







本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理
原创:TrueDei
想要获取更多Python学习资料了解更多关于Python的知识可以加Q群630390733踊跃发言大家一起来学习讨论吧!
由一个家长退群的故事在某博上了热搜。故事中老师和家长的矛盾由批改作业集中爆发,至于孰是孰非,还是交给吃瓜群众去评价吧,作为一个技术工作者,我突发奇想,是否以后能让机器来辅助老师批改作业呢?这仿佛是个维护世界和平的点子!

经过一阵调(搜)研(索),在英语作文批改上,还真的有一些成熟的方案可以使用,而且学习成本相当之低,比如有道智云的英语作文批改服务,只需阅读文档按规则开发应用,即可得到详尽的批改结果,作文可以是图片,也可以是文字,等级可以从小学一直到雅思托福,覆盖范围极广。
怀着激动的心情,我快速地开发了一个简单的 demo,下面分享一下开发过程。
调用 API 接口的准备工作
首先,是需要在有道智云的个人页面上创建实例、创建应用、绑定应用和实例,获取到应用的 id 和密钥。具体个人注册的过程和应用创建过程详见文章 分享一次批量文件翻译的开发过程
这里要特别说明一下,作文批改分为图像和文本两种形式,分别调用了不同的 api,因此需要创建两个实例。

开发过程详细介绍 下面介绍具体的代码开发过程。
英语作文批改分为两个 API,分别对应图像识别和文本输入两种形式的作文。调用方式大同小异,都是将待批改内容和时间戳等信息生成的签名 post 到 API 接口,而后接口返回批改结果。
图像识别 API 输入所需参数如下表:

