







摸索openstack一段时间了,我们自己数据中心也搭了一套。今天分享给大家,有不妥的地方还望列为技术大师不吝赐教。
关于openstack架构等相关概念就不在这介绍了(这些东西资料一大坨,都被说烂了)。
先来看看我们的系统资源吧,我们的环境中有100台物理服务器,磁盘RAID采用raid 5,之前曾尝试过raid 6,发现对性能的损耗很大,得不偿失啊。服务器都是双网卡,eth0跑虚拟机业务,eth1跑数据业务。
我们是基于openstack的F版本进行开发部署的,再来看一下我们的openstack部署架构吧。
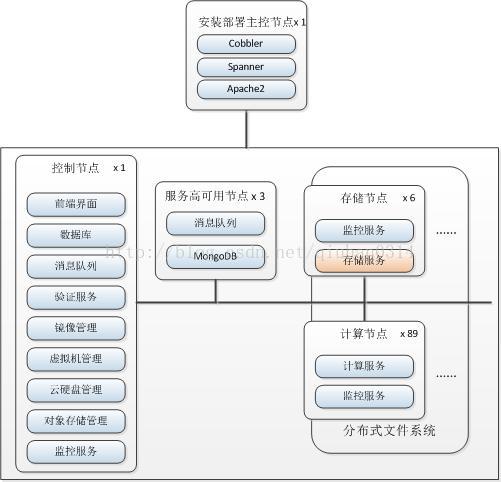
- 安装部署主控节点
安装部署主控节点用于对openstack进行自动化的批量部署,其中spanner为我们团队自编写的可视化的用于批量安装脚本。
- 控制节点
控制节点充当着全部节点的“大脑”,安装了除nova-compute外的全部服务,其中包括:前端界面(horizon),数据库(mysql),消息队列(rabbitmq),验证服务(keystone),镜像管理(glance),虚拟机管理(nova),云硬盘管理(cinder),对象存储管理(swift),监控服务(ceilometer)。控制节点全部服务安装在1台物理服务器上。
注:这里的虚拟机管理服务(nova)开启了除nova-compute之外的全部nova服务
- 存储节点
存储节点用于存储虚拟机实例(nova-instance)数据、对象存储(swift)或块存储(cinder)数据。存储节点用6台物理服务器组成glusterfs分布式共享存储集群,采用写一份数据写一份副本(replica=2)的存储策略,建立3个卷(volume),分别挂载到nova-instance、swift、cinder的数据存储目录。关于glusterfs的详细介绍大家可以看我博客中的其它文章。
- 计算节点
计算节点是一台一台虚拟机的宿主机们,理论上每个计算节点上只需要安装nova-compute服务即可。但在我们的环境中,考虑到控制节点,特别是当nova-api及nova-network服务都只部署在控制节点上时,其承载的压力过大,而且容易发生单点故障。所以我们在计算节点上同时安装部署了nova-api和nova-network服务,采用这种分布式的方式部署后,nova-api和nova-network都指向计算节点本身的nova-api和nova-network服务,而不再指向控制节点的nova-api和nova-network服务。以nova-network为例,每个虚拟机实例出口网关不再是控制节点的相应网卡,而是其宿主机的相应网卡。关于这点有兴趣的读者可以看我上一篇文章。
- 服务高可用节点
服务高可用节点主要是针对消息队列负载过大和单点故障情况,应用HAProxy及keepalived对消息队列服务进行负载均衡。后台采用mongodb存储监控数据,以提高查询效率。














 6161
6161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









