地址很多人看不懂路径后面那些符号是啥意思。
其他的参数
url分析完之后,请求报文中这些字段分别代表的含义,会通过请求发送给其它服务器
1.accept 客户端可以处理的类型
2.accept-language 优先支持中文
3.User-Agent 浏览器的标识
4.Accept-Encoding 优先的压缩方式
5.Host 主机地址
6.connection 长连接
7.Cache-Control 缓存控制
8.cookie 服务器生成的cookie
复制代码通信过程
几个参数了解了之后,在发送请求的时候进行通信,计算机之间会做些什么事情呢。比如现在在文本框输入python,当我点搜索发送起请求的时候,界面上很快就给你呈现出了你要的东西,我们来对它进行解释。

说到这里就要提到TCP/IP, TCP/IP是协议族按层来划分,分为应用层,传输层,网络层,数据链路层。
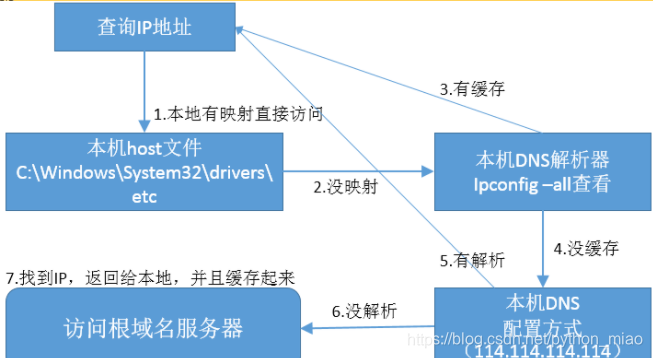
首先会通过这个域名,会向本地的DNS服务器去获取ip地址,本地的DNS地址可以通过指令ipconfig -all来查询。也可以到你自己电脑,找到本地的hosts文件。
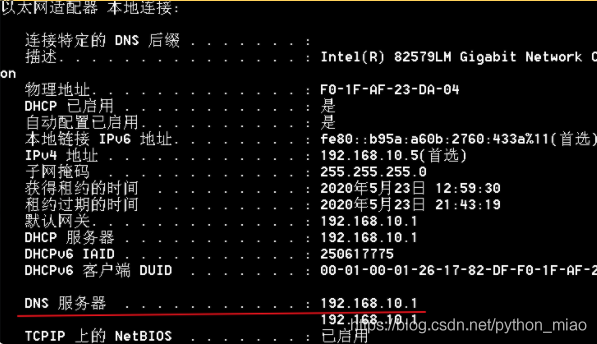
最初的互联网是整体的管理一份数据库文件hosts,这份文件里面有域名和IP地址的对应。只要新增一台,就要对这文件进行更新,很麻烦。所以搞了个系统来管理,就是DNS系统。
它在查询IP的时候,先到本地的DNS服务器查找,查不到再去根域名服务器查找。从这里也可以看出,有些黑客想对你电脑做些坏事,对DNS进行一些攻击或者做些欺骗手段,你所访问的网站都是他给你安排的。
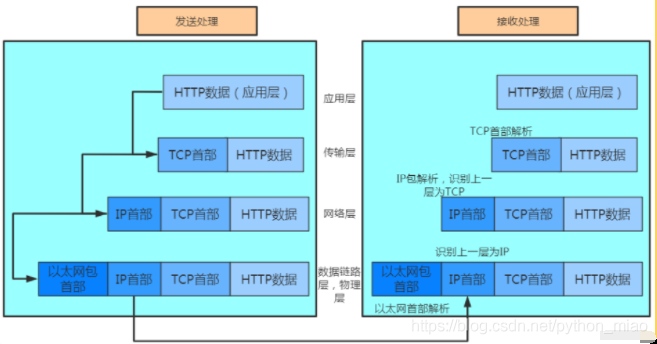
拿到了IP地址之后,同时会对我们输入的python字符串进行编码,这个处理过程在应用层这块,其中http协议, DNS也属于这一层,它会把请求报文里面的首部字段携带一起进行发送,在应用层做完这些事情之后,会进行下一层的转发。

应用层处理完毕之后,来到传输层,传输层包含TCP, UDP等. 会在之前的应用层数据前给它添加TCP首部,添加完之后发送给IP。TCP首部里面包含了源端口号和目标端口号,主要是用于识别发送主机和接口主机。以及确定发送几个字节的序号,和校验。TCP主要干的事情,是将HTTP请求报文分割成报文段,按序号传出去。

接着来到网络层这块,IP也基于前面传过来的数据,添加自己的IP首部。IP首部里面包含了接收端的IP地址和发送端的IP地址,还有一个重要的信息就是用来判断TCP和UDP的数据。生成之后就发送给网络接口的驱动程序。发送到具体的接收方,还要知道接收方的Mac地址。

最后在链路层添加以太网的首部,里面包含了Mac地址以及类型的协议。
在这里建立连接之后,会有TCP的三次握手。IP协议起的作用,就是一边搜地址,一边转一边传报文段。同时TCP也会对接收的报文段按序列进行重组。这就是数据传输的整个过程。
知识无边界,同学们根据自身的工作和学习情况合理安排时间。找到自己的薄弱点,对症学习,掌握好方式方法,可以在短期内看到效果。不过学习还是一个长期积累的过程,切勿好高骛远,循序渐进才是长久之计。
这里还是要推荐下阿喵建的Python学习群:609616831,群里都是学Python的,如果你想学或者正在学习Python ,欢迎你加入,大家都是软件开发党,不定期分享干货(只有Python软件开发相关的),包括我自己整理的一份2020最新的Python进阶资料和零基础教学,欢迎进阶中和对Python感兴趣的小伙伴加入!















 1441
1441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









