







一、列表(list)
1.列表的内置函数为 list 。列表可以是普通列表、混合列表,也可以是空列表,列表中可以添加列表。列表内容可以是整数,可以是浮点数,也可以是字符串。元素的位置是从“0”开始的。
2.新建列表:
新建列表 变量 = []
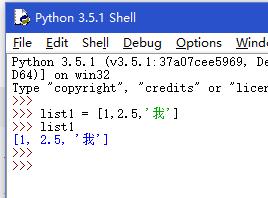
3.len() 函数可以获取列表元素的个数

4.用索引访问列表中每一个元素的位置列表[位置]
A.可以正向搜索(默认起始位置为“0”)
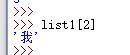
B.也可以逆向搜索(默认起始位置为“-1”)
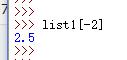
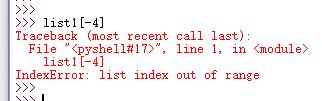
当索引超出了范围时,Python会报一个IndexError错误。
5.更改列表中的元素
A.在列表中,可以通过 .append 方式增加元素到末尾位置。

B.通过 .insert() 方法增加元素并指定其在列表中的位置
list.insert(位置,’增加的元素’)

C.通过 .pop() 方法删除列表中的元素
列表.pop(),默认删除最后一个元素
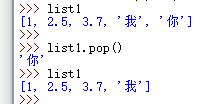
由于 pop() 有返回值,因此可以采用赋值的方法,倒序删除

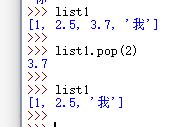
列表.pop(位置),删除指定位置元素
D.替换元素,可以直接将新元素赋值给指定位置

E.列表的扩展,将多个元素加入列表中
列表.extend([])

列表的扩展应采用 变量“点” extend([]) 的方式,不要采用 + (连接操作符)的方式,会出现违规操作,因为 + 两边的元素必须一致。
F.列表页可以包含列表,要定位被包含列表中某一位置的元素,可以采取 列表[包含列表位置][被包含列表位置] 的方法

或 被包含列表[位置] 的方法

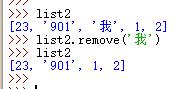
G.变量.remove(元素名称) 知道元素名称进行删除
H.delete 方法
del列表[元素位置]
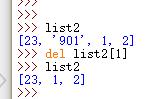
或者 del空格列表赋值的变量,整个列表被删除
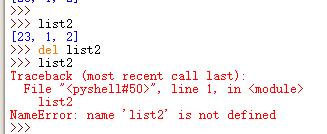
最后提示“没有这个列表”,表示删除成功
6.一个元素的列表,调用元素种类读取。

7.切片
为了一次性获取列表中更多的元素,可以采用 切片/分片/slice 的方法
A.切片,通过分号隔开索引值,复制列表。其中,冒号左边为开始(包含开始索引值),冒号右边为结束(不包含结束索引值)。

B.同理,可以在开始位置或是结束位置不填写索引值,则复制的列表包含开始/结束的位置;也可以只填写冒号,获取整个列表的复制。

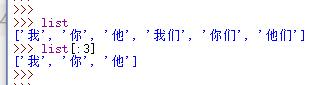

C.切片是复制整个列表,所以适用于需要修改列表同时又要保留原列表的情况;赋值是元素值完全相同的两个列表。

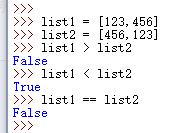
8.列表比较大小
列表比较大小,是以索引值第 0 个位置的大小判定, 0 位置的索引值大,当前列表就大,反之亦然。
9.列表相乘,列表中元素数量增倍,但是数值不变。

10.成员关系操作符
通过 in 和 not in 确定成员关系
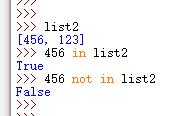
对于确定列表中的列表的成员关系,应当在一层列表中引入二层列表

11.列表内置函数(BIF)及部分常用内置函数(BIF)
dir(list)

A.count():用于计算某元素在列表中出现的次数
列表.count(需要查询的元素)

count(sub[,start[,end]]),start 表示此位置之前的舍去(不含此位置),end 表示此位置之后的舍去(不含此位置)。

B.index():返回参数在列表中的位置。
列表.index(需要查询位置的元素)
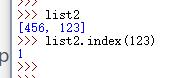
如果一个列表中有多个相同的元素分布在不同的位置,Index默认只查找第一个元素的位置,可以划定位置范围查找其他相同元素(只找排列在最前面的)。

列表.index(需要查找位置的元素,查找起始位置,查找结束位置)
C.reverse():将整个列表原地反转,前后的值互相调换位置。
列表.reverse()

D.排序
sort():默认从小到大进行排队
列表.sort()

如果列表需要从大到小排序,可以先通过 sort 从小到大排序,再用 reverse 反转;另外还有一个方法是调用 sort 中的 reverse 参数
列表.sort(reverse = True)

