






笔者最近认识的朋友万力博士(主页:https://www.cs.nyu.edu/~wanli/ ),2009到2015年在纽约大学攻读博士,研究方向神经网络在视觉方面的应用,目前在Google语音组工作。在”机器.算法.人”群里面做了一次精彩分享,这次是他博士研究学习到的东西。题目是Joint Training of Neural Network and Structured Model. 给大家做个总结,确实专业术语比较艰深,不明觉厉的同学收藏吧。


什么是computer vision和vision难在什么地方。博士后期主要是就是做检测:也就是给一个图片。我们要给出什么物体出现在图中,并且给出一个框框来框出物体。这个主要的难度就在于,不知道什么物体(object of interst) 出现(也可以什么物体都没有),和它们都在哪里。
举个例子来说,在1000-class classification 里面,你随便猜测一个标签。猜到的几率是1e-3。但是你在检测,你随便画一个框框,然后说这个是某个物体,你猜对的几率是<1e-6

我认为的理想的模型是一个混合模型:就是神经网络模型+带结构化的模型
这样的话人类知识就可以放进神经网络。这个混合模型的训练套路也是很简单: 1)初始化神经网络 2) 用神经网络的feature来训练后面的模型 3)把后面结构话的模型变为神经网络的layer 4)混合到一起训练。

第一个模型就是lda +nn的模型用来做分类。

这个模型就是把图模型(graphical model)的输入接上神经网络(nn)的输出。这样graphical model就直接用nn的feature而不是raw feature.
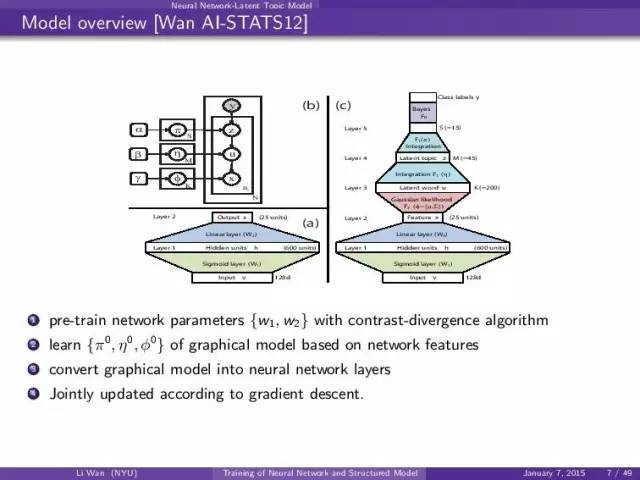
这个就是一个混合模型的例子: (a) input-> nn (b) nn-> graphical model 。
(c)是把graphical model转化成nn的layer然后接到下面的,构成一个大的网络。
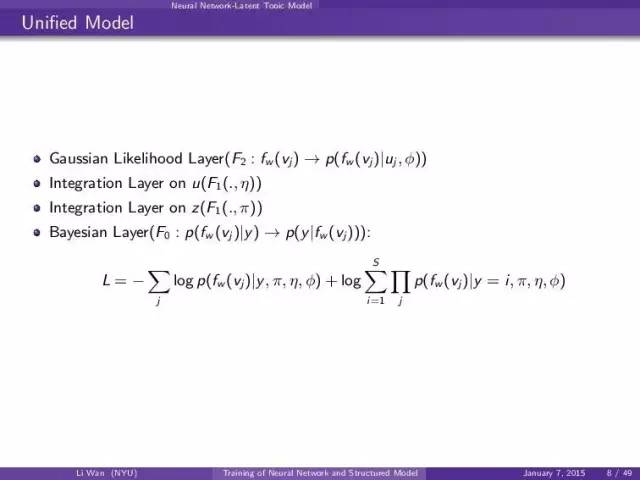
这个就是定义一些特殊的nn layer使得inference的时候能够估计那个上面的graphical model inference process。
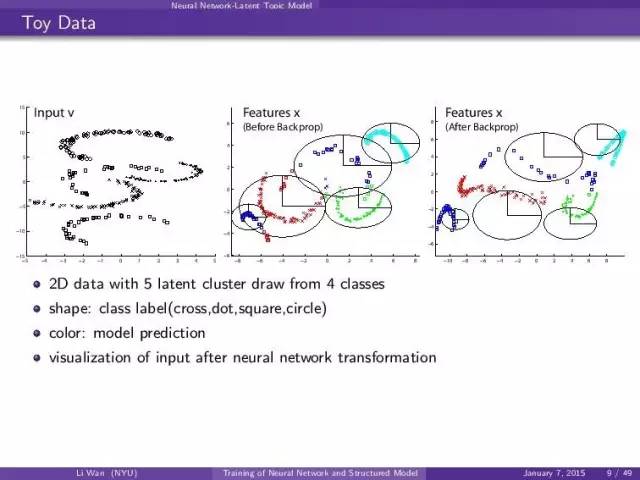
一个简单的例子:
一个2维数据,然后是4个label, 5个latent class。
左一图:注意两个框框在最左边的图是一个类。 我们要用mixture gaussian 来discriminate 这4个类。
中间图:上nn 的pre-train然后用nn的feature来train mixture gaussian的时候,我们看到了好多error。
右边的图:end-to-end training 的时候。mixture gaussian可以很好的“分开” ( p(y|x) 而不是p(x) ), 5个latent clusters。你看nn就可以把data transform到上面想要的形状。
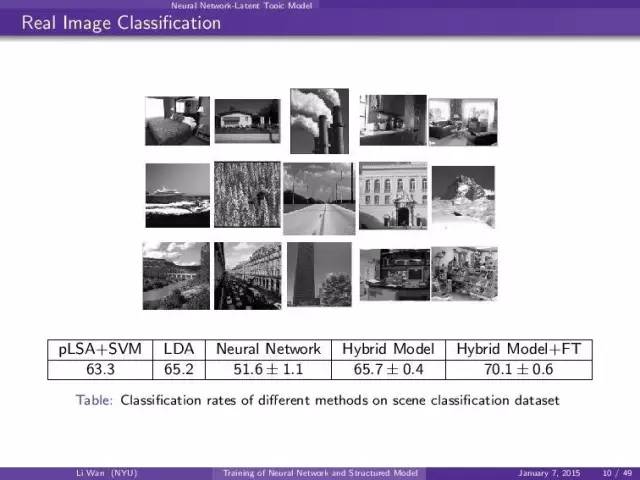
real image scene classification结果:


