







我会不间断的更新,维护,希望可以对正在找大数据工作的朋友们有所帮助.
第二章目录
第二章 Spark
2.1 Spark 原理
2.1.1 Shuffle 原理
2.1.1.1 SortShuffle
- mapTask将map(聚合算子)或array(join算子)写入内存
- 达到阀值发生溢写,溢写前根据key排序,分批写入磁盘,最终将所有临时文件合并成一个最终文件,并建立一份索引记录分区信息。一个mapTask最终形成一个文件。
- reduceTask拉取各个task中自己的分区数据去计算。
2.1.1.2 和hadoop shuffle的区别
- MR没有所谓的DAG划分,一次MR任务就意味着一次shuffle;spark则是RDD驱动的,行动算子触发时才会按宽窄依赖划分阶段,只有宽依赖才会发生shuffle
- MR在reduce端还会进行一次合并排序,spark则在map端就完成了排序,采用Tim-Sort排序算法
- MR的reduce拉取的数据直接放磁盘再读,spark则是先放内存,放不下才放磁盘
- MR在数据拉取完毕后才开始计算,spark则是边拉边计算(reduceByKey原理)
- 基于以上种种原因,MR自定义分区器时往往还需要自定义分组,spark则不需要(或者说map结构已经是自定义分组了)。
2.1.2 job 提交流程(重点)
2.1.2.1 standalone
- driver端:通过反射获取主类执行main方法 -> 创建sparkconf和sparkContext,创建通信环境、后端调度器(负责向master发送注册信息、向excutor发送task的调度器)、task调度器、DAG(根据宽窄依赖划分stage)调度器 ->封装任务信息提交给Master
- Master端:缓存任务信息并将其放入任务队列 -> 轮到该任务时,调用调度方法进行资源调度 ->发送调度信息给对应的worker
- Worker端:worker将调度信息封装成对象 -> 调用对象的start方法,启动excutor进程
- Excutor进程:启动后向driver端反向注册(driver端拿到信息后注册excutor,向其发送任务) -> 创建线程池,封装任务对象 -> 获取池中线程执行任务 -> 反序列化TastSet,执行给定的各种算子步骤
2.1.2.2 yarn-client
- 客户端向yarn的RM申请启动AM,同时在自身的sparkContext中创建DAGScheduler和TASKScheduler(创建driver)
- 按照正常Yarn流程,一个NM领取到AM任务作为AM与客户端的driver产生连接(在yarn-cluster中该AM直接作为driver而不是连接driver)
- driver根据任务信息通过AM向RM申请资源(计算容器)
- AM通知领取到任务的NM向driver的sparkContext反注册并申请Task
- driver的sparkContext分配Task给各个计算节点,并随时掌握各个任务运行状态
- 应用程序运行完成后,sparkContext向RM申请注销并关闭自己。
总结:与standalone区别是,AM只作为中间联系,实际作为AM的是driver的sparkContext
2.1.2.3 yarn-cluster
- 先将driver作为一个AM在一个NM中启动
- 由AM创建应用程序,走正常的yarn流程启动Executor运行Task,直到运行完成
总结:与yarn client相比只是把driver端由客户端变成了集群中的某个NodeManager节点。
2.1.3 Job 运行原理
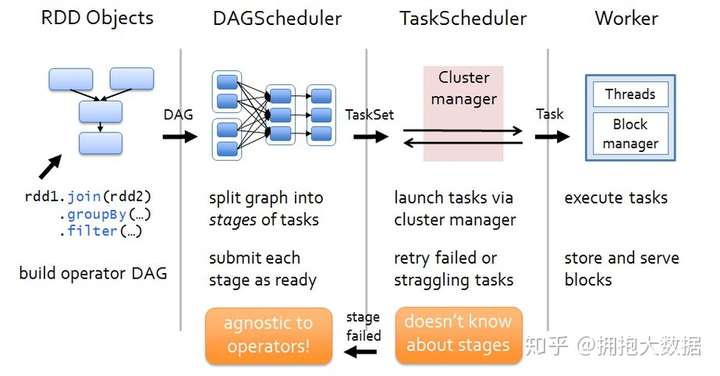

阶段一:我们编写driver程序,定义RDD的action和transformation操作。这些依赖关系形成操作的DAG。
阶段二:根据形成的DAG,DAGScheduler将其划分为不同的stage。
