





原标题:python爬虫超简单攻略,带你写入门级的爬虫,抓取上万条信息
最近经常有人问我,明明看着教程写个爬虫很简单,但是自己上手的时候就麻爪了。。。那么今天就给刚开始学习爬虫的同学,分享一下怎么一步一步写爬虫,直至抓到数据的过程。
准备工具
首先是工具的准备:python3.6、pycharm、requests库、lxml库以及火狐浏览器
这2个库都是python的第三方库,需要用pip安装一下!
requests是用于请求网页,得到网页的源代码,然后用lxml库分析html源码,从中间取出我们需要的内容!
之所以用火狐而不用其他的浏览器,没有别的意思,就是习惯。。。

分析网页
工具准备好以后呢,我们就可以开始我们的爬虫之旅了!今天我们的目标是抓取猫眼电影的经典影片部分,大约有8万多条数据
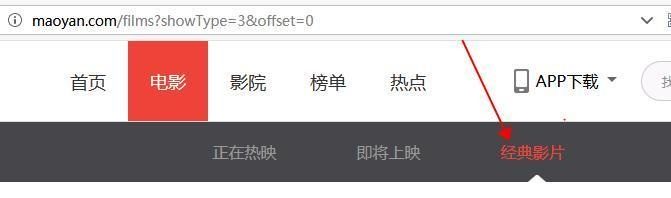
打开网页后,首先就要分析网页源代码,看是静态的还是动态的,或者其他形式,这个网页呢,是静态的网页,所以,源代码中就有我们需要的内容
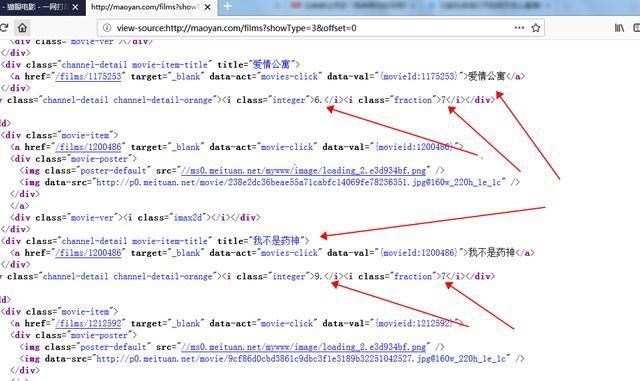
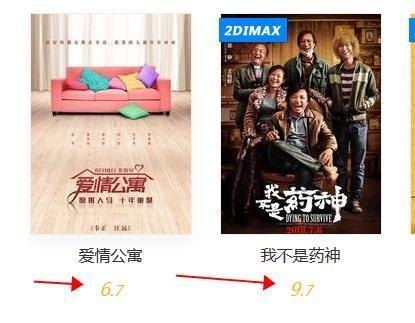
很明显,它的电影名字和评分都在源代码中,但是评分被分成了2部分,这点在写爬虫的时候,就要注意了!
那么,现在整体思路就很明确了:请求网页==>>获取html源代码==>>匹配内容,然后在外面在加一步:获取页码==>>构建所有页的循环,这样就可以将所有内容都抓出来了!下面外面来写代码吧。
开始写爬虫
先导入2个库,然后用一行代码获取网页html,在打印一下看看结果
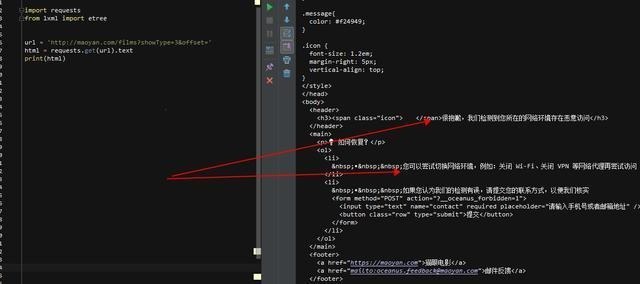
好吧,网站不允许爬虫运行!我们加入headers试一下(headers是一个身份证明,表明请求网页的是一个浏览器而不是python代码),获取方式也很简单,打开F12开发者工具,随便找一个网络请求,然后按下图找到请求头,复制相关信息即可,这个header可以保存下,基本一个浏览器都是一个UA,下次直接用就可以。
