







简介
RDD之间的依赖关系大致分为两类:窄依赖和宽依赖。
借用参考文章的解释:
- 窄依赖:父
RDD中的一个分区最多只会被子RDD中的一个分区使用,换句话说,父RDD中,一个分区内的数据是不能被分割的,必须整个交付给子RDD中的一个分区。 - 宽依赖:父
RDD中的分区可能会被多个子RDD分区使用,数据会被切分。
依赖关系图
体现在源码中的关系如图:
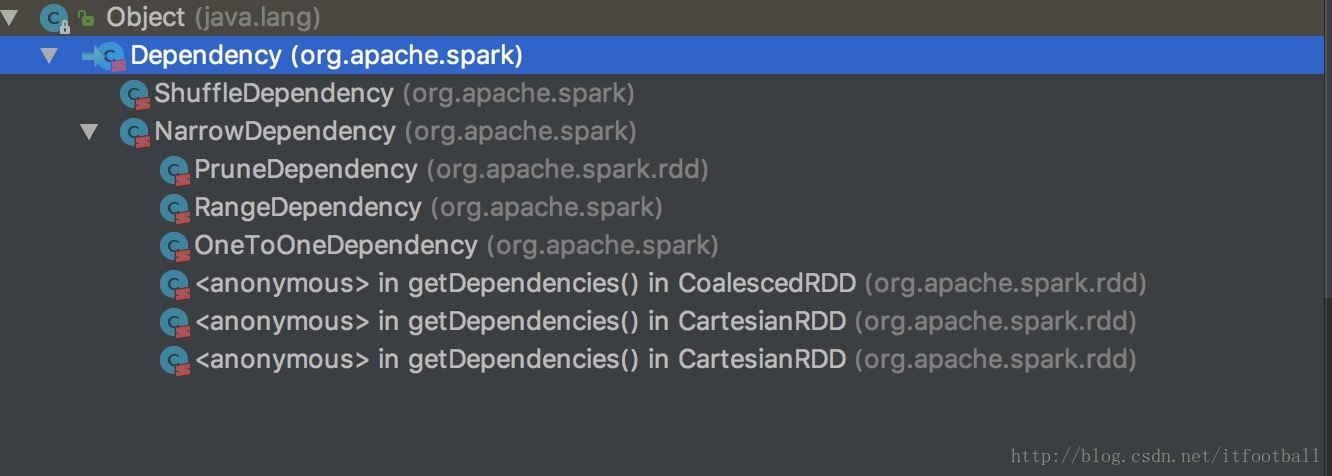
Dependency (org.apache.spark)
ShuffleDependency (org.apache.spark)
NarrowDependency (org.apache.spark)
PruneDependency (org.apache.spark.rdd)
RangeDependency (org.apache.spark)
OneToOneDependency (org.apache.spark)依赖概念类
Dependency
@DeveloperApi
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}比较简单,只有简单的提供了一个方法rdd,得到的是父类RDD对象,也就是其所依赖的RDD。
窄依赖类
NarrowDependency
@DeveloperApi
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
/**
* Get the parent partitions for a child partition.