阶段三:每一个stage中有一个TaskSet,DAGScheduler将TaskSet交给TaskScheduler去执行,TaskScheduler将任务执行完毕之后结果返回给DAGSCheduler。
阶段四:TaskScheduler将任务分发到每一个Worker节点去执行,并将结果返回给TaskScheduler。
2.1.4 Task 重试与本地化级别
TaskScheduler遍历taskSet,调用launchTask方法根据数据"本地化级别"发送task到指定的Executor
task在选择Executor时,会优先第一级,如果该Executor资源不足则会等待一段时间(默认3s),然后逐渐降级。
2.1.4.1 本地化级别
PROCESS_LOCAL 进程本地化
NODE_LOCAL 节点本地化
NO_PREF 非本地化
RACK_LOCAL 机架本地化
ANY 任意
2.1.4.2 重试机制
taskSet监视到某个task处于失败或挣扎状态时,会进行重试机制
当某个task提交失败后,默认会重试3次,3次之后DAGScheduler会重新提交TaskSet再次尝试,总共提交4次,当12次之后判定job失败,杀死Executor
挣扎状态:当75%的Task完成之后,每隔100s计算所有剩余task已执行时间的中位数,超过这个数的1.5倍的task判定为挣扎task。
2.1.5 DAG原理(源码级)
- sparkContext创建DAGScheduler->创建EventProcessLoop->调用eventLoop.start()方法开启事件监听
- action调用sparkContext.runJob->eventLoop监听到事件,调用handleJobSubmitted开始划分stage
- 首先对触发job的finalRDD调用createResultStage方法,通过getOrCreateParentStages获取所有父stage列表,然后创建自己。
如:父(stage1,stage2),再创建自己stage3 - getOrCreateParentStages内部会调用getShuffleDependencies获取所有直接宽依赖(从后往前推,窄依赖直接跳过)
在这个图中G的直接宽依赖是A和F,B因为是窄依赖所以跳过,所以最后B和G属于同一个stage - 接下来会循环宽依赖列表,分别调用getOrCreateShuffleMapStage:
-- 如果某个RDD已经被划分过会直接返回stageID;否则就执行getMissingAncestorShuffleDependencies方法,继续寻找该RDD的父宽依赖,窄依赖老规矩直接加入:
-- 如果返回的宽依赖列表不为空,则继续执行4,5的流程直到为空为止; -- 如果返回的宽依赖列表为空,则说明它没有父RDD或者没有宽依赖,此时可以直接调用createShuffleMapStage将该stage创建出来 - 因此最终的划分结果是stage3(B,G)、stage2(C,D,E,F)、stage1(A)
- 创建ResultStage,调用submitStage提交这个stage
- submitStage会首先检查这个stage的父stage是否已经提交,如果没提交就开始递归调用submitStage提交父stage,最后再提交自己。
- 每一个stage都是一个taskSet,每次提交都会提交一个taskSet给TaskScheduler
2.1.6 SparkContext 创建流程(源码级)
- SparkSubmit反射调用主类的main方法
- main方法中初始化SparkContext对象
- SparkContext开始初始化Spark通信环境 RpcEnv
- SparkContext创建TaskSchedulerImpl对象
- SparkContext创建StandaloneSchedulerBackend对象
- 最后创建DAGScheduler对象