文本输入 API 输入参数如下表:
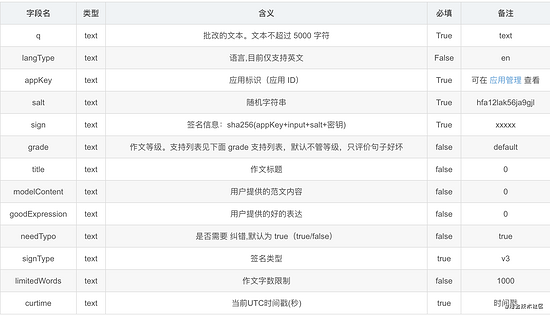
- 最好传输 limitedWords,这样评分更精确。
- 签名生成算法如下:
signType=v3,sha256(应用 ID+input+salt+curtime + 密钥),推荐使用 sha256 签名计算方法为:sha256(应用 ID+input+salt + 当前 UTC 时间戳 + 密钥)。
其中,input 的计算方式为:input=多个q拼接后前10个字符 + 多个q拼接长度 + 多个q拼接后十个字符(当多个 q 拼接后长度大于 20)或 input=多个q拼接的字符串(当多个 q 拼接后长度小于等于 20)。
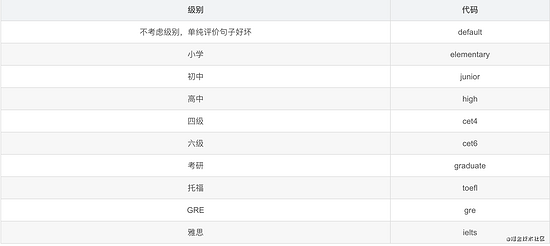
在接口输入参数中,grade 为以下几类:
Demo开发:
这个demo使用python3开发,包括maindow.py,correctclass.py,HomeworkCorrect.py 三个文件,分别为demo的界面、界面逻辑处理和英文作文批改接口调用方法的封装
HomeworkCorrect.py 三个文件,分别为 demo 的界面、界面逻辑处理和英文作文批改接口调用方法的封装。
1、界面部分: UI 部分较简单,主要功能为选择待批改作文文件、选择批改结果存储路径、选择批改类型。其布局代码如下:
root=tk.Tk()
root.title(" youdao correct writing test")
frm = tk.Frame(root)
frm.grid(padx='50', pady='50')
btn_get_file = tk.Button(frm, text='选择待批改的作业(图片或文本)', command=get_files)
btn_get_file.grid(row=0, column=0, ipadx='3', ipady='3', padx='10', pady='20')
text1 = tk.Text(frm, width='40', height='10')
text1.grid(row=0, column=1)
btn_get_result_path=tk.Button(frm,text='选择批改结果存放路径',command=set_result_path)
btn_get_result_path.grid(row=1,column=0)
text2=tk.Text(frm,width='40', height='2')
text2.grid(row=1,column=1)
label=tk.Label(frm,text='选择年级:')
label.grid(row=3,column=0)
combox=ttk.Combobox(frm,textvariable=tk.StringVar(),width=38)
combox["value"]=select_type_dict
combox.current(0)
combox.bind("<<ComboboxSelected>>",get_grade_type)
combox.grid(row=3,column=1)
btn_sure=tk.Button(frm,text="批改",command=correct_files)
btn_sure.grid(row=4,column=1)
root.mainloop()
复制代码
其中启动按钮 btn_sure 的绑定事件 correct_files() 来启动批改,并在完成后打开结果存储路径:
def correct_files():
correct.start_correct()
os.system('start '+correct.result_path)
correctclass.py
复制代码
这里主要配合 UI 的逻辑,分析文件类型,选取合适的接口来批改作文。
首先定义一个类 Correct:
2、class Correct():
def __init__(self,file_paths,grade,result_path):
self.file_paths=file_paths
self.grade =grade
self.result_path=result_path
复制代码
get_correct_result() 方法根据文件类型判断应调用的封装方法,并处理返回值,将批改结果存入文件系统。
def get_correct_result(self,file_path):
file_type=file_path.split(".")[1]
if file_type=="txt":
print(file_path)
result=connect_context(file_path,self.grade)
self.save_result(file_path,result)
elif file_type=="png" or file_type=="jpg" or file_type=="jepg" :
result=connect_pic(file_path,self.grade)
self.save_result(file_path,result)
复制代码
save_result() 方法实现了保存结果的功能:
def save_result(self,file_path,result):
result_file_name=os.path.basename(file_path).split('.')[0]+'_result.txt'
f=open(self.result_path+'/'+result_file_name,'w')
f.write(str(result))
f.close()
复制代码
HomeworkCorrect.py HomeworkCorrect.py 中封装了请求两种作业批改 API 的方法,两个 API 主要区别在于 URL 和 APP 示例的不同。最核心的方法分别是 connect_pic() 和 connect_context()
connect_pic():
def connect_pic(pic_path,grade):
f = open(pic_path, 'rb')
q = base64.b64encode(f.read())
f.close()
data = {}
curtime = str(int(time.time()))
data['curtime'] = curtime
salt = str(uuid.uuid1())
signStr = APP_KEY + truncate(q) + salt + curtime + APP_SECRET
sign = encrypt(signStr)
data['appKey'] = APP_KEY
data['salt'] = salt
data['q'] = q
data['sign'] = sign
data['grade'] = grade
data['signType'] = 'v3'
response = do_request(data,YOUDAO_URL_IMAGE)
result=json.loads(str(response.content,'utf-8'))['Result']
return result
复制代码
connect_context():
def connect_context(file_path,grade):
f=open(file_path,'rb')
q=f.read()
f.close()
data = {}
