






从一个 bug 说起
某天产品反馈了一个问题,业务一页面的富文本展示有问题,管理后台输入的是 a<b<c,但最终页面只展示出 a。定位发现富文本渲染存在一个问题逻辑,它针对管理后台输入的 HTML Entity 字符做了还原,在输入一些类似 HTML 标签的字符时,浏览器在展示时将输入识别成 HTML 标签,结果这部分字符便凭空消失。
此处的富文本渲染流程:
HTML 输入 --> Entity decode --> dangerouslySetInnerHTML --> DOM --> 最终 UI
当 HTML 输入类似这样的格式: <p>a<b<c</p>,Decode 以后它变成了 <p>a<b<c</p>,导致后面的 <b<c 被识别成了 HTML 的 Tag,只留下 a 在节点中:
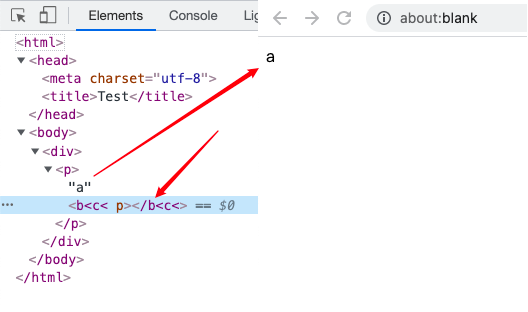
解决这个问题,最直接的办法自然是拿掉 Entity decode 这一步骤,但实际操作时陷入一尴尬境地:这段逻辑属于积淀多年的历史代码,被众多地方引用,改动影响范围过大,且带来很大的测试工作量,不敢轻举妄动。
从稳妥的角度出发,既然难以干掉,在有机会赶上大规模测试前,那么是否可以先简单上一个对冲的机制?以此抵消 Entity decode 的作用,产生预期内的 UI 效果;并把改动控制在问题模块内,不影响到其他引用此渲染逻辑的模块,从而让测试工作量变得可控。
修改后的富文本渲染流程类似:
HTML 输入 --> 【特殊处理】 --> Entity decode --> dangerouslySetInnerHTML --> DOM --> 最终 UI
实验表明,确实可以!
理论学习
关于这个【特殊处理】逻辑的实现,直接针对会出问题的场景做个替换,是最朴实简单粗暴的想法。但这本身治标不治本,且还带着引发新的问题的担忧。我们能否从本质角度,一次处理完所有可能的 case?