NYU pascal2011 detection winner 的模型。我是和一个纽约大学的博士后做的,叫: Leo Zhu(朱珑),还有一个叫陈远浩。现在LEO是《依图》公司的老板。他2012年底回国创业了。现在做的很棒的:)

就是pascal detection model:
用一个树来解释一个物体:root -> 3x3 part , part -> 2x2 subpart. 然后这些part, sub-part可以在inference的时候自由移动。这个就是机器视觉 里面的标准DPM的扩展。
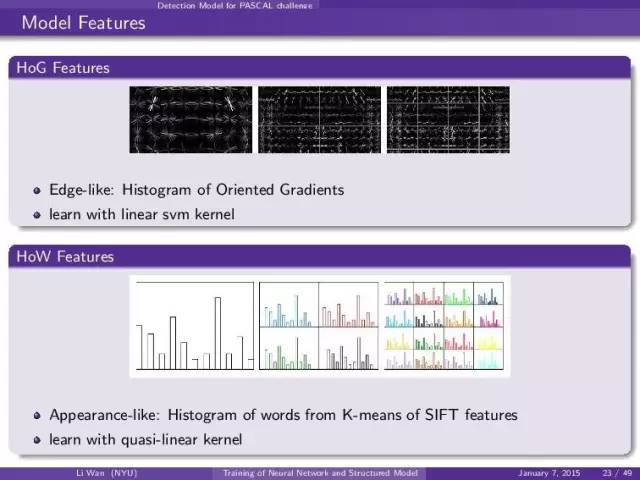
我们先用普通的机器视觉feature: HoG, SIFT, LBP 等等。然后我们上svm 不同的feature 用不同的kernel。(这个都是标准做法)

检测后处理:
在检测里面,每一个框框都对应的一个model score。然后我们一个物体只留一个框。也就是说左图的紫色框框要被拿掉,如果蓝色框框model response大于紫色的。

Iterative NMS就是说把nms 过程推广成k-means的算法。包括了算中点,和算assignment。这个算法在pascal 2011的时候提高了2-3个点。非常有效。

所以我们总结下pascal 2011 NYU (detection winner)算法:
1 image feature: sift+hog+lbp
2 hierarchical part-based model
3 improved NMS