curtime = str(int(time.time()))
data['curtime'] = curtime
salt = str(uuid.uuid1())
signStr = APP_KEY + truncate(q) + salt + curtime + APP_SECRET
sign = encrypt(signStr)
data['appKey'] = APP_KEY
data['q'] = q
data['salt'] = salt
data['sign'] = sign
data['signType'] = "v3"
data['grade'] = grade
response = do_request(data,YOUDAO_URL_TEXT)
print(response.content)
result = json.loads(str(response.content, 'utf-8'))['Result']
print(result)
return result
复制代码
响应结果说明:
{
"errorCode": "错误码",
"Result": {
"uniqueKey": "每个请求独一无二的字符串标识",
"essayLangName": "语言信息",
"rawEssay": "请求原文",
"refEssay": "参考范文",
"stLevel": "作文级别",
"reqSource": "请求来源",
"extraParams": "额外请求参数(扩展用参数)",
"wordNum": "文章总词数"
"conjWordNum": "文章连接词数",
"AllFeatureAdvice": {
"WordNum": "词数建议,如文章字数疑似超出该考试字数要求",
"Spelling": "拼写错误建议",
"WordDiversity": "词汇丰富度建议,如词汇量积累非常少,只能给出一些零散的简单词汇,建议多积累词汇",
"Structure": "文章结构建议",
"AdvanceVocab": [
"xx", "xx", "xx"
],
"AdvanceVocabLeval": [0, 1, 2],
"lexicalSubs": [
{"candidates": ["xx", "xx"], "count": 频率, "word": xx 对应词}, ...
]
"Conjunction": [{
"used": ["xx", "xx", "xx"]
"advice": ["xx", "xx", "xx"]
}],
"Topic": "主题相关性建议",
"Grammar": "语法相关建议",
"GoodExpression": ["xx", "xx", "xx"]
},
"AllFeatureScore": {
"NeuralScore": 68.64,
"WordNum": 10,
"Spelling": 10,
"WordDiversity": 0,
"Structure": 8,
"AdvanceVocab": 7.61,
"Conjunction": 6.94,
"Topic": 6.03,
"Grammar": 2.5
"SentComplex": 10
},
"majorScore": {
"WordScore": 10,
"GrammarScore": 10,
"StructureScore": 10,
"topicScore": 10,
},
"essayFeedback":{
"sentsFeedback": [
{
"sentId": "句子在全文的编号,从0开始",
"paraId": "该句所在的段落号,从0开始",
"rawSent": "原句",
"segSent": "原句分词后的结果",
"correctedSent": "原句修正后的结果",
"sentStartPos": "该句子在全文中相对于文章初始位置的偏移量",
"errorPosInfos": [
{
"type": "错误类型(包括`grammar`,`typo`,`refactor`)",
"startPos": "错误起始位置相对rawSent起始位置的偏移量",
"endPos": "错误结束位置相对rawSent起始位置的偏移量",
"orgChunk": "错误块的具体内容",
"correctChunk": "错误块修正后的具体内容",
"error_type": "(弃用) 错误的具体类别(0表示拼写错误,1表示冠词错误,2表示动词时态或者第三人称单复数错误,3表示名词单复数错误,4表示格错误,5表示介词错误,6表示其他语法错误,7表示文本格式错误,8表示正确)",
"new_error_type": "错误类别(0表示完全正确,
1表示书写格式不规范,2表示拼写错误,
3表示标点错误,4表示冠词错误,5表示动词错误,
6表示名词单复数错误,7表示代词错误,8表示介词错误,
9表示形容词错误,10表示副词错误,11表示连词错误,
20表示其他错误,21表示代指所有语法错误(兼容))"
"new_sub_error_type": "细分错误类别(0表示正确,1表示未知错误,2表示词汇缺失,3表示词汇冗余,
4表示冠词误用,5表示介词误用,6表示动词主谓一致错误,7表示动词时态错误,8表示情态动词后应接动词原形错误,
9表示被动语态错误,10表示动词不定式错误,11表示动词错误,12表示形容词比较级错误,
13表示形容词最高级错误,14表示副词比较级错误,15表示副词最高级错误,16表示名词单复数错误,
17表示名词错误,18表示人称代词主宾格混淆,19表示人称代词和物主代词混淆,20表示形容词性和名词性代词混淆,
21表示人称代词和反身代词混淆,22表示疑问/关系/连接代词混淆,23表示指示代词混淆,24表示不定代词混淆,
25表示代词错误,26表示标点符号误用,27表示拼写错误,28表示不规范错误)"
"举例说明": 如果new_error_type=5, new_sub_error_type=2,说明是动词缺失
"reason": "错误的具体原因",
"isValidLangChunk": "类似下面的isValidSent,判断是否为合法片段(该片段如果语言检测结果与期望不一致,则认为不合法)"
"analysis": "错误的原因的具体辨析(保留接口,暂时应该没用)"
}, ..., {}
],
"isValidLangSent": "是否为合法句子(合法与否取决于语言检测对该句的语言信息识别结果与期望结果是否一致)"
"sentFeedback": "错误原因反馈,基于errorPosInfos中所有reason字段拼接而成",
"isContainTypoError": "返回是否含有typo错误",
"isContainGrammarError": "返回是否含有语法错误",
"sentScore": "句子得分(暂时没有用,即将实现)"
}
]
}
"totalScore": "文章最终得分"
"fullScore": "对应级别满分"
"essayAdvice": "文章最终评价"
"paraNum": "文章段落数"
"sentNum": "文章句子数"
}
}
复制代码
总结 有道智云的英语作文批改 API 文档清晰,功能全面,可针对不同类型文件、不同难度的作文进行多维度批改,评价指标明确,批改结果非常具有参考价值,赞!
相信在未来,会有更多类型的作业批改服务出现吧,到那时,老师和家长们就都能得到解放了…















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