HTML 存在的意义,并非它各种奇奇怪怪的语法,更核心的点在于描述要让浏览器构造一个什么样的 DOM 树,所以我们的关注点放在浏览器解析 HTML 的过程上。根据 WHATWG 的文档,结合一点点的编译原理知识,可以明确这里基本的工作模式:读取输入字符流,然后通过 Tokenizer(词法分析器)分析词法结构,构建起 DOM。
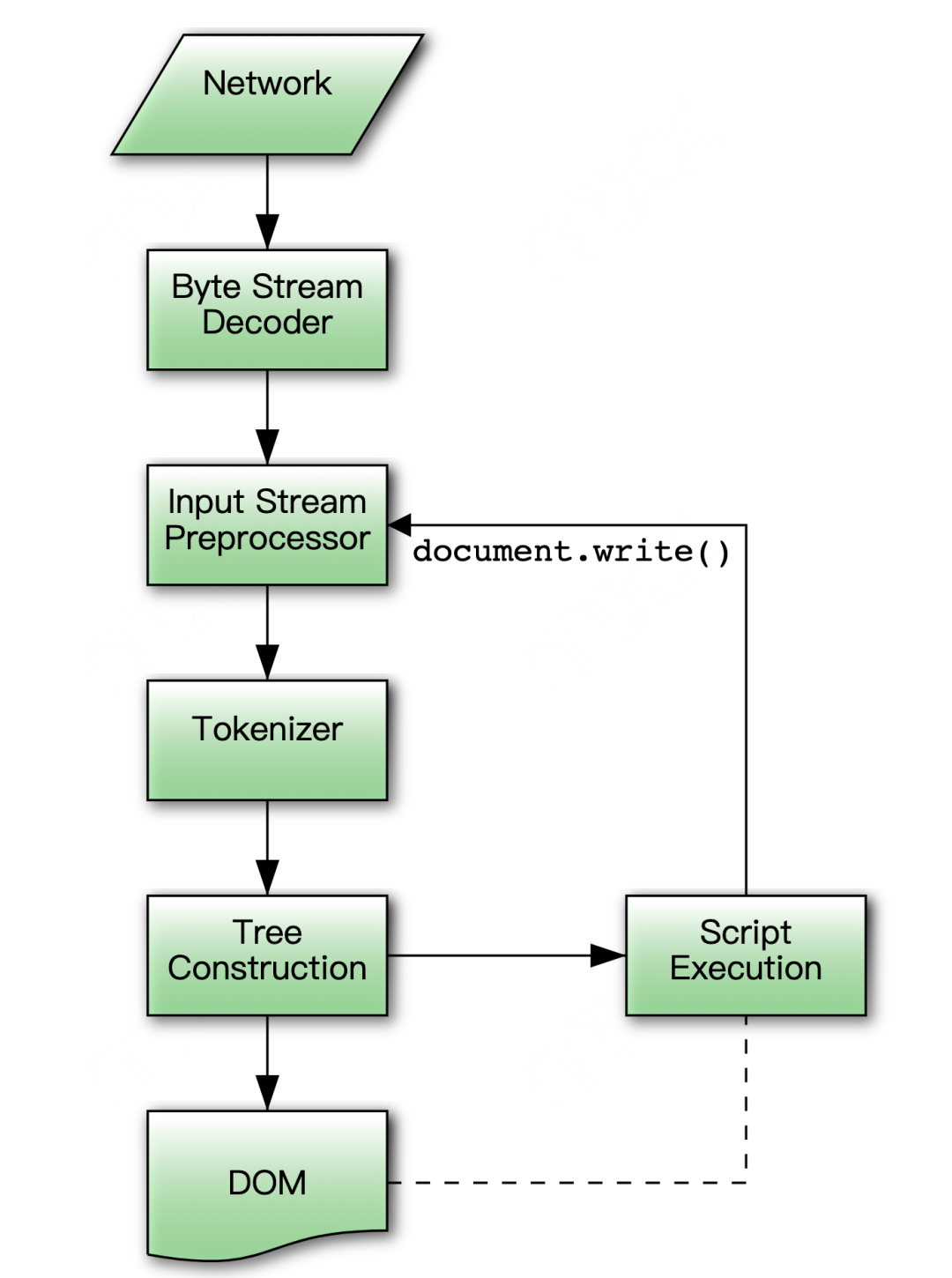
Tokenizer 分析的过程,涉及到「有限状态机」的概念。大致来说,Tokenizer 内部维护了一个状态机,定义了 HTML 解析过程涉及到的所有状态,从前往后一个个读取字符,一步步跳转到不同的状态。浏览器引擎也专门在内部维护了一套 DOM 树,当解析状态机进入其中的特定状态,状态机产生新的 Token,触发 Tree Construction 步骤,填充完善 DOM 树结构。当字符流读取结束,DOM 树也最终确定下来。
WHATWG HTML5 文档 为我们提供了完整的解析流程与状态机定义。其中与这里的标签解析场景相关最关键的是 Tag open state 与 End tag open state。解析器从 Data state 状态开始,输入下一个字符是 < 时,状态进入 Tag open state 状态。紧接着下一个字符的输入非常关键,决定了是否开始按照标签解析。
由定义文档了解到,Tag open state 的下一个输入可能跳转的状态分为以下 6 种情况:
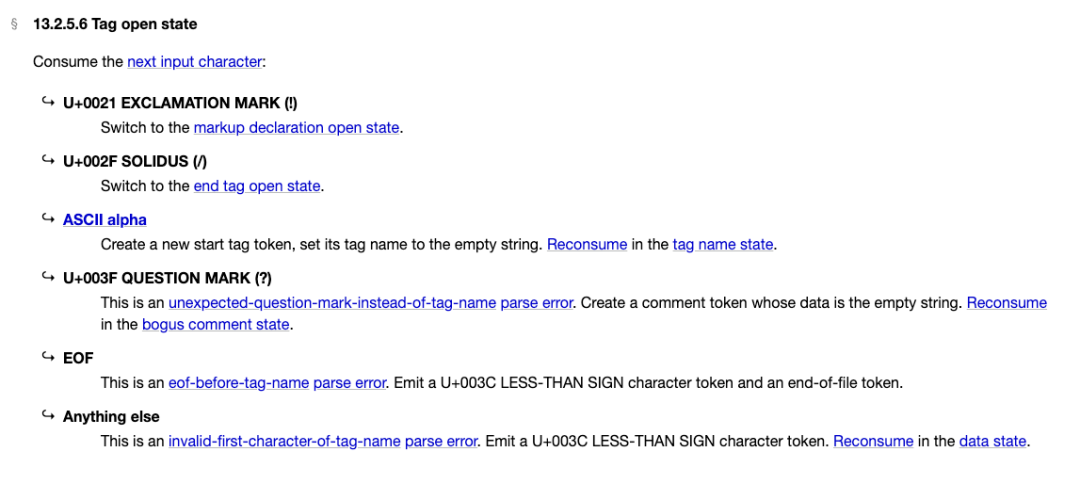
其中 U+xxxxF 代表的是十六进制 Unicode 字符,我们可以适当放弃一些极度精确的严谨性,从直观的角度我们大体可以这么展开:
!感叹号:跳转到markup declaration open state(针对<!DOCTYPE html>/ <!-- 注释 --> /<[CDATA[等情况)/斜杠:跳转到end tag open state(针对关闭标签场景,如</div>)ASCII 大小写字母:进入
