







本人是编程小白,同时也是一名准毕业研究生,在处理众多数据时总是要花很多时间来做重复的工作以提取出需要的数据,让我十分头疼。我无法忍受这种低效的工作,于是便开始尝试使用Python进行编程来批量处理数据。我把我编程之路上的历程写下来有三个目的:(1)为了发泄初次使用编程成功解决科研工作中问题的兴奋感(2)记录我在这个过程中遇到的问题和解决问题的方法(3)警示我以后在面对问题时记得用编程来提高效率。接下来开始第一次分享我遇到的一个案例:
一、问题描述
通过模拟获得以下56组保存在txt中的数据,
每组数据中内容如下:
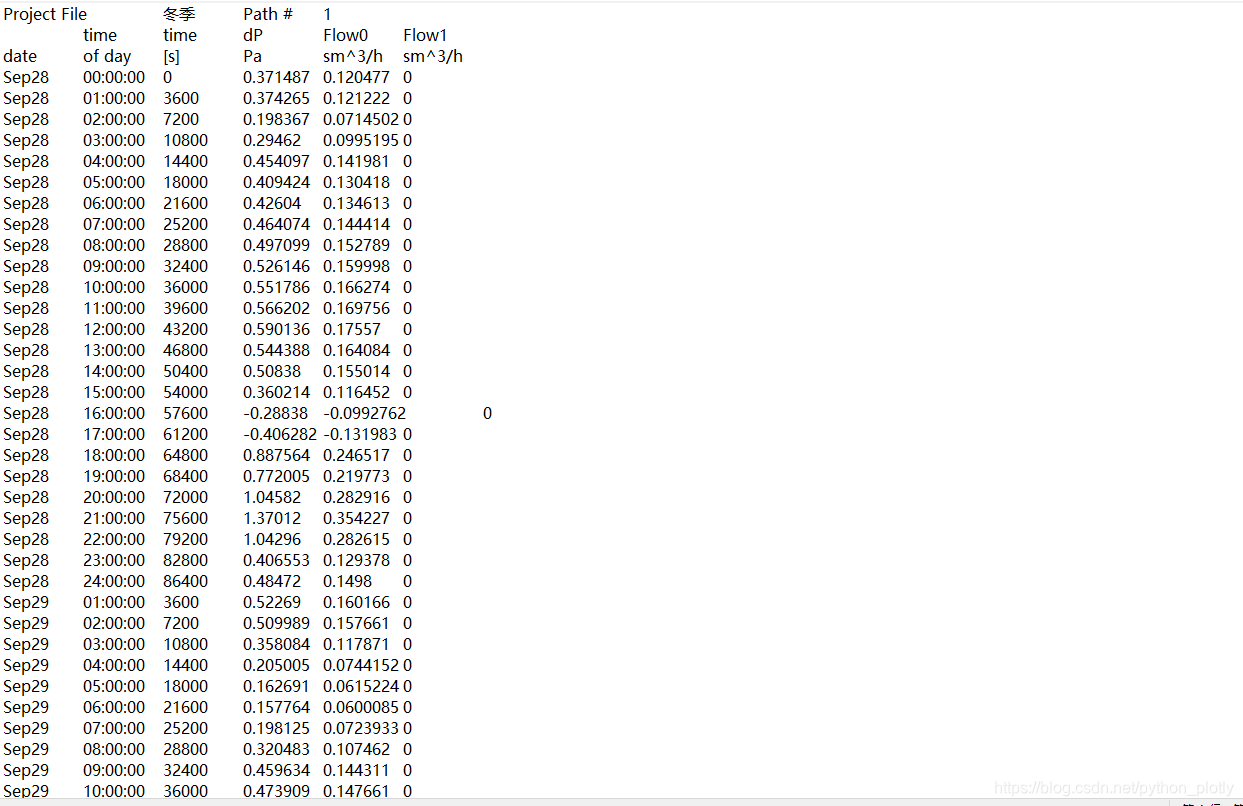
需要将每组数据中的第五列提取出来并保存在excel中以便分析
二、使用numpy读取txt数据
首先考虑如何读取单个txt中数据,这里使用numpy中loadtxt()函数,代码如下:
import numpy as np #引用numpy
array = np.loadtxt('1.txt',dtype=np.str,delimiter 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3111
3111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