然后我们开始拓展这个算法:
- 先把feature 换成convent
- 然后把part-based model 和convent连起来
于是就有了我们slide 27: end-to-end integration of convent, dpm, 和nms
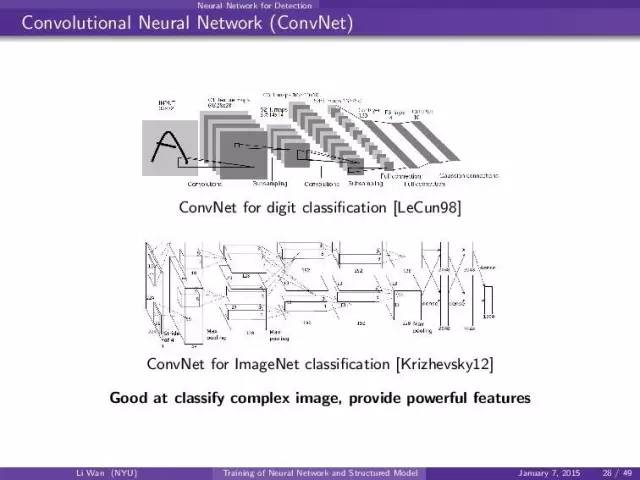
典型的convnet结构做classification: (conv, pool, non-linear) * k + fully connect layer + softmax

