







背景
在Mesos和YARN中,都用到了dominant resource fairness算法(DRF),它不同于Hadoop基于slot-based实现的fair scheduler和capacity scheduler,论文阅读:Dominant Resource Fairness: Fair Allocation of Multiple Resource Types。
考虑在一个包括多种资源类型(主要考虑CPU和MEM)的系统的公平资源分配问题,其中不同用户对资源有不同的需求。为了解决这个问题,伯克利的几位大牛提出了Dominant Resource Fairness(DRF),一种针对不同资源类型的max-min fairness。并且在Mesos的设计和实现中评估了DRF,显示了它可以比slot-based 公平调度算法得到更好的吞吐量。
介绍
在任何共享的计算机系统中,资源分配都是一个关键的构建模块。已经提出的最通用的分配策略是max-min fairness,这种策略会最大化系统中一个用户收到的最小分配。假设每一个用户都有足够地请求,这种策略会给予每个用户一份均等的资源。广义的Max-min fairness包括权重(weight)的概念,用户可以获得与它的权重成正比的那一份资源。
加权max-min fairness的吸引力源于它的一般性和它能提供性能隔离的能力。加权max-min fairness模型可以支撑许多其他资源分配策略,包括优先级、deadline based allocation等。此外,加权max-min fairness确保隔离,一个用户能确保收到它的那份资源,而不管其它用户的需求。
鉴于这些特征,不同精确度的加权或非加权max-min fairness毫不意外地被大量已经提出的算法实现,如round-robin、proportional resource sharing、weighted fair queueing。这些算法已经被应用于不同的资源,包括链路带宽、CPU、内存、存储。
尽管已经在公平分配上做了大量地工作和实践,但目前为止主要还是集中在单资源类型的场景下。甚至在多资源类型的环境下,用户有异质资源请求,典型的资源分配做法还是使用单类型资源抽象。比如hadoop和Dryad的公平调度器,这两种广泛使用集群计算框架,在资源分配时使用插槽(slot),slot就是对节点资源按照固定大小进行划分而产生的分区。然而事实是集群中不同的作业队CPU、内存和IO资源有着不同的需求。
加权max-min fairness的吸引力源于它的一般性和它能提供性能隔离的能力。加权max-min fairness模型可以支撑许多其他资源分配策略,包括优先级、deadline based allocation等。此外,加权max-min fairness确保隔离,一个用户能确保收到它的那份资源,而不管其它用户的需求。
鉴于这些特征,不同精确度的加权或非加权max-min fairness毫不意外地被大量已经提出的算法实现,如round-robin、proportional resource sharing、weighted fair queueing。这些算法已经被应用于不同的资源,包括链路带宽、CPU、内存、存储。
尽管已经在公平分配上做了大量地工作和实践,但目前为止主要还是集中在单资源类型的场景下。甚至在多资源类型的环境下,用户有异质资源请求,典型的资源分配做法还是使用单类型资源抽象。比如hadoop和Dryad的公平调度器,这两种广泛使用集群计算框架,在资源分配时使用插槽(slot),slot就是对节点资源按照固定大小进行划分而产生的分区。然而事实是集群中不同的作业队CPU、内存和IO资源有着不同的需求。
特性
DRF是一种通用的多资源的max-min fairness分配策略。DRF背后的直观想法是在多环境下一个用户的资源分配应该由用户的dominant share(主导份额的资源)决定,
dominant share是在所有已经分配给用户的多种资源中,占据总资源(包括已经分配出去的)最大份额的一种资源。简而言之,DRF试图
最大化所有用户中最小的dominant share。
