







1 select- into outfile结果导出
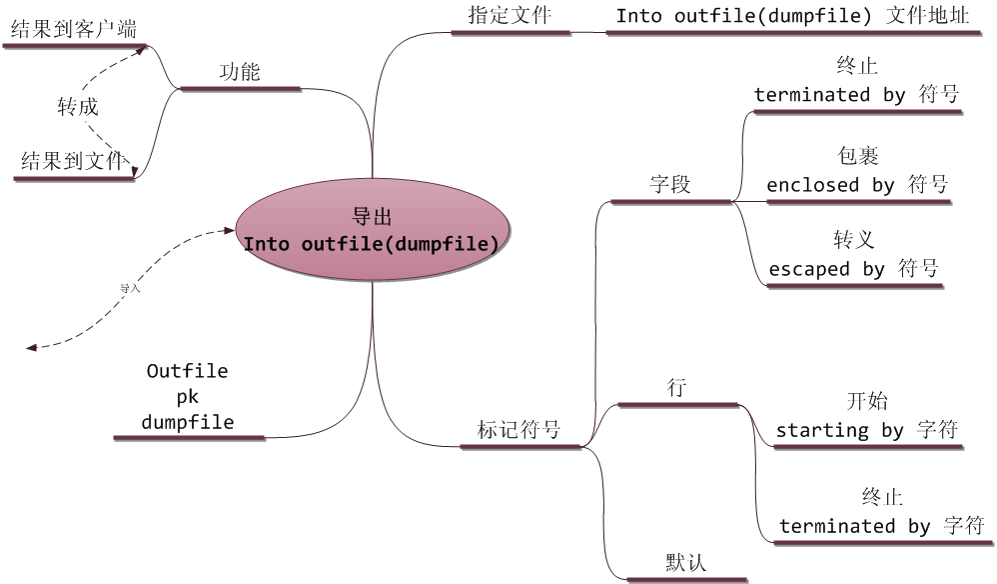
导出结果到文件
mysql支持,将获得到的数据记录在文件内而不是返回到客户端。
常规的:文件内的每一行是一条数据,而每个字段之间使用水平制表符分隔。
导出的数据文件可以使用LOAD DATA INFILE语法载入到某个数据表内。
注意, 不允许向已经存在的文件内导出数据
在导出到文件的过程中,支持配置字段分隔符,包裹符,和转义符。和配置行(记录)结束符,和起始符
默认为:
字段:fields terminated by '\t' enclosed by '' escaped by '\\‘
记录:lines terminated by '\n' starting by ''
其他常用的是:字段使用逗号分割,而使用引号包裹
同时支持 into dumpfile,作用与outfile一致,不过是不做任何换行和转义处理。非常适合导出二进制数据。
mysql支持,将获得到的数据记录在文件内而不是返回到客户端。
常规的:文件内的每一行是一条数据,而每个字段之间使用水平制表符分隔。
导出的数据文件可以使用LOAD DATA INFILE语法载入到某个数据表内。
注意, 不允许向已经存在的文件内导出数据
在导出到文件的过程中,支持配置字段分隔符,包裹符,和转义符。和配置行(记录)结束符,和起始符
默认为:
字段:fields terminated by '\t' enclosed by '' escaped by '\\‘
记录:lines terminated by '\n' starting by ''
其他常用的是:字段使用逗号分割,而使用引号包裹
SELECT a,b,a+b INTO OUTFILE ‘file‘
FIELDS TERMINATED BY ',' ENCLOSED BY '"‘
LINES TERMINATED BY '\n‘
FROM test_table;同时支持 into dumpfile,作用与outfile一致,不过是不做任何换行和转义处理。非常适合导出二进制数据。
mysql> select * into outfile "E:/outfile.txt" from one;
Query OK, 3 rows affected (0.00 sec)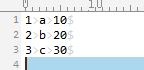
可以看出,字段间用制表符(tab键)隔离,行之间用换行符隔离,这是MySQL中默认的行为;
增加过滤条件:
mysql> select * into outfile "E:/outfile2.txt" from teacher_class where id between 2 and 5;
Query OK, 4 rows affected (0.02 sec)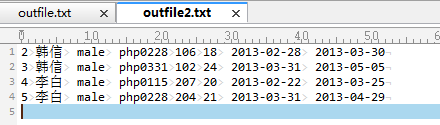
注意:导出的文件名不能重复!