.sort(reverse) 中的 reverse 默认值是 False,所以要改为 True 。
二、元组(tuple)
1.新建一个元组,与字符串不同,元组内的元素要加上英文逗号。tuple 一旦初始化,元素指向不能改变。

2.tuple 陷阱:
当定义一个只有一个元素的 tuple,如果如下图定义,则定义的不是 tuple,只是一个数,这是因为括号()既可以表示 tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python 规定,这种情况下,按小括号进行计算,计算结果自然是1。
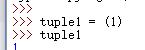
所以,只有1个元素的tuple定义时必须加一个英文逗号消除歧义。

3.“可变的”元组
例:
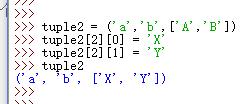
tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向’a’,就不能改成指向’b’,指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
所以,如果需要建一个“不可变”的元组,那就需要元组内的每一个元素都是“不可变”的。

4.数字乘以元组,* 相当于重复操作符,不再有乘法意义。

5.删除元组
del元组
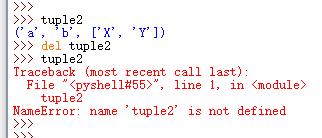
6.适用于元组的操作符
1.拼接操作符
2.重复操作符
3.关系操作符(>、<、 ==、!=)
4.逻辑操作符(and、or、not)
5.成员操作符(in、not in)
三、序列
1.列表、元组和字符串的共同点
A.都可以通过索引得到每一个元素;
B.默认索引值总是从零开始;
C.可以通过分片的方法得到一个范围内的元素的集合;
D.共用重复操作符、拼接操作符、成员关系操作符。
2.生成空列表
>>> a = list()
>>> a
[]
3.将字符串转换为单独列出的列表
b = 'Python'
>>> b = list(b)
>>> b
['P', 'y', 't', 'h', 'o', 'n']
4.将元组转换为列表
b = (1,2,3,4,5)
>>> b = list(b)
>>> b
[1, 2, 3, 4, 5]
5.将列表转换为元组
b = [1,2,3,4,5]
>>> b = tuple(b)
>>> b
(1, 2, 3, 4, 5)
6.max(sub) 返回序列或参数集合中的最大值(数据类型必须一致)
>>> c = (11,23,56,3,789)
>>> max(c)
789
7.min(sub) 返回序列或参数集合中的最大值(数据类型必须一致)
>>> min(11,23,56,3,789)
3
8.sum(iterable[, start=0]) 返回序列 iterable 和可选参数 start 的总和(可以是数据类型(整数、浮点数),字符串不能实现此操作)
A.sum(iterable)
>>> d = (1,2,3,4,5)
>>> sum(d)
15
B.sum(iterable,star)
>>> d = (1,2,3,4,5)
>>> sum(d)
15
>>> sum(d,15)
30
9.sorted() 默认由小到大排序
>>>c = (11,23,56,3,789)
>>> sorted(c)
[3, 11, 23, 56, 789]
10.reversed() 返回迭代器对象 ,如果将 reversed 表示的迭代器对象返回为列表,可以通过 list() 或是 tuple() 。
>>> c = (11,23,56,3,789)
>>> reversed(c)
<reversed object at 0x00000238FF8811D0>
>>> list(reversed(c))
[789, 3, 56, 23, 11]
>>> tuple(reversed(c))
(789, 3, 56, 23, 11)
11.enumerateenumerate() 枚举,生成由每个元素的 index(索引) 值和 item 值组成的元组。
>>> enumerate(d)
<enumerate object at 0x00000238FF884EA0>
>>> list(enumerate(d))
[(0, 1), (1, 22), (2, 345), (3, 43), (4, 576), (5, 60)]
>>> tuple(enumerate(d))
((0, 1), (1, 22), (2, 345), (3, 43), (4, 576), (5, 60))
元素前面都加了元 其所在列表的索引值
12.zip() 返回由各个参数的序列组成的集合。
A.
>>> e = (11,23,41,36,77,90)
>>> f = (43,76,45,22,11,489,123,65)
>>> zip(e,f)
<zip object at 0x00000238FF880F88>
>>> list(zip(e,f))
[(11, 43), (23, 76), (41, 45), (36, 22), (77, 11), (90, 489)]
>>> tuple(zip(e,f))
((11, 43), (23, 76), (41, 45), (36, 22), (77, 11), (90, 489))
B.
>>> e = [11,23,41,36,77,90]
>>> f = [43,76,45,22,11,489,123,65]
>>> zip(e,f)
<zip object at 0x00000238FF888548>
>>> list(zip(e,f))
[(11, 43), (23, 76), (41, 45), (36, 22), (77, 11), (90, 489)]
>>> tuple(zip(e,f))
((11, 43), (23, 76), (41, 45), (36, 22), (77, 11), (90, 489))
成对打包,元素相对多的集合,多出来的元素舍弃不要。
From:http://blog.csdn.net/komazhy/article/details/51911617















 744
744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