dpm的例子,一个物体用root+part表示,在inference 的时候part可以随便基于root动。但是传统的DPM只能用hog。

把两个模型的长处连起来了: convnet: power feature, dpm: represent object part explicitly。
如果要连接,我们要解决如下问题:
- convnet的output怎么去连dpm
- dpm怎么写成nn 的layer.如何定义fprop/bprop/update
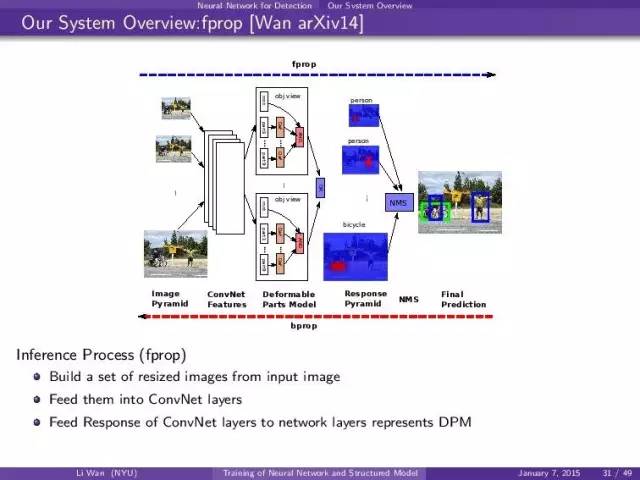
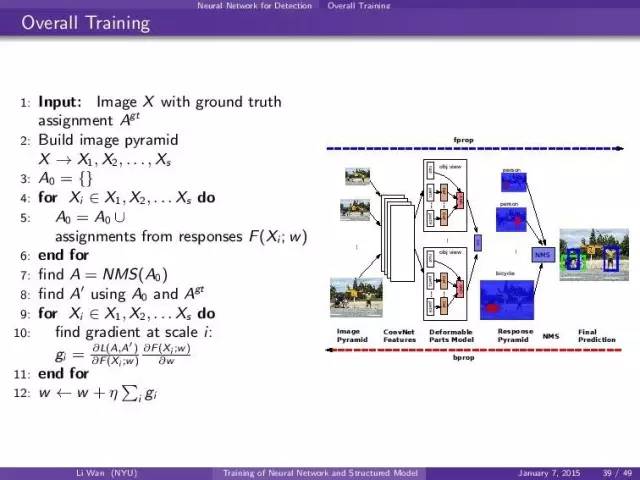
我们的系统:
- 建立image pyramid,就是把原来的图片按比例缩小,得到一堆图片
- 每一张resized image都进convent
- convnet feature进dpm
- nms 基于dpm output,就是response pyramid.
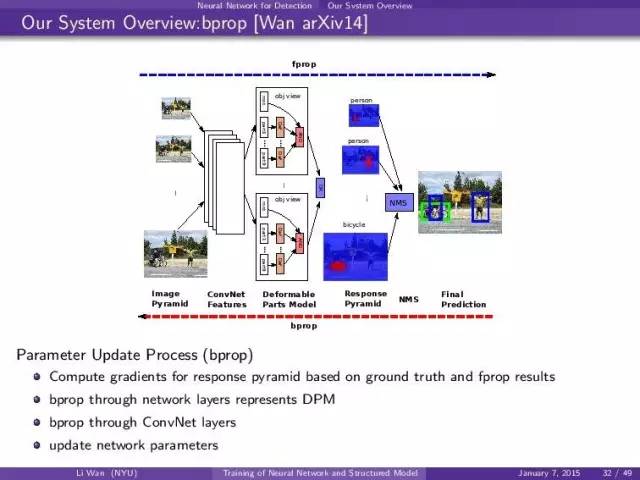
反过来,基于response pyramid grad (后面会讲怎么从fprop和label算),然后反过来推grad。dpm layers -> convent 。然后update gradient。
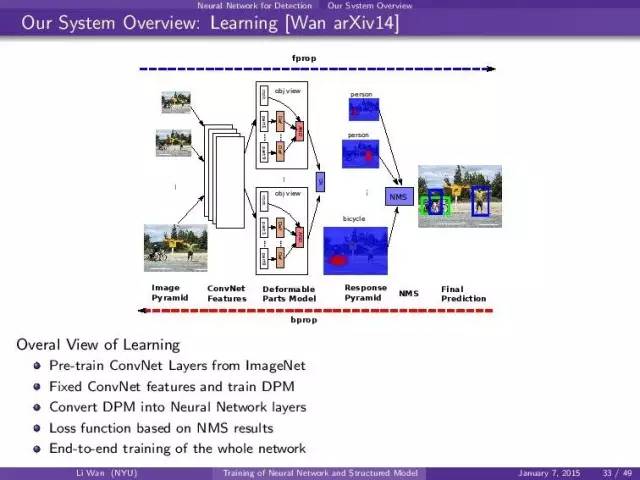
一张图知道了,然后大的想法也是和开始提出的一样:
- pre-train nn, dpm
- convent dpm -> neural network layers
- define loss function based on nms
- perform end-to-end training
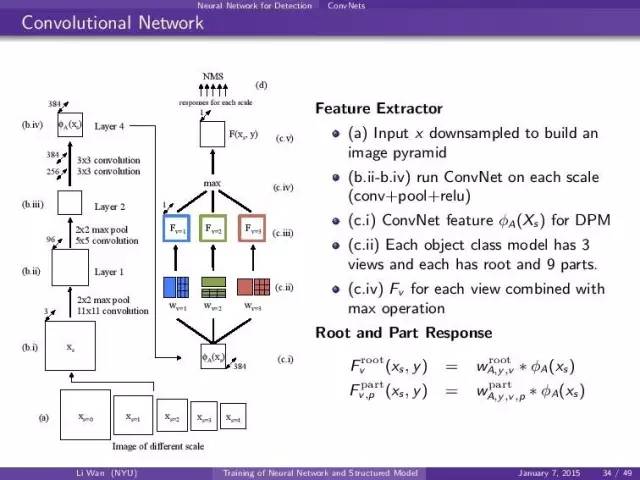
convnet结构,同样的网络可以进不同大小的image,然后root, part的filter都是基于shared。
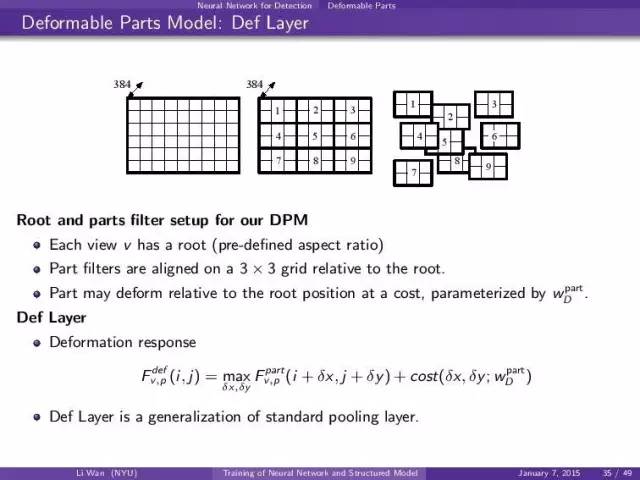
Def Layer描述part deformation from root。
其中每一个part有一个default location (i,j)在inference 的时候可以move (dx, dy)。花费的代价是cost(dx,dy,w)其中这个参数也是可以学的。
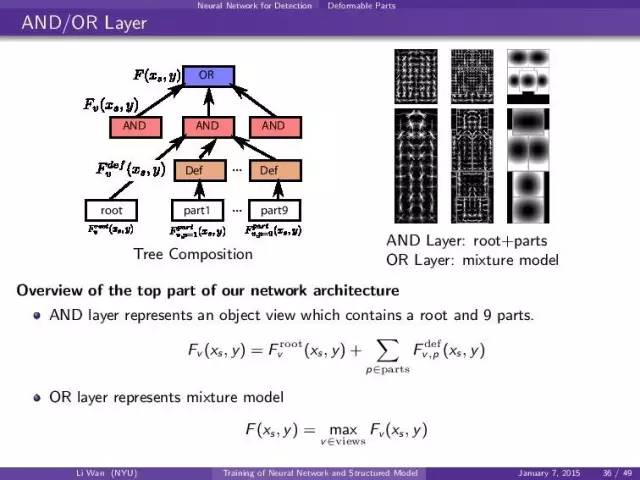
tree representation of AND-OR model,描述mixture model of obj with root and part。
比如,一个“人”的模型是可以包括1)人的全身2)人的半身,那么就是or node做的。
然后每一个人的模型都是一个root+ 很多的可以def的part。这个就是and node
其中and, or, def我们都可以定义fprop/bprop/update那么就是写成了神经网络的layer。