为了满足某种特别的需求,会采用不同的分割方式。
支持,在导出数据时,设置记录,与字段的分割符。
通过如下的选项:
fields:设置字段选项
Lines: 设置行选项(记录选项)
先看默认值:
字段:
记录:

支持,在导出数据时,设置记录,与字段的分割符。
通过如下的选项:
fields:设置字段选项
Lines: 设置行选项(记录选项)
先看默认值:
字段:
fields terminated by '\t' enclosed by '' escaped by '\\‘记录:
lines terminated by '\n' starting by ''mysql> select * into outfile "E:/outfile4.txt" fields terminated by ',' lines starting by 'start: ' terminated by '===end;\n'from t
eacher_class where id between 2 and 5;
Query OK, 4 rows affected (0.00 sec)
如上所示:fields字段用逗号隔开,lines字段以‘’start:‘’开始,以'===end\n'结束。
mysql> select * into outfile "E:/outfile5.txt" fields terminated by ',' enclosed by 'x' lines starting by 'start: ' terminated by '
===end;\n'from teacher_class where id between 2 and 5;
Query OK, 4 rows affected (0.02 sec)

保存二进制数据,不会发生转移和换行:
mysql> select * into dumpfile 'e:/outfile9.txt' from teacher_class where t_name = '韩信' limit 1
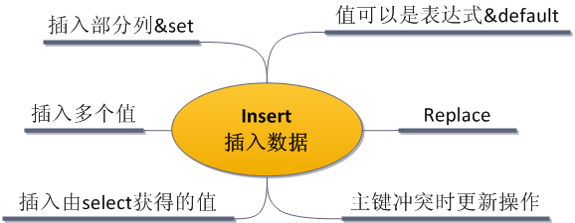
2 新增数据 insert & replace & loaddata
2.1 insert
创建表test_1:
mysql> drop table if exists test_1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> create table if not exists test_1(
-> id int primary key auto_increment,
-> name char(20),
-> sex enum('male', 'female', 'secret')
-> )character set utf8;
Query OK, 0 rows affected (0.08 sec)
mysql> desc test_1;
+-------+--------------------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | char(20) | YES | | NULL | |
| sex | enum('male','female','secret') | YES | | NULL | |
+-------+--------------------------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
Insert 的几种常见用法:
方式一:
可以 省略对列的指定,要求 value() 括号内,提供给了 按照列顺序出现的所有字段的值。
方式一:
可以 省略对列的指定,要求 value() 括号内,提供给了 按照列顺序出现的所有字段的值。
可以一次性使用多个值,采用(), (), ();的形式。
Insert into tbl_name values (), (), ();
Insert into tbl_name values (), (), ();
mysql> insert into test_1 values
-> (null, 'Apple', 1),
-> (null, 'Lin', 2);
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from test_1;
+----+-------+--------+
| id | name | sex |
+----+-------+--------+
| 1 | Apple | male |
| 2 | Lin | female |
+----+-------+--------+
2 rows in set (0.00 sec)
方式二
或者使用set语法。
Insert into tbl_name set field=value,…;
如下所示:
mysql> insert into test_1 set name = 'Qian',sex = 3;
Query OK, 1 row affected (0.01 sec)
mysql> select * from test_1;
+----+-------+--------+
| id | name | sex |
+----+-------+--------+
| 1 | Apple | male |
| 2 | Lin | female |
| 3 | Qian | secret |
+----+-------+--------+
3 rows in set (0.00 sec)
方式三
Insert into tbl_name values (field_value, 10+10, now());方式四
可以使用一个特殊值 default,表示该列使用默认值。
Insert into tbl_name values (field_value, default);
表test_1没有设置默认值,这里就不做展示了,应该时如下的形式;
insert into teacher values
(13, 'xxx', 'yyy', default),//前提是该变量类型设置了default
(14, 'xxx', 'yyy', default(days))//得到字段的默认值
方式五
可以通过一个查询的结果,作为需要插入的值。
Insert into tbl_name select …;如下所示:
mysql> insert into test_1 (name, sex) select name, sex from test_1;
Query OK, 3 rows affected (0.03 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from test_1;
+----+-------+--------+
| id | name | sex |
+----+-------+--------+
| 1 | Apple | male |
| 2 | Lin | female |
| 3 | Qian | secret |
| 4 | Apple | male |
| 5 | Lin | female |
| 6 | Qian | secret |
+----+-------+--------+
6 rows in set (0.01 sec)
注意:test_1中id被设为了主键,如果全部插入test_1中的值的话会造成主键冲突!