* @param partitionId a partition of the child RDD
* @return the partitions of the parent RDD that the child partition depends upon
*/
def getParents(partitionId: Int): Seq[Int]
override def rdd: RDD[T] = _rdd
}增加了一个getParents方法,得到子RDD的某个分区所依赖的父RDD中分区,返回的是分区ID号的序列。
该类也是抽象类,窄依赖还细分了3个子类,分别为:
PruneDependency,RangeDependency,OneToOneDependency
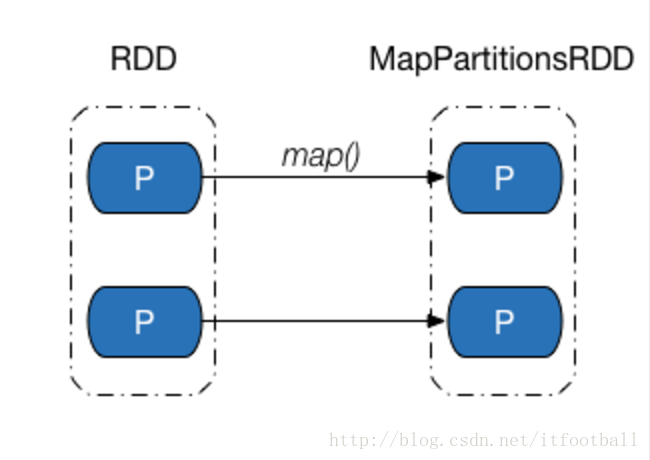
OneToOneDependency
子RDD的每一个分区对应父RDD的一个分区,一个父分区只有一个子分区对应,子分区的个数和父分区的个数一样。
图解A
图解B
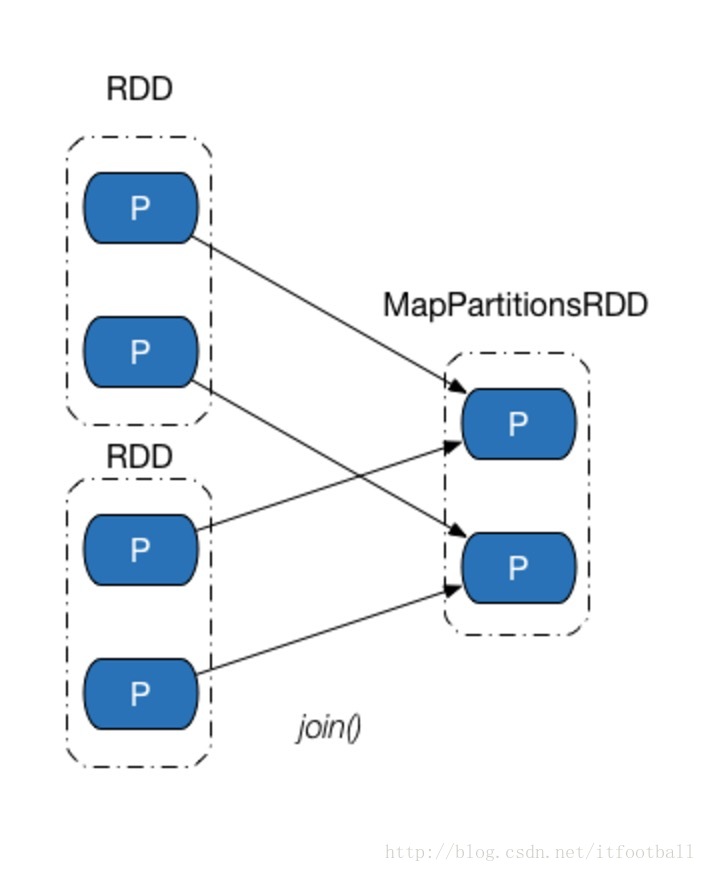
以上两种情况都属于1:1依赖。
@DeveloperApi
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId)
}获取父分区的方法就是直接把传递进去的id号封装成Seq返回来就可以了。因为1:1依赖中,父分区的编号和子分区的编号是一样的。
RangeDependency
多个父RDD,一个子RDD,除了第一个父RDD的分区编号和子RDD是一样的,其他的都不一样。
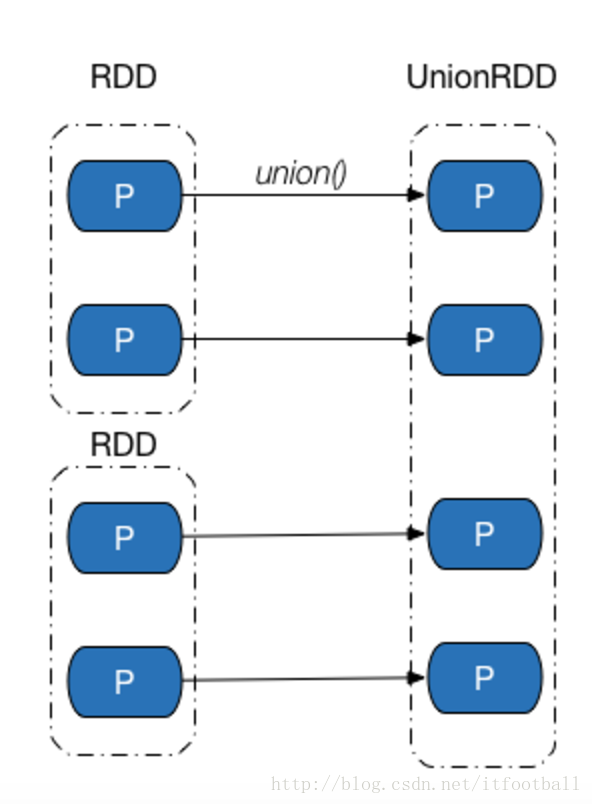
只存在union操作产生的UnionRDD与父RDD的依赖关系中。我们可以通过源码中谁调用了RangeDependency对象来作证只有UnionRDD用到这个依赖:
