







博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
2、大数据、计算机专业选题(Python/Java/大数据/深度学习/机器学习)(建议收藏)✅
1、项目介绍
技术栈:Python语言、Django框架、MySQL数据库、MTV设计模式、协同过滤推荐算法、HTML
研究背景:
高校兼职信息分散,学生常被海量岗位淹没,传统公告栏更新慢、匹配度低,亟需基于兴趣行为的个性化推荐平台缩短求职时间。
研究意义:
本系统采用MTV模式开发,集成“基于用户的协同过滤”算法,为用户、企业、管理员三种角色分别提供应聘、发布、管理闭环,可为毕业设计展示“算法-角色权限-可视化”完整方案,预计减少30%岗位筛选时间,提升校内兼职匹配效率。
2、项目界面
(1)用户推荐界面—协同过滤推荐算法
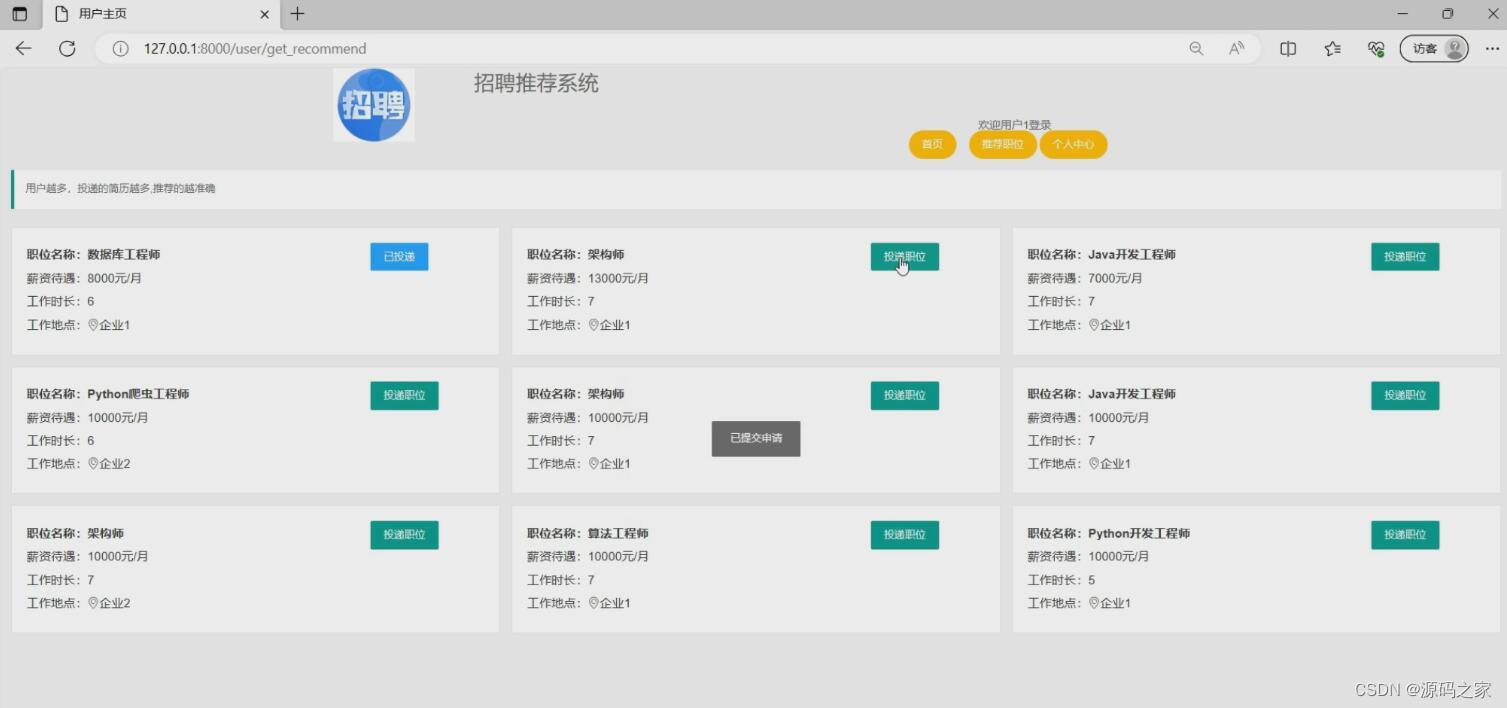
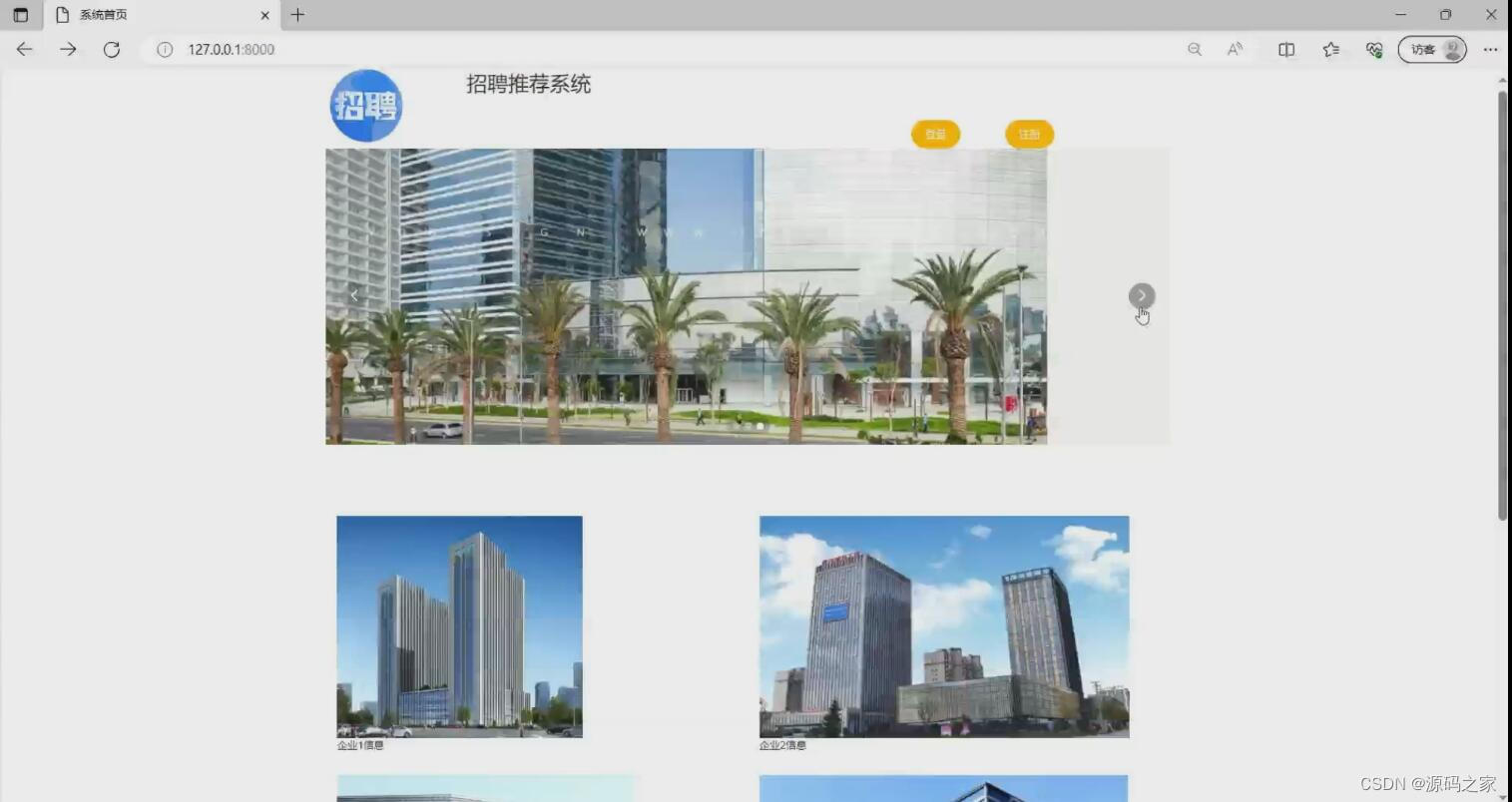
(2)用户首页
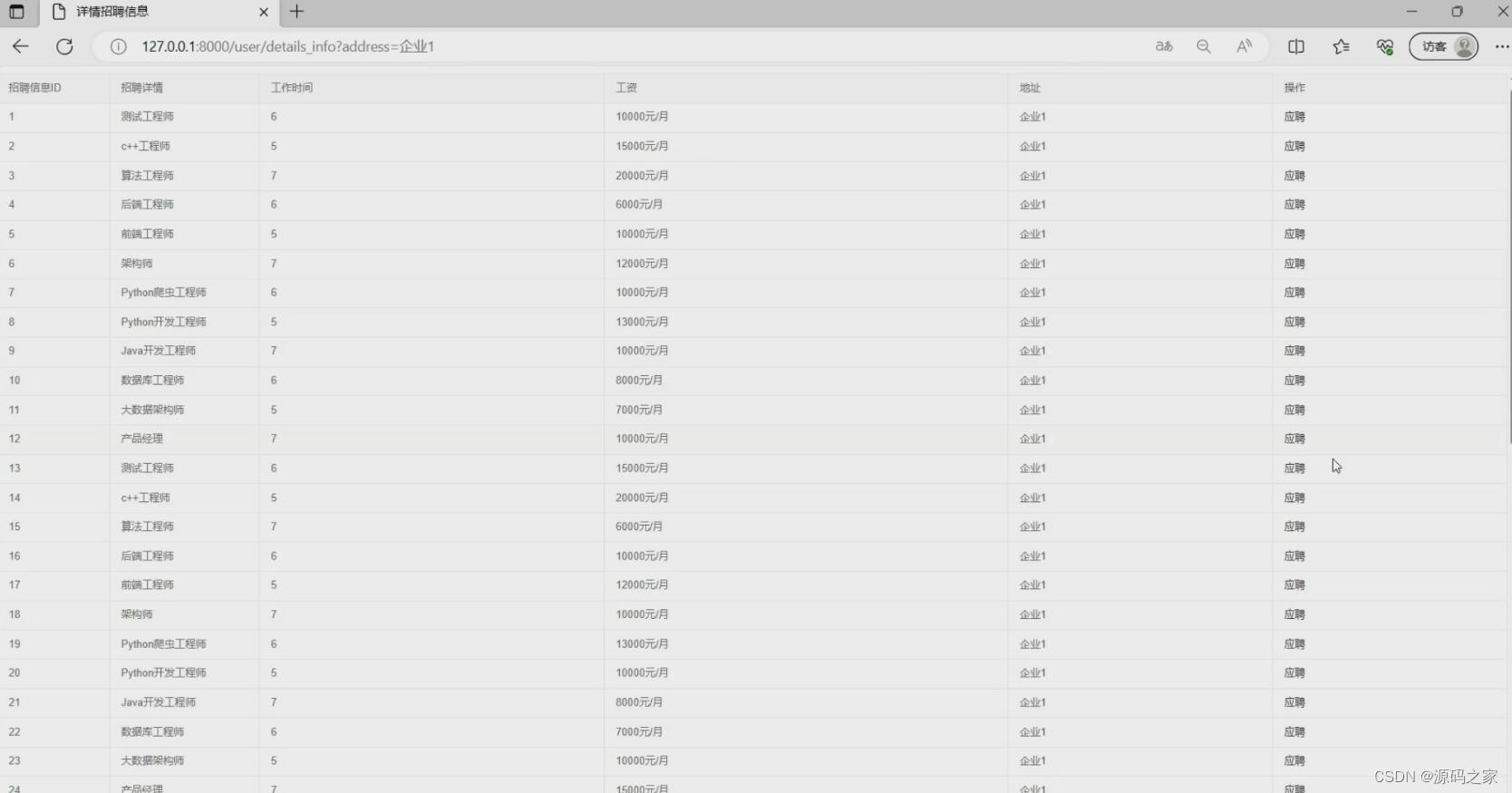
(3)招聘数据(可应聘投递简历)
(4)用户管理界面
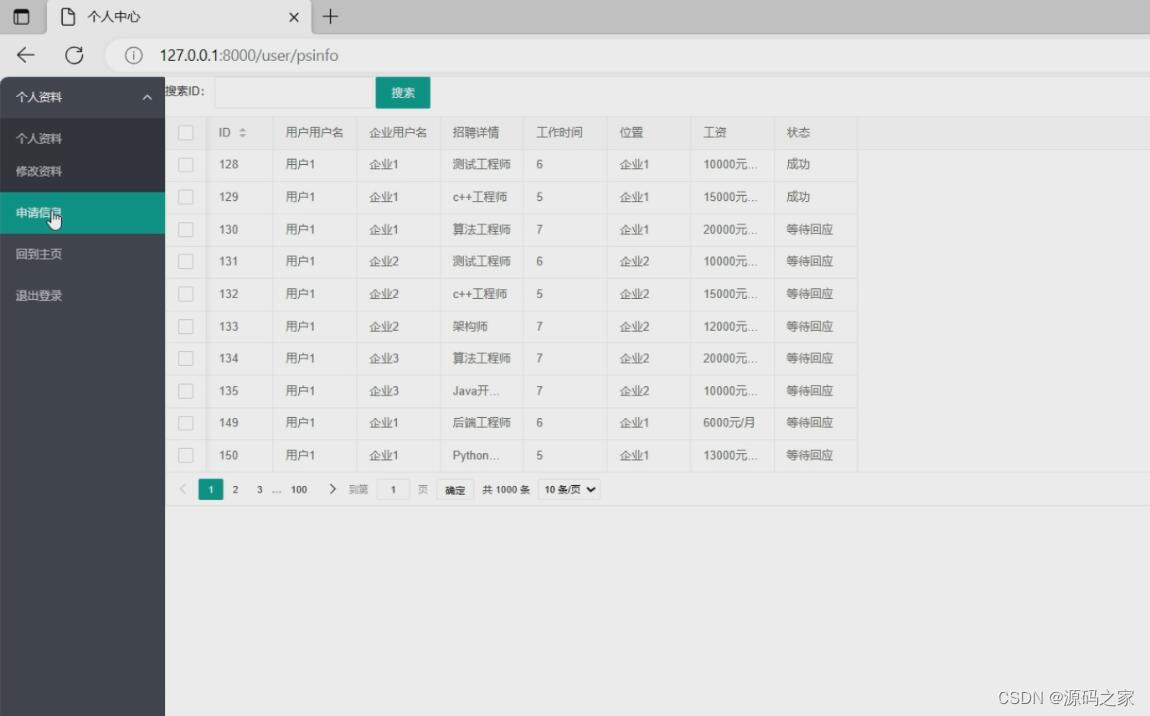
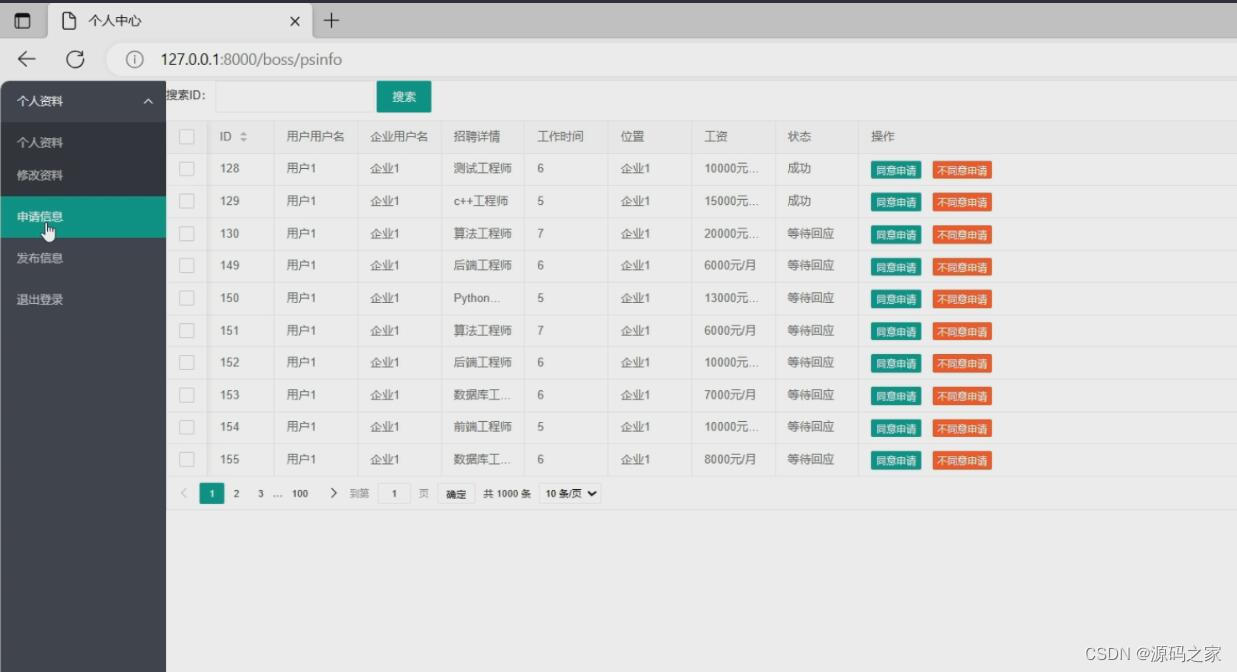
(5)用户申请信息
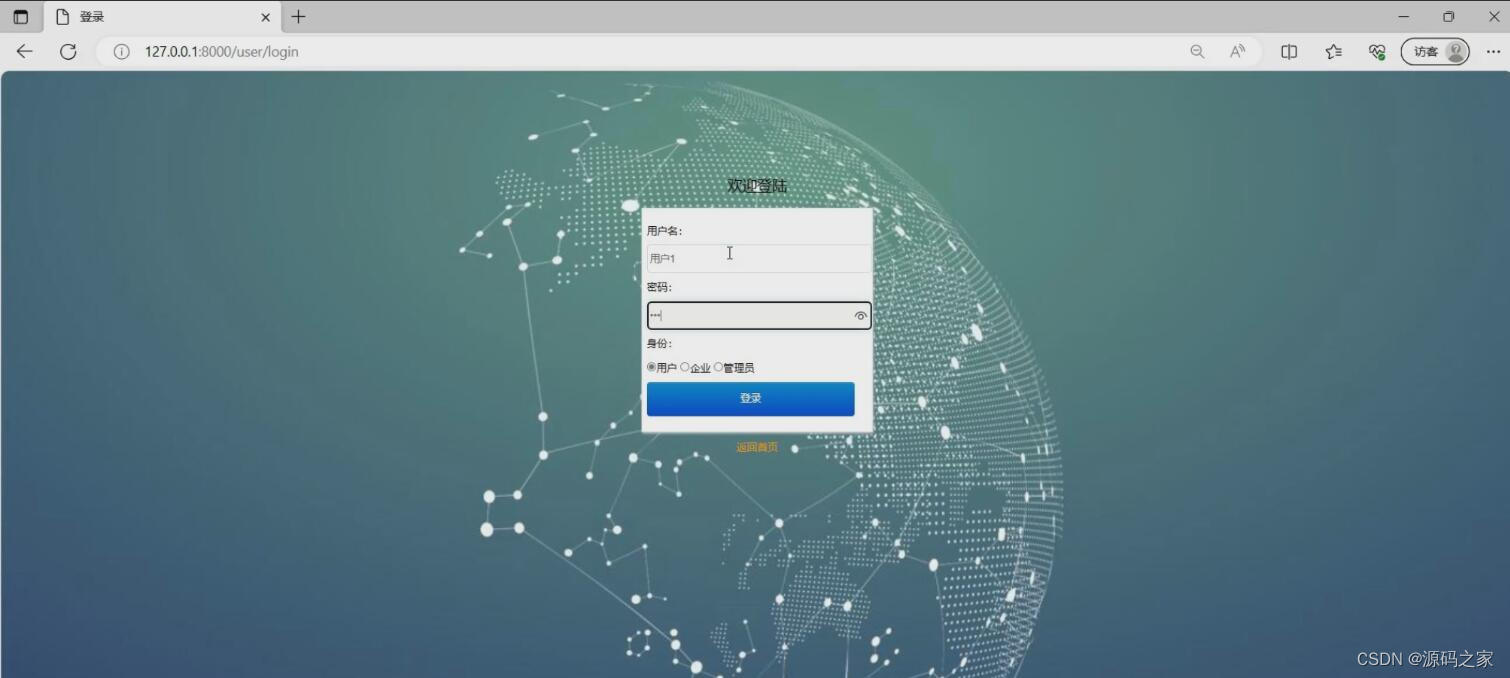
(6)注册登录界面
3、项目说明
