







连续型变量的描述性分析、t检验,分类变量的卡方检验;
矩阵、列表的元素调用;矩阵操作。
setwd("D:/temp") #设置工作目录
dat_ana <- read.table(file="D:/temp/colon_ana.txt", header=T )
#read.table()读取数据默认将字符型向量转化为因子(stringsAsFactors=T),但对用数值变量编码的因子需重新设定,可用选项colClasses=.
dat_ana <- subset(dat_ana, size > 0 & size <= 150 )
#修改数据框,连续型变量分组,数值变量转化为因子。
dat_ana <- within(dat_ana, {
grade <- as.factor(grade)
t <- as.factor(t)
sizeg <- NA
sizeg[size < 30] <- "1~"
sizeg[size >= 30 & size < 40] <- "30~"
sizeg[size >= 40 & size < 58] <- "40~"
sizeg[size >= 58] <- "58~150"
ageg <- NA
ageg[age < 59] <- "11~"
ageg[age >= 59 & age < 69] <- "59~"
ageg[age >= 69 &age < 79] <- "69~"
ageg[age >= 79] <- "79~106"
ageg <- as.factor(ageg)
sizeg <- as.factor(sizeg)
n_pos <- NA
n_pos[n_positive == 0] <- "no"
n_pos[n_positive > 0] <- "yes"
n_pos <- as.factor(n_pos)
})
#以下为连续型变量的分析
attach(dat_ana)
t1 <- t.test(age ~ ge12node)
t2 <- t.test(size ~ ge12node)
t3 <- t.test(n_positive ~ ge12node)
detach(dat_ana)
datN <- subset(dat_ana, ge12node=="No")
datY <- subset(dat_ana, ge12node=="Yes")
meansY <- round(sapply(datY[c(3, 6, 12)], mean), 2)
meansN <- round(sapply(datN[c(3, 6, 12)], mean), 2)
sdY <- round(sapply(datY[c(3, 6, 12)], sd), 2)
sdN <- round(sapply(datN[c(3, 6, 12)], sd), 2)
medY <- sapply(datY[c(3, 6, 12)], median)
medN <- sapply(datN[c(3, 6, 12)], median)
rsult1 <- matrix(nrow = 7, ncol = 4)
#建一个矩阵,然后填充。双重方括号调用列表成分。
rsult1[1, 1:2] <- c(87085, 27712)
rsult1[2, ] <- c(paste(meansY[[1]], "(±", sdY[[1]], ")"),
paste(meansN[[1]], "(±", sdN[[1]], ")"),
round(t1$statistic, 2), t1$p.value)
rsult1[3, 1:2] <- c(medY[[1]], medN[[1]])
rsult1[4, ] <- c(paste(meansY[[2]], "(±", sdY[[2]], ")"),
paste(meansN[[2]], "(±", sdN[[2]], ")"),
round(t2$statistic, 2), t2$p.value)
rsult1[5, 1:2] <- c(medY[[2]], medN[[2]])
rsult1[6, ] <- c(paste(meansY[[3]], "(±", sdY[[3]], ")"),
paste(meansN[[3]], "(±", sdN[[3]], ")"),
round(t3$statistic, 2), t3$p.value)
rsult1[7, 1:2] <- c(medY[[3]], medN[[3]])
colnames(rsult1)<- c("n≥12", "<12", "t", "p")
rownames(rsult1) <- c("n", rep(c("m±sd", "median"), 3)) #rep()函数循环使用c向量的两个元素3次作为行名。
write.csv(rsult1, file = "D:/temp/rsult1.csv", na = "") #输出保存为Excel表格。
#以下为分类变量的分析
attach(dat_ana)
#table()函数返回结果是一个矩阵,addmargins()加上边际频数和