举个例子,假如用户A运行CPU密集的任务而用户B运行内存密集的任务,DRF会试图均衡用户A的CPU资源份额和用户B的内存资源份额。在单个资源的情形下,那么DRF就会退化为max-min fairness。
DRF有四种主要特性,分别是:sharing incentive、strategy-proofness、Pareto efficiency和envy-freeness。
DRF是通过确保系统的资源在用户之间是静态和均衡地进行分配来提供sharing incentive,用户不能获得比其他用户更多的资源。此外,DRF是strategy-proof,用户不能通过谎报其资源需求来获得更多的资源。DRF是Pareto-efficient,在满足其他特性的同时,分配所有可以利用的资源,不用取代现有的资源分配。最后,DRF是envy-free,用户不会更喜欢其他用户的资源分配。
举个例子,假如用户A运行CPU密集的任务而用户B运行内存密集的任务,DRF会试图均衡用户A的CPU资源份额和用户B的内存资源份额。在单个资源的情形下,那么DRF就会退化为max-min fairness。
DRF有四种主要特性,分别是:sharing incentive、strategy-proofness、Pareto efficiency和envy-freeness。
DRF是通过确保系统的资源在用户之间是静态和均衡地进行分配来提供sharing incentive,用户不能获得比其他用户更多的资源。此外,DRF是strategy-proof,用户不能通过谎报其资源需求来获得更多的资源。DRF是Pareto-efficient,在满足其他特性的同时,分配所有可以利用的资源,不用取代现有的资源分配。最后,DRF是envy-free,用户不会更喜欢其他用户的资源分配。
最大最小算法
在解释DRF的计算方式之前,了解一下max-min算法的公平分配策略会更有帮助。例子来源于
http://hi.baidu.com/dd_hz/item/4a0b75e970afcfcebbf37d8d这篇文章
不加权
有一四个用户的集合,资源需求分别是2,2.6,4,5,其资源总能力为10,为其计算最大最小公平分配
解决方法:
我们通过几轮的计算来计算最大最小公平分配.
第一轮,我们暂时将资源划分成4个大小为2.5的.由于这超过了用户1的需求,这使得剩了0.5个均匀的分配给剩下的3个人资源,给予他们每个2.66.这又超过了用户2的需求,所以我们拥有额外的0.066…来分配给剩下的两个用户,给予每个用户2.5+0.66…+0.033…=2.7.因此公平分配是:用户1得到2,用户2得到2.6,用户3和用户4每个都得到2.7.
解决方法:
我们通过几轮的计算来计算最大最小公平分配.
第一轮,我们暂时将资源划分成4个大小为2.5的.由于这超过了用户1的需求,这使得剩了0.5个均匀的分配给剩下的3个人资源,给予他们每个2.66.这又超过了用户2的需求,所以我们拥有额外的0.066…来分配给剩下的两个用户,给予每个用户2.5+0.66…+0.033…=2.7.因此公平分配是:用户1得到2,用户2得到2.6,用户3和用户4每个都得到2.7.
加权
有一四个用户的集合,资源需求分别是4,2,10,4,权重分别是2.5,4,0.5,1,资源总能力是16,为其计算最大最小公平分配.
解决方法:
第一步是标准化权重,将最小的权重设置为1.这样权重集合更新为5,8,1,2.这样我们就假装需要的资源不是4份而是5+8+1+2=16份.因此将资源划分成16份.在资源分配的每一轮,我们按照权重的比例来划分资源,因此,在第一轮,我们计算c/n为16/16=1.在这一轮,用户分别获得5,8,1,2单元的资源,用户1得到了5个资源,但是只需要4,所以多了1个资源,同样的,用户2多了6个资源.用户3和用户4拖欠了,因为他们的配额低于需求.现在我们有7个单元的资源可以分配给用户3和用户4.他们的权重分别是1和2,最小的权重是1,因此不需要对权重进行标准化.给予用户3额外的7 × 1/3单元资源和用户4额外的7 × 2/3单元.这会导致用户4的配额达到了2 + 7 × 2/3 = 6.666,超过了需求.所以我们将额外的2.666单元给用户3,最终获得1 + 7/3 + 2.666 = 6单元.最终的分配是,4,2,6,4,这就是带权的最大最小公平分配.
