









[面试记录]
在一个表中有多条重复数据,并且没有主键,也就是所有字段都一样的重复
如图 表名 name_age
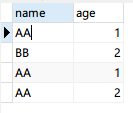
查询唯一数据的话很简单 我们用distinct就可以实现
select DISTINCT `name`, age from name_age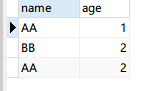
但是现在问题是要删除表中的多余数据,而且重复数据的所有字段都是一样的这就比较复杂了。我采用的方式是借助一个临时表。
将查询的不重复的结果创建为一个临时表,然后清空原来的数据表,然后将临时表中的所有数据插入回原来的数据表中,最后删除临时表。
create table temp_name_age (select DISTINCT `name`, age from name_age);
truncate name_age;
insert into name_age (`name`, age) SELECT * from temp_name_age;
DROP TABLE temp_name_age ;














 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