2.1.7 Spark SQL 运行原理
- SQL语句封装到SQLContext对象中
- 调用分析器检查语义、调用翻译器翻译成RDD算子、调用优化器选择最佳算子
- 打包成jar包上传集群
- 走常规spark作业流程
2.1.8 Spark的内存模型
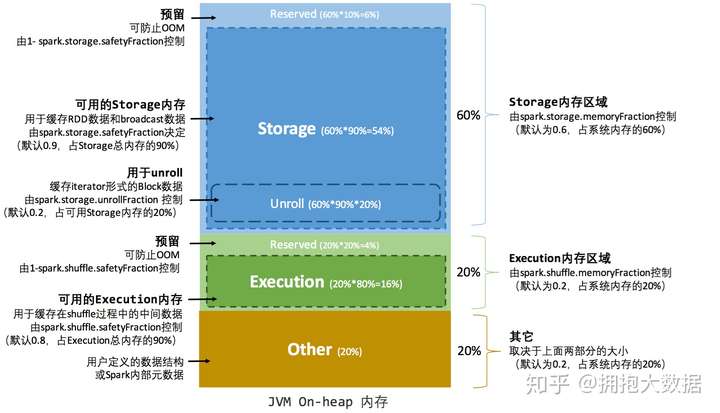
executor的内存分为4+1块:
Execution:计算用内存,用于执行各种算子时存放临时对象的内存
Storage:缓存用内存,主要存储catch到内存中的数据,广播变量也存在这里
User Memory:用户用内存,存储RDD依赖关系等RDD的信息
Reserved Memory:预留内存,用来存储Spark自己的对象
Off-heap Memory:堆外内存,开启之后计算和缓存的内存都分别可以存在堆外内存。堆外内存不受spark GC的影响。
Execution和Storage采用联合内存机制,可以互相借用对方的内存区域,但是Execution可以强制征收Storage的内存,反过来不行。
Task共用executor的内存区域,spark准备了一个hashMap用来记录各个task使用的内存,task申请新的内存时,如果剩余内存不够则会阻塞直到有足够的内存为止。每个task至少需要1/2N的内存才能被启动。
2.1.9 算子原理
2.1.9.1 foreach和foreachPartition的区别
两个算子都是属于Action算子,但是适用于场景不同,foreach主要是基于输出打印使用,进行数据的显示,而foreachPartition的适用于各种的connection连接创建时候进行使用,保证每个分区内创建一个连接,提高执行效率,减少资源的消耗。
2.1.9.2 map与mapPartitions的区别
两个算子都属于transformtion算子,转换算子,但是适用于场景不同,map是处理每一条数据,也就是说,执行效率稍低,而mapPartition是处理一个分区的数据,返回值是一个集合,也就是说,在效率方面后者效率更高,前者稍低,但是在执行安全性方面考虑,map更适合处理大数据量的数据,而mappartition适用于中小型数据量,如果数据量过大那么会导致程序的崩溃,或oom。
2.2 spark版本2.x 与1.6的区别
底层的执行内存模型发生改变,从之前的静态内存模型,改为动态内存模型,在spark2.X以后推出了一个全新的特性,叫DataSet,DataSet相当于整合了DF和RDD之间的关系,可以更容易的操作Spark的API。
2.3 Spark 概念
2.3.1 RDD
RDD是一个弹性分布式数据集,是一个只读的分区记录的集合,只能基于某个数据集或其他RDD上转换而来,因此具有高容错、低开销的特点。
2.3.2 Job
job 可以认为是我们在driver 或是通过spark-submit 提交的程序中一个action ,在我们的程序中有很多action 所有也就对应很多的jobs
2.3.3 Stage
stage是由DAGScheduler根据宽窄依赖划分spark任务所得到的一组可并行执行的task任务集合,存在依赖关系的stage之间是串行的,一个sparkJob可能产生多组stage。
Stage有两个子类:ResultStage和ShuffleMapStage
2.3.3.1 ResultStage
在RDD的某些分区上应用函数来计算action操作的结果,对应DAG原理中createResultStage()创建的对象
2.3.3.2 ShuffleMapStage
ShuffleMapStage 是中间的stage,为shuffle生产数据。它们在shuffle之前出现。当执行完毕之后,结果数据被保存,以便reduce 任务可以获取到。
2.3.4 Task
task是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