Welcome to join learning group: Six nine nine+seven Four nine+Eight Five Two ,群里都是学Python开发的,如果你正在学习Python ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有Python软件开发相关的),包括我自己整理的一份2018最新的Python进阶资料和高级开发教程,欢迎进阶中和进想深入Python的小伙伴 。
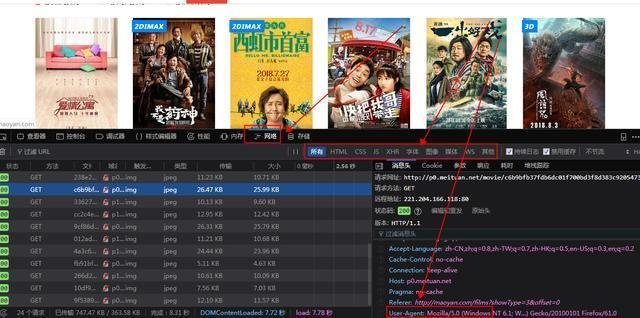
注意,在火狐中,header的数据如果很长是会缩写的,看到上图中间的省略号…了吗~所以在复制的时候,要先双击展开,在复制,然后修改上面的代码,在看看
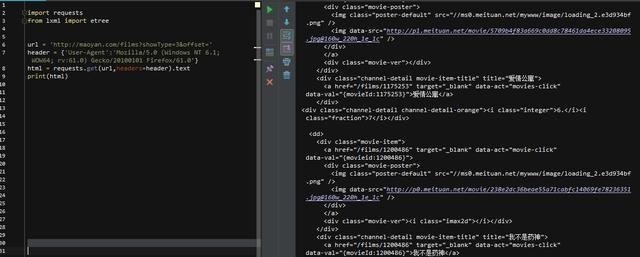
这次,html被正确的打印出来了!(后面的.text是获取html文本,如果不加,会返回是否获取成功的提示,而不是html源码),我们先构建页码的循环,找一下翻页的html代码
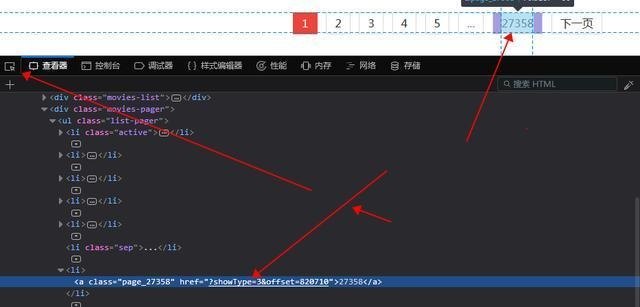
点击开发者工具中左上角的选择元素,然后在点击页码,下方会自动定位相应的源码位置,这里我们可以直观的看到最大页码,先取出它来,在其上点右键,选择复制Xpath,然后写到代码中
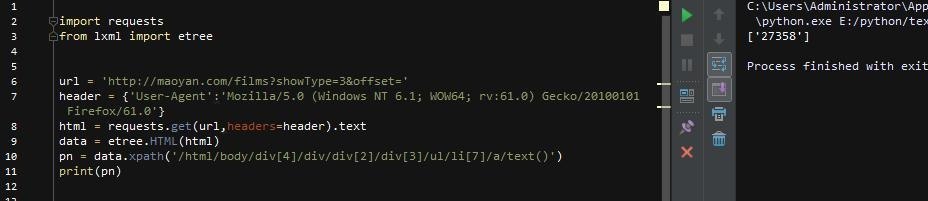
第9行是表达用lxml中的etree方法解析html,第10行是指从html中找到路径所对应的标签,因为页码是文字显示,是标签的文本部分,所以在路径最后加一个/text来取出文本,最终取出的内容为列表形式。然后我们在来观察每一页的url,还记得刚才那个页码部分的html吗?
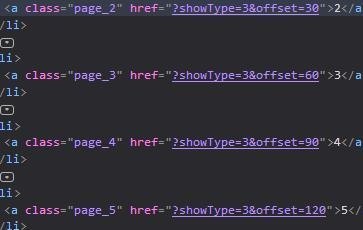
href的值就是每一个页码所对应的url,当然它省去了域名部分。可以看出啦,它的规律就是offset的值随着页码变化(*30)那么,我们就可以来构建循环了!
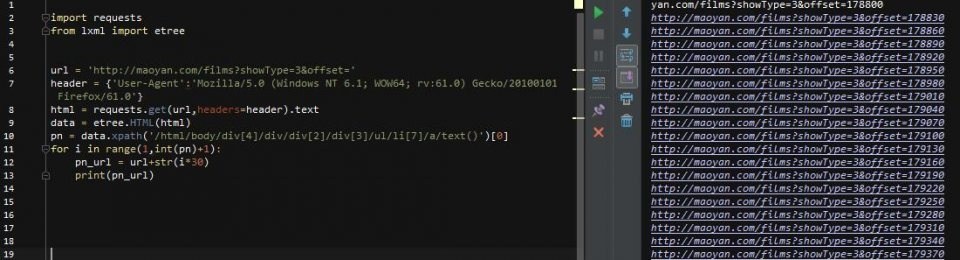