tsize <- addmargins(table(sizeg, ge12node))
tage <- addmargins(table(ageg, ge12node))
tt <- addmargins(table(t, ge12node))
tgrade <- addmargins(table(grade, ge12node))
tsite <- addmargins(table(site_labeled, ge12node))
tsex <- addmargins(table(sex, ge12node))
tpos <- addmargins(table(n_pos, ge12node))
detach(dat_ana)
a <- chisq.test(tage[1:4, 1:2]) #对象均为列表
b <- chisq.test(tsize[1:4, 1:2])
c <- chisq.test(tt[1:3, 1:2])
d <- chisq.test(tgrade[1:5, 1:2])
e <- chisq.test(tsite[1:9, 1:2])
f <- chisq.test(tsex[1:2, 1:2])
g <- chisq.test(tpos[1:2, 1:2])
m <- matrix(nrow = 36, ncol = 5)
m[1:5, 1:3] <- tage #tage中的元素填充到1-5行、1-3列。
m[1, 4:5] <- c(a$statistic[[1]], a[[3]]) #调用卡方检验中的卡方值和p值(p值是其中的第三个成分)
m[6:10, 1:3] <- tsize
m[6, 4:5] <- c(b$statistic[[1]], b[[3]])
m[11:13, 1:3] <- tsex
m[11, 4:5] <- c(f$statistic[[1]], f[[3]])
m[14:19, 1:3] <- tgrade
m[14, 4:5] <- c(d$statistic[[1]], d[[3]])
m[20:23, 1:3] <- tt
m[20, 4:5] <- c(c$statistic[[1]], c[[3]])
m[24:33, 1:3] <- tsite
m[24, 4:5] <- c(e$statistic[[1]], e[[3]])
m[34:36, 1:3] <- tpos
m[34, 4:5] <- c(g$statistic[[1]], g[[3]])
col1 <- round(m[, 1]/m[, 3], 3) #矩阵两列之间的计算,创建一个新矩阵,只含计算结果一列
col2 <- round(m[, 2]/m[, 3], 3)
m2 <- cbind(col1, m) #合并两个矩阵
m3 <- cbind(col2, m2)
m3[, 1:3] <- m3[, 3:1] #交换两列位置(但列名是不交换的,所以应在交换之后再命名列)
m3[, 3:4] <- m3[, 4:3]
m4 <- matrix(nrow = 36, ncol = 5) #为了使频数和比例在同一列中显示,新建矩阵,然后使用paste()函数。
m4[, 1] <- paste(m3[, 1], "(", m3[, 2], ")")
m4[, 2] <- paste(m3[, 3], "(", m3[, 4], ")")
m4[, 3:5] <- m3[, 5:7]
colnames(m4) <- c("n<12(%)", "n≥12(%)", "total", "chisq", "p") #命名列
attach(dat_ana)
rownames(m4) <- c(levels(ageg), "total",
levels(sizeg), "total",
levels(sex), "total",
levels(grade), "total",
levels(t), "total",
levels(site_labeled), "total",
levels(n_pos), "total")
#命名时,可以调用因子水平作为行名。
detach(dat_ana)
write.csv(m4, file = "D:/temp/rsult2.csv", na = "")结果呈现形式:
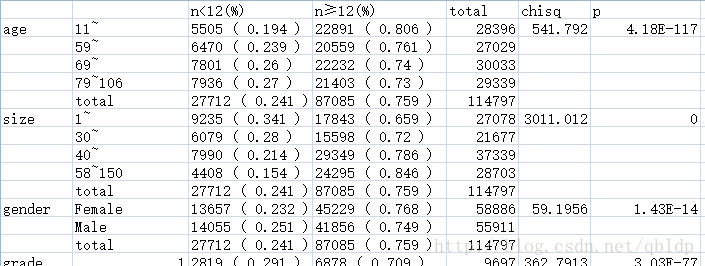
遇到几个问题:
1. prop.table()生成比例而不是在原有频数表内添加比例。怎样使一个表格即有频数又有比例?
2. 关于添加行名列名,这样的行名怎么做出来?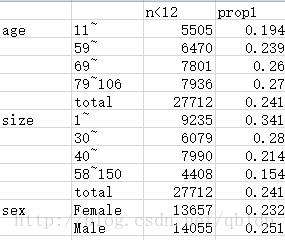
3. 对不同变量反复使用同一个函数时,有没有更简便的办法?
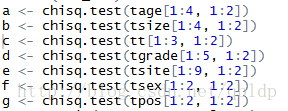
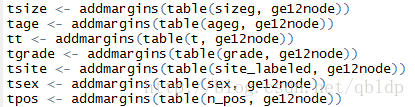














 1149
1149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