解决方法:
第一步是标准化权重,将最小的权重设置为1.这样权重集合更新为5,8,1,2.这样我们就假装需要的资源不是4份而是5+8+1+2=16份.因此将资源划分成16份.在资源分配的每一轮,我们按照权重的比例来划分资源,因此,在第一轮,我们计算c/n为16/16=1.在这一轮,用户分别获得5,8,1,2单元的资源,用户1得到了5个资源,但是只需要4,所以多了1个资源,同样的,用户2多了6个资源.用户3和用户4拖欠了,因为他们的配额低于需求.现在我们有7个单元的资源可以分配给用户3和用户4.他们的权重分别是1和2,最小的权重是1,因此不需要对权重进行标准化.给予用户3额外的7 × 1/3单元资源和用户4额外的7 × 2/3单元.这会导致用户4的配额达到了2 + 7 × 2/3 = 6.666,超过了需求.所以我们将额外的2.666单元给用户3,最终获得1 + 7/3 + 2.666 = 6单元.最终的分配是,4,2,6,4,这就是带权的最大最小公平分配.
DRF计算方式
考虑一个有9个cpu和18GB的系统,有两个用户:用户A的每个任务都请求(1CPU,4GB)资源;用户B的每个任务都请求(3CPU,4GB)资源。如何为这种情况构建一个公平分配策略?

通过列不等式方程可以解得给用户A分配3份资源,用户B分配2份资源是一个很好的选择。DRF的算法伪代码为:

使用DRF的思路,分配的过程如下表所示,注意,每一次选择为哪个资源分配的决定,取决于上次分配之后,
目前dominant share最小的那个用户可以得到下一次的资源分配。
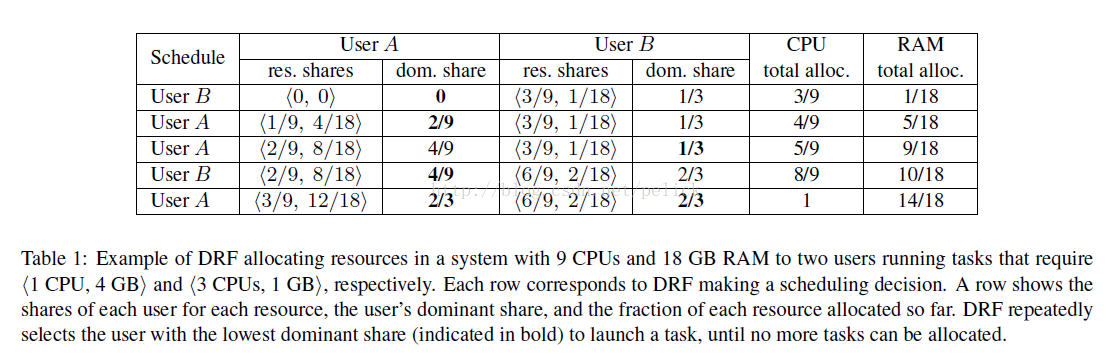
在这个例子中,用户A的CPU占总CPU 1/9,MEM占总MEM的 2/9,而用户B的CPU占1/3,MEM占2/9,所以A的主资源为内存,B的主资源为CPU。基于这点,DRF会最大化A的内存的最小化分配,并会最大化B的CPU的最小分配。
Weighted DRF换算方式
带权重的情况下,每个用户的dominant share不再是那个占用总资源百分比最大的那位资源,而是定义为Si = max{Ui,j / Wi,j},即那份占总权重最大的资源作为dominant share,代替上述例子中的dominant share进行运算。
YARN DRF实现
最后附上hadoop 2.0里YARN的server-resourcemanager模块里,Fair Scheduler里实现的DRF策略的代码(YARN的Scheduler主要实现的是Capacity和Fair,DRF是Fair里的一种,此外还有FIFO、Fair Share)。
总结
本文介绍了DRF算法的背景和特性,并对比最大最小算法,介绍了DRF带权和不带权情况下的资源分配方式。DRF的核心就是最大化所有用户中最小的dominant share,而dominant share在带权和不带权的情况下有不同的计算方式,其实计算都很简单,通过YARN实现的代码也能体现。
希望通过本文的介绍,能让读者了解DRF算法的重要性,其与max-min在思路上的继承和优化,并能从YARN和Mesos的实际代码模块中,获得实现思路。















 3766
3766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