loss function, 对于一个人包括绿色框,蓝色框和红色。这个情况下蓝色才是对的。但是红色和绿色的框不是negative example因为在有些情况下(这有半身的人)。红色和绿色可以是positive exmaple。对于传统的detection算法就是完全不用绿色和红的的框。
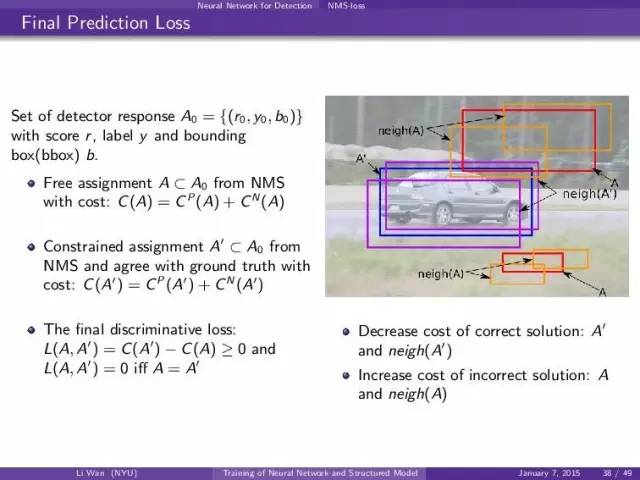
这里就是要注意对每一个image slice 做fprop然后一起算gradient,然后bprop。然后一个网络对每一个image slice都要做fprop/bprop。所以最后的gradient就是所有gradient 之和g_i。
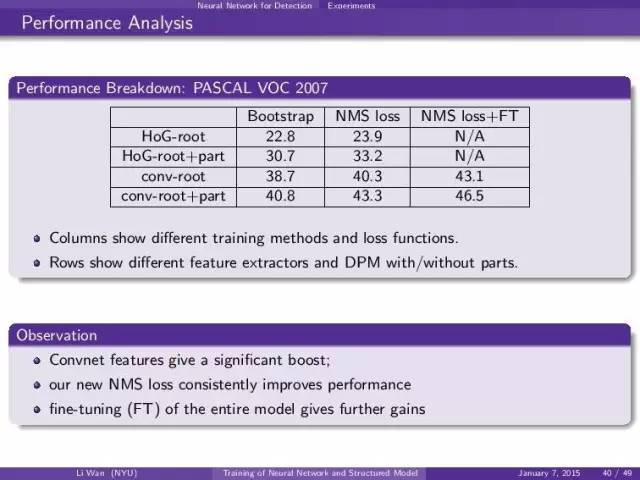
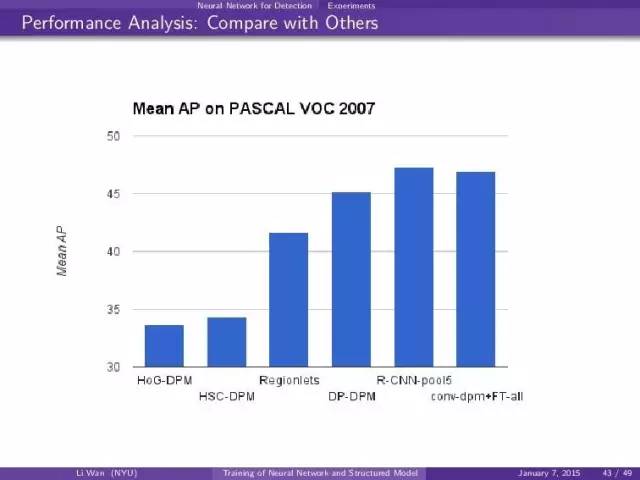
可以看出几个优势:
- convnet feature > HoG
- root+part model > root model
- NMS loss function 比传统的loss好 (第2个column是没有做convnet update的结果)
- end-to-end的效果最好 NMS loss+FT就是end-to-end training. (第3个column)
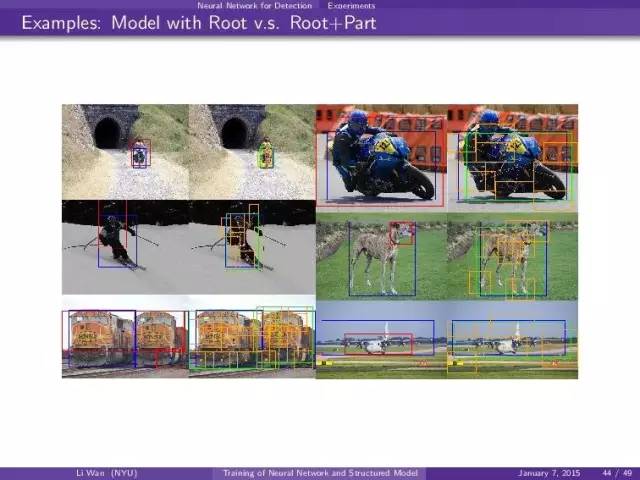
其中蓝色是true label。绿色是root filter, 黄色是part filter position。
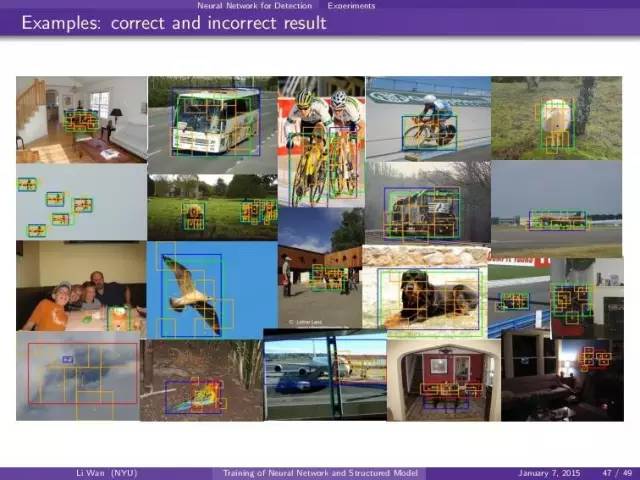
总结:
hybrid model = nn+ structured model
Training 1) pre-trian both 2) convert structured model into nn layers 3) perform end-to-end training
然后这个想法被应用在image classifciation = nn + lda, object detection = nn + dpm + nms上了。

投稿人:董飞,本科毕业于南开大学,硕士毕业于杜克大学计算机系毕业。在攻读硕士期间,先后在VLDB,SOCC等顶尖数据库大会发表论文。先后在创业公司酷迅,百度基础架构组,Amazon 云计算部门,Linkedin担任高级工程师,负责过垂直搜索引擎,百度云计算平台研发,广告系统和在线教育平台的架构。在大数据领域业界研究多年,涉及Hadoop调优,分布式框架,Data Pipeline, 实时系统。
责编:钱曙光,关注架构和算法领域,寻求报道或者投稿请发邮件qianshg@csdn.net,另有「CSDN 高级架构师群」,内有诸多知名互联网公司的大牛架构师,欢迎架构师加微信qshuguang2008申请入群,备注姓名+公司+职位。














 3267
3267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