第10行用[0]取出列表中的pn值,然后构建循环,接着就是获取新的url(pn_url)的html,然后去html中匹配我们要的内容!为了方便,加一个break,这样只会循环一次
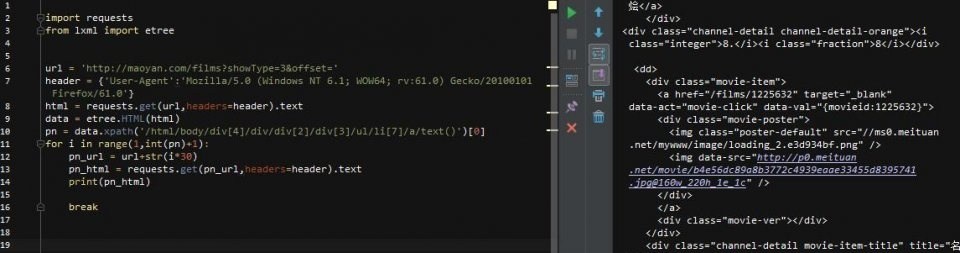
然后开始匹配,我们这次只拿出电影名称、评分和详情url3个结果
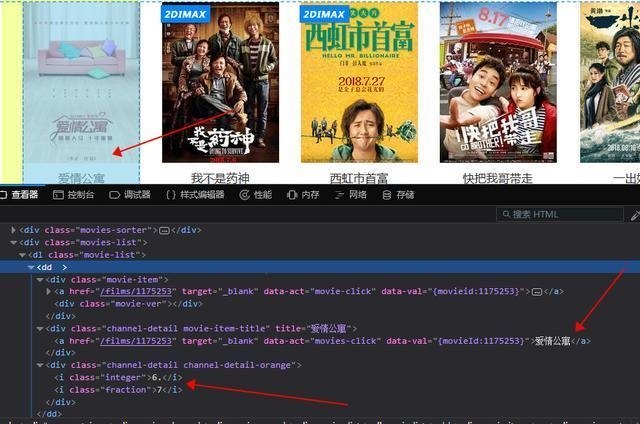
可以看到,我们所要的内容在dd这个标签下,它下面有3个div,第一个是图片的,先不用管,第二个是电影名称,详情页url也在里面,第三个div中有评分结果,所以我们可以这么写
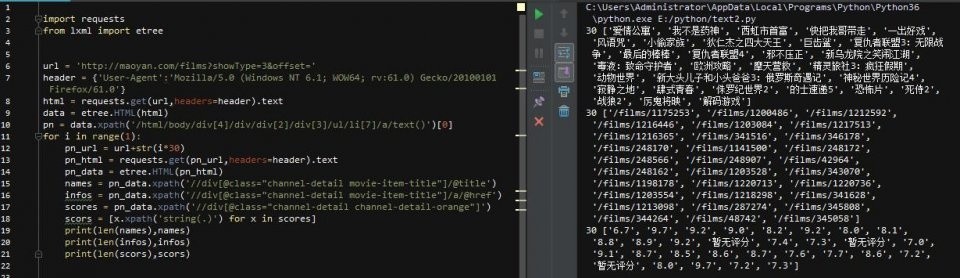
第14行,依然是解析html,第15,16行分别获取class属性为"channel-detail movie-item-title"的div标签下的title值和div下的a标签的href值(这里没有用复制xpath路径,当然如果可以的话,也建议大家用这种方式,因为用路径的话,万一网页修改一下结构,那我们的代码就要重新写了。。。)
第17,18行,2行代码获取div标签下的所有文本内容,还记得那个评分吗?它不在一个标签下,而是2个标签下的文本内容合并的,所以用这种方式获取!
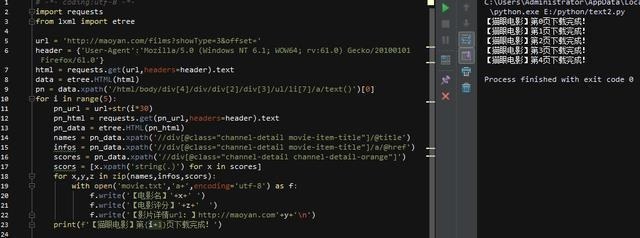
然后,用zip函数,将内容一一对应的写入txt文件里
注意内容间隔和换行!
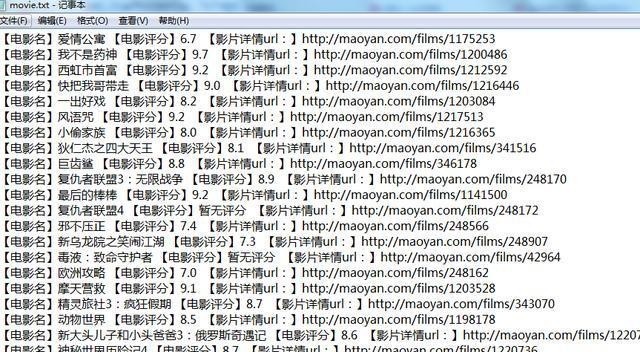
至此,爬虫部分基本完成!先来看看效果吧,时间有限,就先抓前5页,代码和结果如下:
后记
整个爬虫过程,没有什么难点,开始需要注意报头信息(headers),后面在抓取数据的过程中,匹配方式也要多学多用,最后注意数据量,2个方面:抓取间隔和抓取的数量,不要对网站造成不好的影响这个是基本的要求!还有就是这个网站到后面,大约是100多页往后的时候,就需要登录了,这点要注意,具体的大家可以自己去尝试哦!返回搜狐,查看更多
责任编辑:














 1904
1904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