系统在协同过滤算法基础上实现招聘推荐功能,采用基于用户的协同过滤技术:通过计算用户间兴趣相似度,为目标用户生成个性化岗位列表。项目使用Python编写,Django框架负责Web服务与权限控制,MySQL存储用户、岗位与申请记录,界面简洁、代码可读性高,便于后期扩展维护。
系统分为用户端与后台管理端:前台支持注册登录、岗位浏览、应聘、个性化推荐、个人信息维护;后台可对账户、申请信息、企业用户进行增删改查。测试阶段系统运行稳定,推荐模块显著缩短用户找兼职时间,实用性强,已成功将协同过滤算法应用于校内招聘场景,为后续功能迭代与学术研究提供了良好基础。
4、核心代码
#!/usr/bin/python3.9.10
# -*- coding: utf-8 -*-
import os
os.environ["DJANGO_SETTINGS_MODULE"] = "djangoProject4.settings"
import django
django.setup()
from boss import models as bm
from user import models as um
from math import sqrt, pow
import operator
from django.db.models import Subquery, Q, Count
import random
import pandas as pd
# # 计算相似度
def similarity(job1_id, job2_id):
job1_set = um.Apply.objects.filter(infoid=job1_id)
# print(job1_set.values())
# job1的投递用户数
job1_sum = job1_set.count()
# job2的投递用户数
job2_sum = um.Apply.objects.filter(infoid=job2_id).count()
# 没有人投递当前职位
if job1_sum == 0 or job2_sum == 0:
return 0
else:
# 两者的交集
common = um.Apply.objects.filter(userid__in=Subquery(job1_set.values('userid')), infoid=job2_id).values('userid').count()
similar_value = common / sqrt(job1_sum * job2_sum) # 余弦计算相似度
return similar_value
def recommend_by_item_id(user_id, k=9):
# 投递简历最多的前三address
jobs_id = um.Apply.objects.filter(userid=user_id).values('infoid') # 先找出用户投过的简历
print(jobs_id)
# 如果当前用户没有投递过简历,则查看所有用户投递的最多的职位进行随机推荐
if um.Apply.objects.filter(userid=user_id).count() == 0:
user_expect_1 = [x['infoid'] for x in list(um.Apply.objects.all().values('infoid'))]