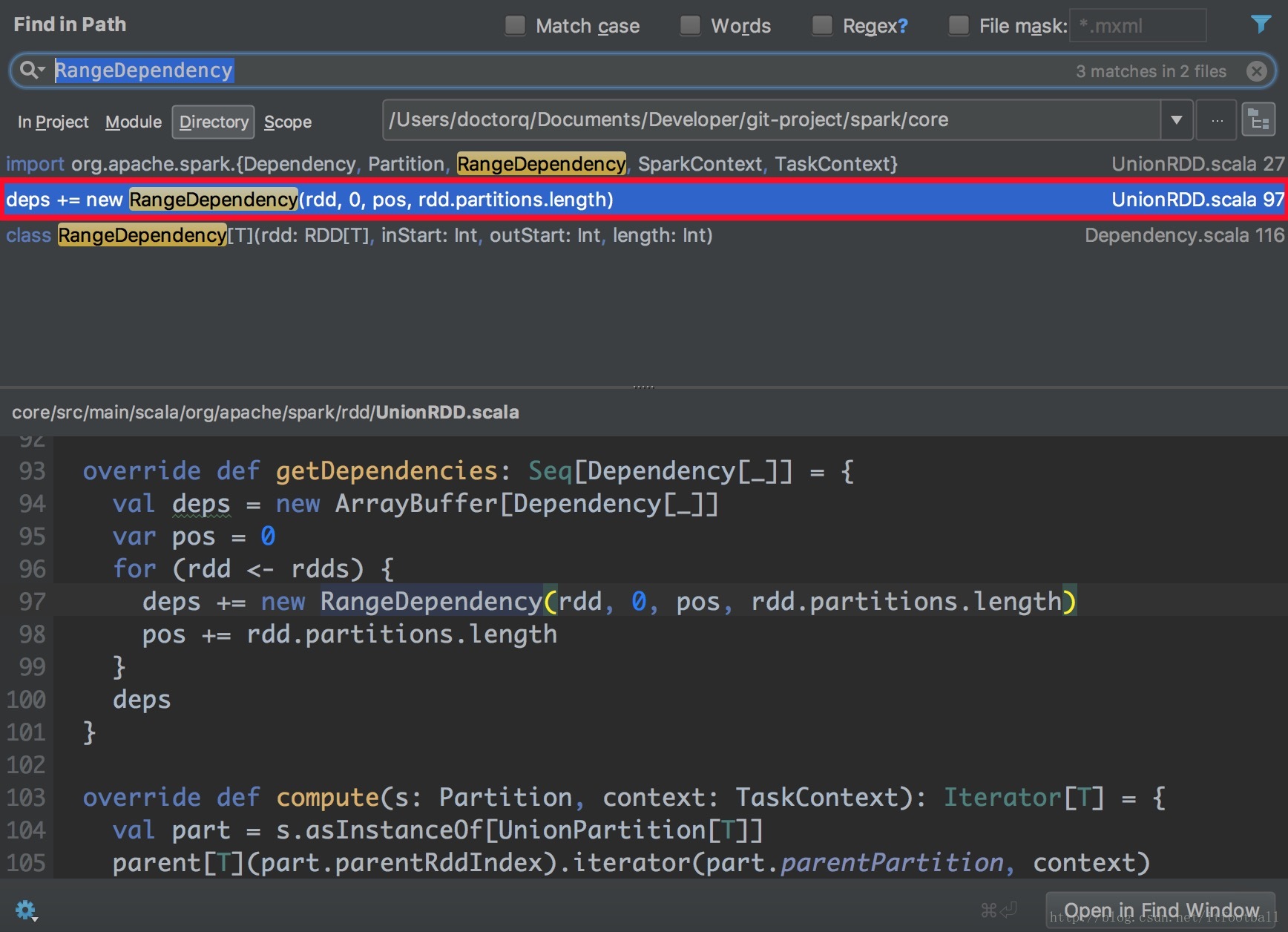
图解
@DeveloperApi
class RangeDependency[T](rdd: RDD[T], inStart: Int, outStart: Int, length: Int)
extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = {
if (partitionId >= outStart && partitionId < outStart + length) {
List(partitionId - outStart + inStart)
} else {
Nil
}
}
}获取子分区的父分区ID号是一个if判断,不像之前那么简单了。首先解释几个概念
- inStart:父RDD分区起始ID好。
- outStart:父RDD分区起始ID在子RDD中分区ID号。
- length:父RDD中分区个数。
生成依赖的代码如下:
UnionRDD.getDependencies
override def getDependencies: Seq[Dependency[_]] = {
val deps = new ArrayBuffer[Dependency[_]]
var pos = 0
for (rdd <- rdds) {
deps += new RangeDependency(rdd, 0, pos, rdd.partitions.length)
pos += rdd.partitions.length
}
deps
}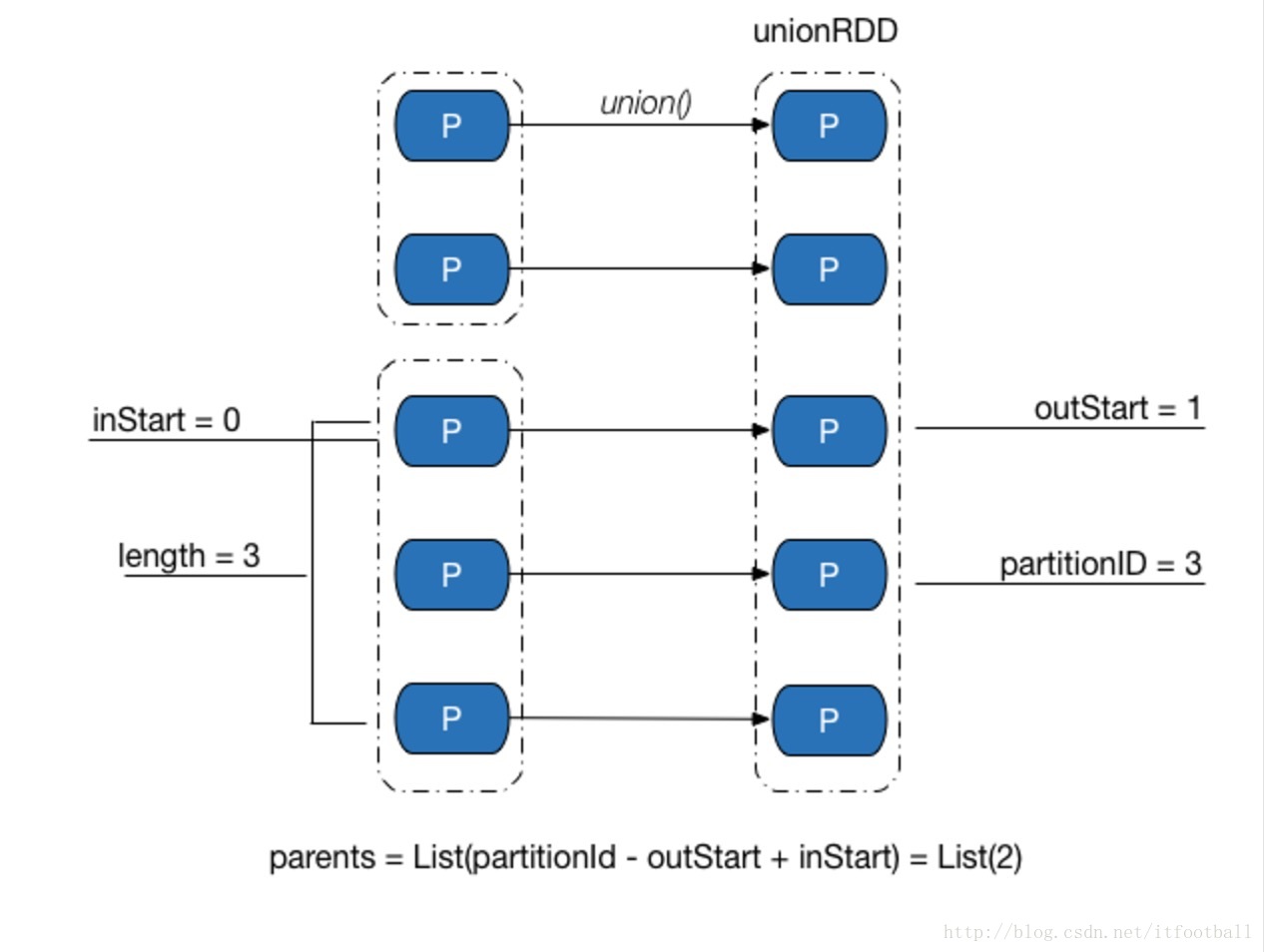
上图中的2个父类RDD生成依赖如下
- rdd0:RangeDependency(rdd0,0,0,2)
