






EDA(探索性数据分析)最常用的过程步之一就是PROC UNIVARIATE。
首先先看一个最简单的PROC UNIVARIATE程序:
PROC UNIVARIATE DATA=SASHELP.FISH;
WHERE SPECIES='Bream';
VAR HEIGHT;
RUN;
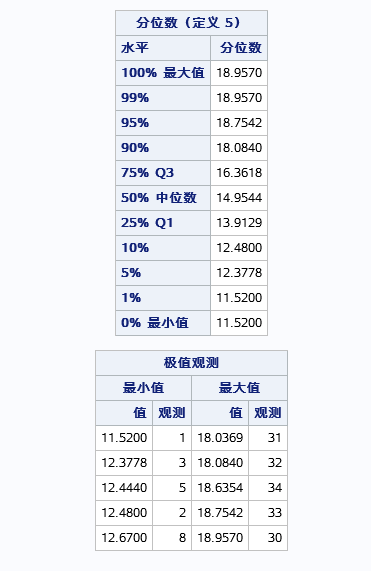
上述代码得到的结果有:矩、位置和可变形的基本测度、位置检验、分位数、极值观测。具体如下:
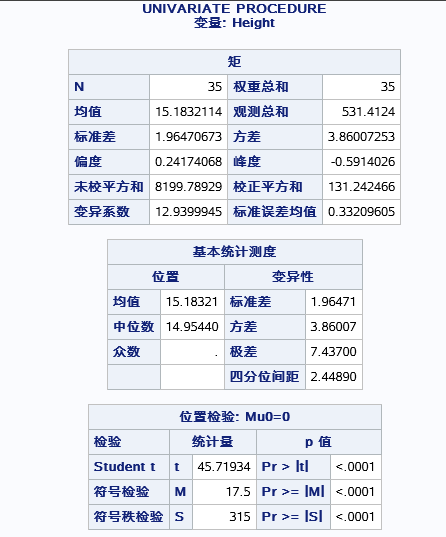
解读:首先看第一张表——矩,其中N=35代表该进入分析变量有35条观测,偏度约0.2稍微有点负偏态(右偏),变异系数12(不大也不小,无法得出结论),峰度系数-0.6(低峰后尾);
第二张表:位置和变异性的基本测度,其中位置的统计量有均值(15.1),中位数(14.9)还是比较接近,所以近似对称分布。变异性即数据的差异性程度(标准差越大差异越大。)
PROC UNIVARIATE DATA=SASHELP.FISH;
WHERE SPECIES='Bream';
VAR HEIGHT;
HISTOGRAM ;
RUN;
若加了一个HISTOGRAM则增加了一个直方图,如下:

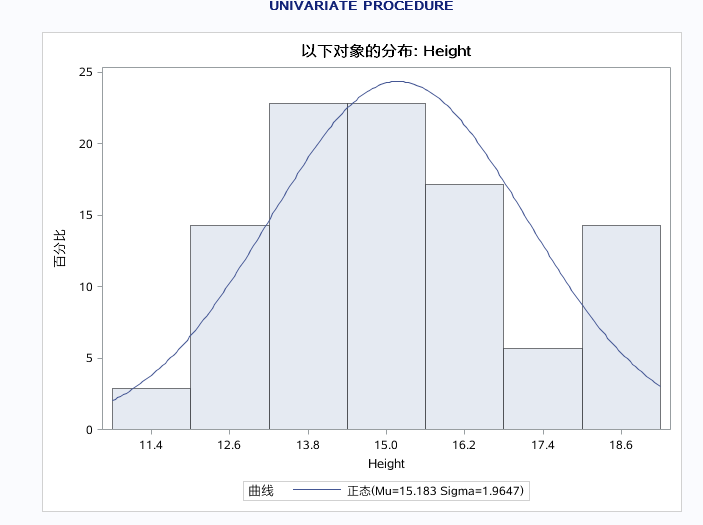
如加一个NORMAL选项则在直方图上面加了一根拟合后的正态分布图,并且还增加了拟合正太分布的参数估计、拟合优度、分位数,这里的括号中的意思可理解为均值(MU)和标准差(SIGMA)的值为原始数据本身的均值和标准差;
PROC UNIVARIATE DATA=SASHELP.FISH;
WHERE SPECIES='Bream';
VAR HEIGHT;
HISTOGRAM /NORMAL(MU=EST SIGMA=EST);
RUN;

PROC UNIVARIATE DATA=SASHELP.FISH;
WHERE SPECIES='Bream';
VAR HEIGHT;
HISTOGRAM /NORMAL(MU=EST SIGMA=EST) KERNEL;
RUN;
加了一个KERNEL则在直方图中加了一根实际数据核分布的密度曲线,如下图:

PROC UNIVARIATE DATA=SASHELP.FISH PLOT;
WHERE SPECIES='Bream';
VAR HEIGHT;
HISTOGRAM /NORMAL(MU=EST SIGMA=EST) KERNEL;
RUN;
上述加了一个plot选项,在结果中增加了分析变量数据的分布图、盒形图、以及概率图,如下:

由概率图看出,散点分布的直线上下,还算是比较重合,所以该数据近似服从正态分布的。
暂时就会这么多了。。以后再补。














 1810
1810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