user_expect = [[x, user_expect_1.count(x)] for x in user_expect_1]
user_expect = sorted(user_expect, key=lambda x: x[1], reverse=True)[:k] # 排序后去k个职位
user_expect = [x[0] for x in user_expect]
# print(user_expect)
job_list = [bm.Info.objects.filter(id=x).values().first() for x in user_expect]
while len(job_list) < 9: # 如果小于9则用其他职位随机补充
job_list_1 = bm.Info.objects.all().values().order_by('?').first()
if job_list_1 not in job_list:
job_list.append(job_list_1)
# print(job_list)
# print(len(job_list))
return job_list
else:
key_word_list = [] # 找出用户投递的职位地址信息
for job in jobs_id:
key_word_list.append(bm.Info.objects.get(id=job['infoid']).address)
print(key_word_list)
key_word_list_1 = list(set(key_word_list))
user_prefer = []
for key_word in key_word_list_1:
user_prefer.append([key_word, key_word_list.count(key_word)])
user_prefer = sorted(user_prefer, key=lambda x: x[1], reverse=True) # 排序
user_prefer = [x[0] for x in user_prefer[0:3]] # 找出最多的3个投递简历的key_word
print(user_prefer)
# # 选用户投递最多的职位的地址信息,再随机选择30个没有投递过的简历的职位,计算距离最近
apply_id_list = [x['infoid'] for x in jobs_id]
un_send = list(bm.Info.objects.filter(~Q(id__in=apply_id_list), address__in=user_prefer).order_by('?').values())[:30] # 没有投过的简历
print(un_send)
send = [] # 找出用户投递的职位
for job in apply_id_list:
send.append(bm.Info.objects.filter(id=job).values().first())
print(send)
distances = []
names = []
# 在未投过的简历的职位中找到
for un_send_job in un_send:
for send_job in send:
if un_send_job not in names:
names.append(un_send_job)
distances.append((similarity(un_send_job['id'], send_job['id']), un_send_job)) # 加入相似的职位列表
distances.sort(key=lambda x: x[0], reverse=True)
print('this is distances', distances[:k])
recommend_list = []
for mark, job in distances:
if len(recommend_list) >= k:
break
if job not in recommend_list:
recommend_list.append(job)
print('this is recommend list', recommend_list)
return recommend_list
if __name__ == '__main__':
# similarity(2003, 2008)
# recommend_by_item_id(10)
pass
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

















 1350
1350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