- rdd1:RangeDependency(rdd1,0,2,3)
所以如果想得到子RDD中partitionID=3在父RDD的分区号
outStart=2
inStart=0
3-2+0 = 1
就是父RDD中partitionID=1的分区。
PruneDependency
具体没找到相关文章,只能简单按照自己的理解来了。
该依赖只针对PartitionPruningRDD对象的依赖。Prune有裁剪的意思,在这里表示父RDD有一部分的分区是子RDD分区依赖的,有一部分因为过滤函数过滤掉了。一般都会根据parttion的索引值做过滤,比如如下代码:
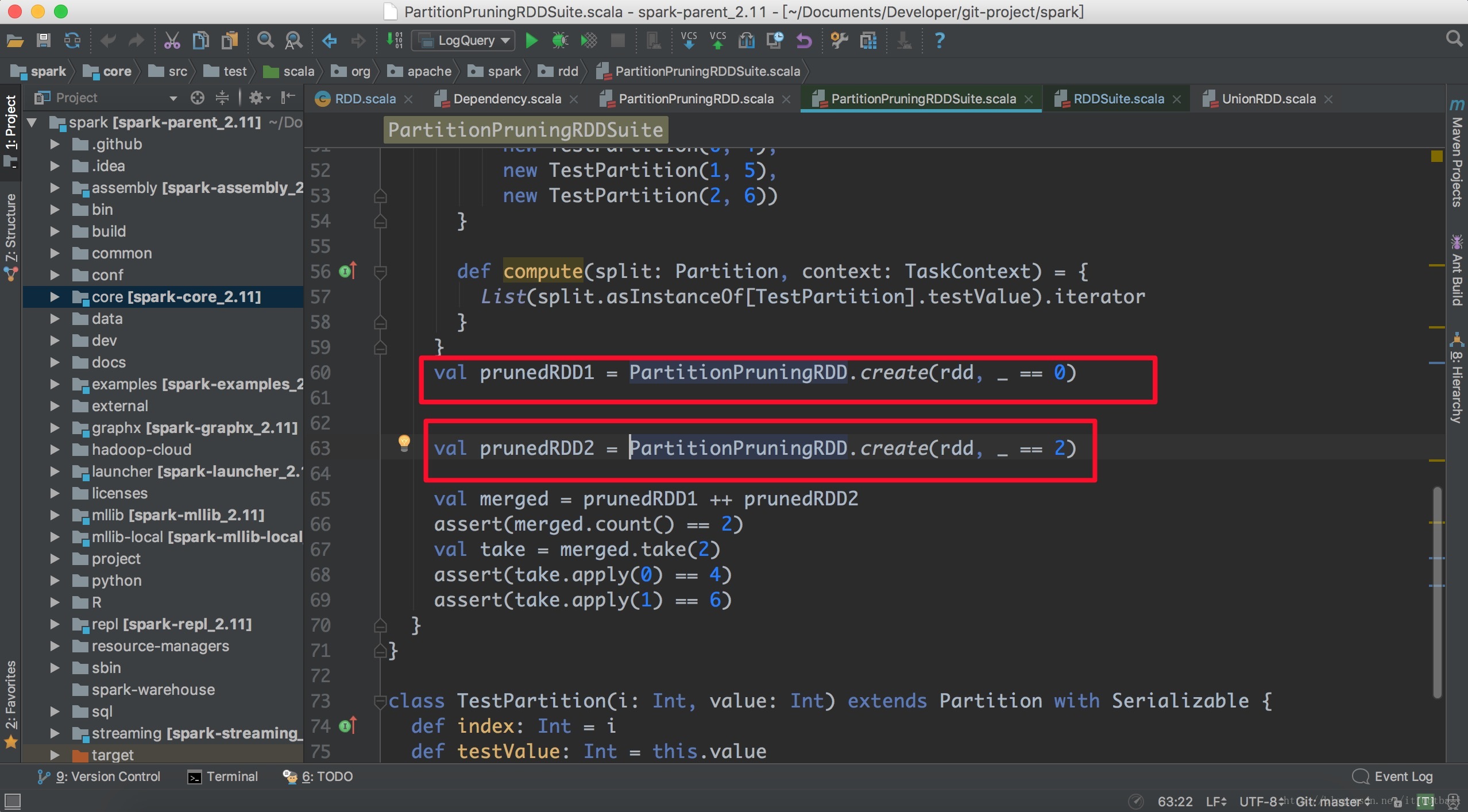
上面用索引值为0或2来过滤掉了父类RDD的partition。
private[spark] class PruneDependency[T](rdd: RDD[T], partitionFilterFunc: Int => Boolean)
extends NarrowDependency[T](rdd) {
@transient
val partitions: Array[Partition] = rdd.partitions
.filter(s => partitionFilterFunc(s.index)).zipWithIndex
.map { case(split, idx) => new PartitionPruningRDDPartition(idx, split) : Partition }
override def getParents(partitionId: Int): List[Int] = {
List(partitions(partitionId).asInstanceOf[PartitionPruningRDDPartition].parentSplit.index)
}
