







利用python爬虫爬取网络小说保存到txt,熟悉利用python抓取文本数据的方法。
以爬取《伏天氏》这本小说的章节内容为例,目标url:http://www.xbiquge.la/0/951/
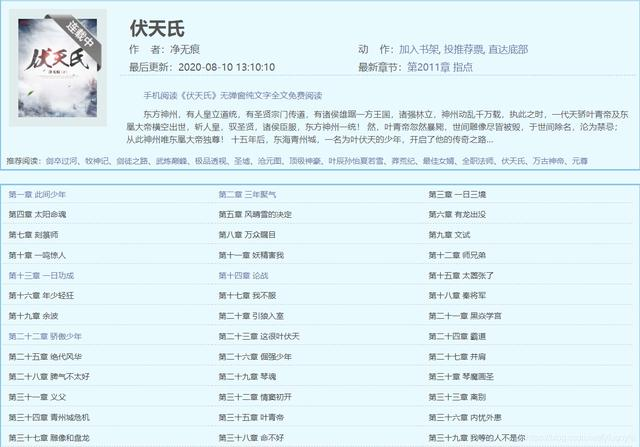
选取其中某一章,检查网页,可以找到这本小说所有章节的链接和名称。
写出xpath表达式提取出href里的内容://div[@id=“list”]/dl/dd/a/@href
分析网页可得,提取出来的内容里每个元素前面应加上 http://www.xbiquge.la 得到的才是是每个章节真正的链接
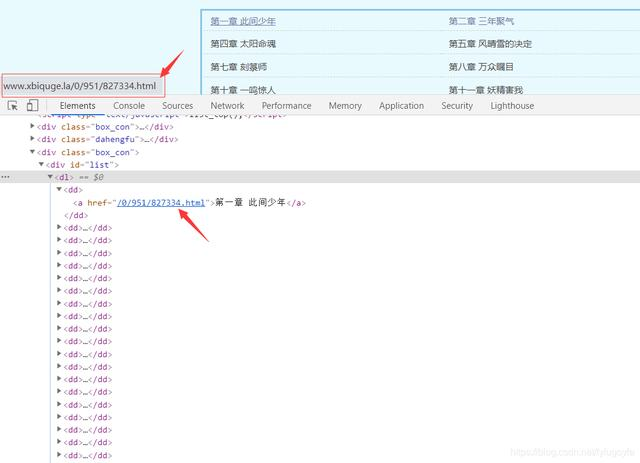
抓取所有章节的链接,代码如下:
def get_urls():
url = "http://www.xbiquge.la/0/951/"
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
html = etree.HTML(response.text)
# 所有章节的url列表
url_list = ['http://www.xbiquge.la' + x for x in html.xpath('//div[@id="list"]/dl/dd/a/@href')]
return url_list
12345678
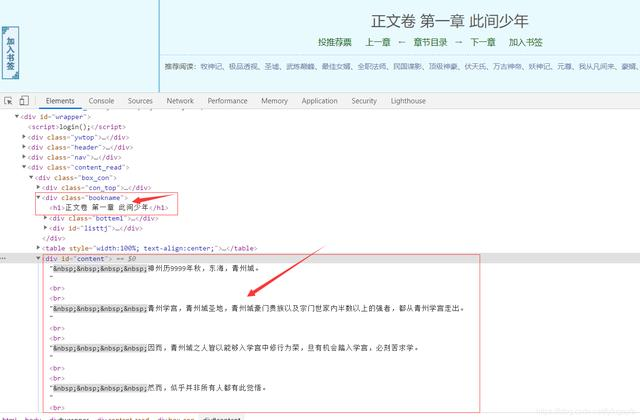
抓取每章的章节名称和内容保存到txt,代码如下:
def get_text(url):
rep = requests.get(url, headers=headers)
rep.encoding = 'utf-8'
dom = etree.HTML(rep.text)
name = dom.xpath('//div[@class="bookname"]/h1/text()')[0]
text = dom.xpath('//div[@id="content"]/text()')
with open(path + f'{name}.txt', 'w', encoding='utf-8') as f:
for con in text:
f.write(con)
print(f'{name} 下载完成')
12345678910
完整代码如下:
import requests
from lxml import etree
import time
import random
path = r'D:\test\伏天氏\ '
headers = {
"Referer": "http://www.xbiquge.la/0/951/",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1"
}
def get_urls():
url = "http://www.xbiquge.la/0/951/"
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
html = etree.HTML(response.text)
# 所有章节的url列表
url_list = ['http://www.xbiquge.la' + x for x in html.xpath('//div[@id="list"]/dl/dd/a/@href')]
return url_list
def get_text(url):
rep = requests.get(url, headers=headers)
rep.encoding = 'utf-8'
dom = etree.HTML(rep.text)
name = dom.xpath('//div[@class="bookname"]/h1/text()')[0]
text = dom.xpath('//div[@id="content"]/text()')
with open(path + f'{name}.txt', 'w', encoding='utf-8') as f:
for con in text:
f.write(con)
print(f'{name} 下载完成')
def main():
urls = get_urls()
for url in urls:
get_text(url)
time.sleep(random.randint(1, 3))
if __name__ == '__main__':
main()
运行效果如下:
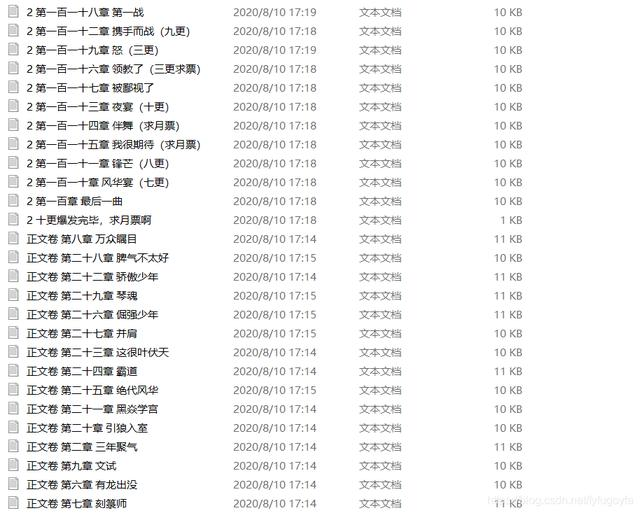
程序运行,小说保存到了txt里。
源码获取记得加群哦:1136192749
利用python爬虫爬取网络小说保存到txt,熟悉利用python抓取文本数据的方法。
以爬取《伏天氏》这本小说的章节内容为例,目标url:http://www.xbiquge.la/0/951/
选取其中某一章,检查网页,可以找到这本小说所有章节的链接和名称。
写出xpath表达式提取出href里的内容://div[@id=“list”]/dl/dd/a/@href
分析网页可得,提取出来的内容里每个元素前面应加上 http://www.xbiquge.la 得到的才是是每个章节真正的链接
抓取所有章节的链接,代码如下:
def get_urls():
url = "http://www.xbiquge.la/0/951/"
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
html = etree.HTML(response.text)
# 所有章节的url列表
url_list = ['http://www.xbiquge.la' + x for x in html.xpath('//div[@id="list"]/dl/dd/a/@href')]
return url_list
12345678
抓取每章的章节名称和内容保存到txt,代码如下:
def get_text(url):
rep = requests.get(url, headers=headers)
rep.encoding = 'utf-8'
dom = etree.HTML(rep.text)
name = dom.xpath('//div[@class="bookname"]/h1/text()')[0]
text = dom.xpath('//div[@id="content"]/text()')
with open(path + f'{name}.txt', 'w', encoding='utf-8') as f:
for con in text:
f.write(con)
print(f'{name} 下载完成')
12345678910
完整代码如下:
import requests
from lxml import etree
import time
import random
path = r'D:\test\伏天氏\ '
headers = {
"Referer": "http://www.xbiquge.la/0/951/",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1"
}
def get_urls():
url = "http://www.xbiquge.la/0/951/"
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
html = etree.HTML(response.text)
# 所有章节的url列表
url_list = ['http://www.xbiquge.la' + x for x in html.xpath('//div[@id="list"]/dl/dd/a/@href')]
return url_list
def get_text(url):
rep = requests.get(url, headers=headers)
rep.encoding = 'utf-8'
dom = etree.HTML(rep.text)
name = dom.xpath('//div[@class="bookname"]/h1/text()')[0]
text = dom.xpath('//div[@id="content"]/text()')
with open(path + f'{name}.txt', 'w', encoding='utf-8') as f:
for con in text:
f.write(con)
print(f'{name} 下载完成')
def main():
urls = get_urls()
for url in urls:
get_text(url)
time.sleep(random.randint(1, 3))
if __name__ == '__main__':
main()
运行效果如下:
程序运行,小说保存到了txt里。
源码获取记得点击源码


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