方式六
可以指定在插入的值出现主键(或唯一索引)冲突时,更新其他非主键列的信息。
Insert into tbl_name 值 on duplicate key update 字段=值, …;
如下所示(如果直接插入和已有主键冲突的值的话,插入不成功),此时插入的2和已有的主键冲突,将name和sex更新:
mysql> insert into test_1 values (2, 'Blue', 2) on duplicate key update name = 'Blue', sex = 2;
Query OK, 2 rows affected (0.08 sec)数据展示:
mysql> select * from test_1;
+----+-------+--------+
| id | name | sex |
+----+-------+--------+
| 1 | Apple | male |
| 2 | Blue | female |
| 3 | Qian | secret |
| 4 | Apple | male |
| 5 | Lin | female |
| 6 | Qian | secret |
+----+-------+--------+
6 rows in set (0.00 sec)2.2 replace
Replace REPLACE的运行与INSERT很相像。只有一点除外,如果表中的一个旧记录与一个用于PRIMARY KEY或一个UNIQUE索引的新记录具有相同的值,则在新记录被插入之前,旧记录被删除。(替换原有记录)
主键或唯一索引冲突,则替换,否则插入。
此时表test_1中的数据:
此时表test_1中的数据:
mysql> select * from test_1;
+----+-------+--------+
| id | name | sex |
+----+-------+--------+
| 1 | Apple | male |
| 2 | Blue | female |
| 3 | Qian | secret |
| 4 | Apple | male |
| 5 | Lin | female |
| 6 | Qian | secret |
+----+-------+--------+
6 rows in set (0.00 sec)
通过replace向表中插入数据:
mysql> replace into test_1 values(2, 'Green', 1);
Query OK, 2 rows affected (0.03 sec)
mysql> select * from test_1;
+----+-------+--------+
| id | name | sex |
+----+-------+--------+
| 1 | Apple | male |
| 2 | Green | male |
| 3 | Qian | secret |
| 4 | Apple | male |
| 5 | Lin | female |
| 6 | Qian | secret |
+----+-------+--------+
6 rows in set (0.00 sec)2.3 load data infile
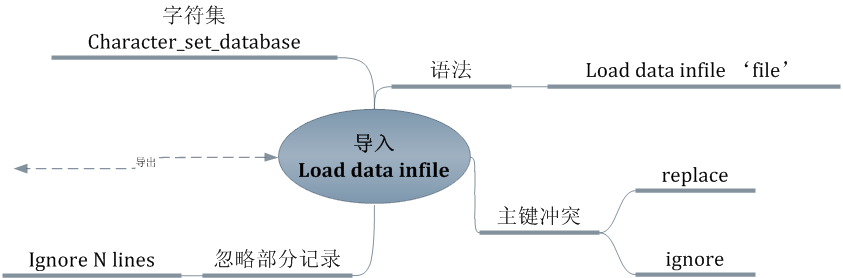
导入:从一个文本内容导入,我们刚刚导出的。
语法:
应该根据数据格式导入,格式语法,默认为:
字段:
其他常用的是:字段使用逗号分割,而使用引号包裹
获取数据的字符集,受character_set_database配置的限制。注意,不受客户端的字符集的影响。
在导入数据时,如果出现主键冲突,可选的:忽略 或 替换。
可以选择在文本文件开始出,忽略若干行再进行导入。
语法:
LOAD DATA INFILE 'file_name.txt' [REPLACE | IGNORE] INTO TABLE tbl_name
[FIELDS [TERMINATED BY 'string'] [[OPTIONALLY] ENCLOSED BY 'char'] [ESCAPED BY 'char' ] ]
[LINES [STARTING BY 'string'] [TERMINATED BY 'string'] ]
[IGNORE number LINES]应该根据数据格式导入,格式语法,默认为:
字段:
fields terminated by '\t' enclosed by '' escaped by '\\‘lines terminated by '\n' starting by ''其他常用的是:字段使用逗号分割,而使用引号包裹
获取数据的字符集,受character_set_database配置的限制。注意,不受客户端的字符集的影响。
在导入数据时,如果出现主键冲突,可选的:忽略 或 替换。
Load data infile ‘file’ Ignore replace可以选择在文本文件开始出,忽略若干行再进行导入。
Into table tbl_name ignore N lines;Load data infile "file" into table tbl_name;通常,可以在导出时,将主键导出成null。利用自动增长的特性。可以形成新的主键:
同样:在导入数据时,需要同样指定数据的分割,起止符号等。保证 导出数据的格式与导入数据需要的格式是一致的即可.
首先当test_1导出,注意,将有主键的一行设置为空:
mysql> select null,name,sex into outfile 'E:/test3.txt'from test_1;
Query OK, 6 rows affected (0.00 sec)
将导出的数据导入到test_1表中:
mysql> load data infile 'E:/test3.txt' into table test_1;
Query OK, 6 rows affected (0.03 sec)
Records: 6 Deleted: 0 Skipped: 0 Warnings: 0
mysql> select * from test_1;
+----+-------+--------+
| id | name | sex |
+----+-------+--------+
| 1 | Apple | male |
| 2 | Green | male |
| 3 | Qian | secret |
| 4 | Apple | male |
| 5 | Lin | female |
| 6 | Qian | secret |
| 7 | Apple | male |
| 8 | Green | male |
| 9 | Qian | secret |
| 10 | Apple | male |
| 11 | Lin | female |
| 12 | Qian | secret |
+----+-------+--------+
12 rows in set (0.00 sec)
mysql>













 2869
2869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