}
重点关注函数partitions,首先通过filter过滤分区,过滤函数是创建该对象时指定的,过滤以后通过zipWithIndex生成一个(k,v)的Partitions,Array[Partition],格式如下:
Array((Partition,0),(Partition,1)....)然后用map函数生成PartitionPruningRDDPartition对象。
宽依赖类
父RDD中的一个分区的数据被多个子分区依赖,数据被切分。
图解
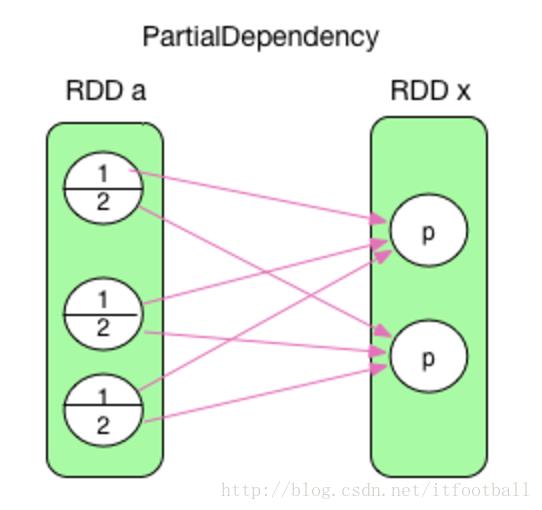
这里一定要理解的一点是,能被定义为ShuffleDependency依赖的,一定是一个分区的数据被切分成不同的小块,每一个小块被不同的子分区依赖。因为在完全依赖中也会出现上面的一个分区被多个分区依赖,但是他是全部依赖父分区中的全部数据,而不是切分只依赖一部分。spark只定义了全依赖的2种:1:1,N:1,而抛弃了N:N,因为和ShuffleDependency类似,不好区分。
ShuffleDependency
@DeveloperApi
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]] {
override def rdd: RDD[Product2[K, V]] = _rdd.asInstanceOf[RDD[Product2[K, V]]]
private[spark] val keyClassName: String = reflect.classTag[K].runtimeClass.getName
private[spark] val valueClassName: String = reflect.classTag[V].runtimeClass.getName
// Note: It's possible that the combiner class tag is null, if the combineByKey
// methods in PairRDDFunctions are used instead of combineByKeyWithClassTag.
private[spark] val combinerClassName: Option[String] =
Option(reflect.classTag[C]).map(_.runtimeClass.getName)
val shuffleId: Int = _rdd.context.newShuffleId()
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.length, this)
_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
}ShuffleDependency中RDD必须是(K,V)键值对的形式。
member解释如下:
- rdd方法:将
rdd转换为K,V形式的RDD。 - keyClassName:K类型。
- valueClassName:V的类型。
- combinerClassName:组合器,将切割后的数据组合在一个RDD所使用的组合器。
- shuffleId:每一次的shuffle过程,都有一个ID号标识。
- shuffleHandle:shuffle句柄(尴尬的翻译),在
shuffleManager注册了一个事件,进行shuffle操作。
最后一个语句就是确保当前代码能被序列化。这个地方有一个shuffleManager后续会再看看。














 1014
1014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