tag name state,按照标签解析?问号:解析异常,产生一个空的注释节点,转向bogus comment state重新解析(Reconsume,注释继续包含?号)EOF 结束输入:输出
<号(此时没有更多的输入了)其他情况:输出
<号(此时产生一个invalid first character of tag name异常信号,但不影响工作)
从文档看,只要我们保证 < 以后不出现情况 1-4,Tokenizer 就不会进入标签解析的状态,不产生新的节点,直接展示原文,也就避免了标签结构不匹配导致显示不完全的情况。
hack 实战
从理论上可以跑通,现实落地中我们如何快速验证这个想法、确认合适的字符串替换方案呢?除了写一些 HTML 代码通过不断编辑 - 刷新验证外,还可借助 DevTools Elements 面板的 Edit as HTML 功能去实时编辑调试。
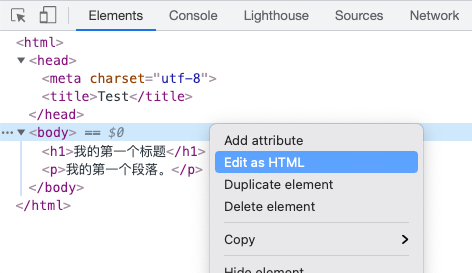
但这都不够直观,只靠观察与猜测还是有些繁琐。我想要做的是针对 WHATWG HTML5 标准解析器的 hack,WHATWG HTML5 Spec 既然是一个标准,或许会有人会基于此做一些不依赖浏览器的 HTML5 解析方案?带着这个问题,简单搜索了下,发现针对 Node.js 做的 HTML5 代码解析器 parse5;顺着项目主页的 Online Playground,还找到一个叫 AST Explorer 的网站。好家伙!这下可以直接观察某 HTML 文本所产生的 DOM 树了,感谢社区。
以这段代码为例:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Test</title>
</head>
<body>
<h1>我的第一个标题</h1>
<p>我的第一个段落。</p>
</body>
</html>
通过 AST Explorer,这段代码产生的 DOM 树的细节可以说是一览无余:
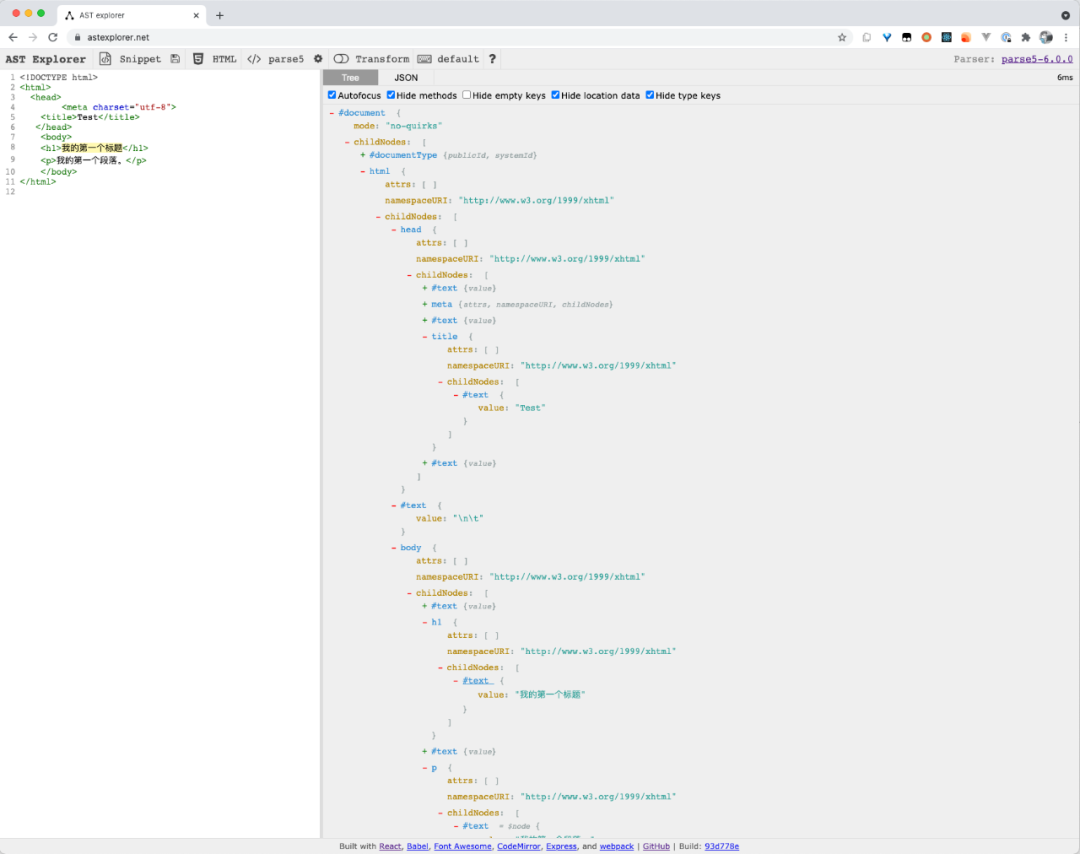
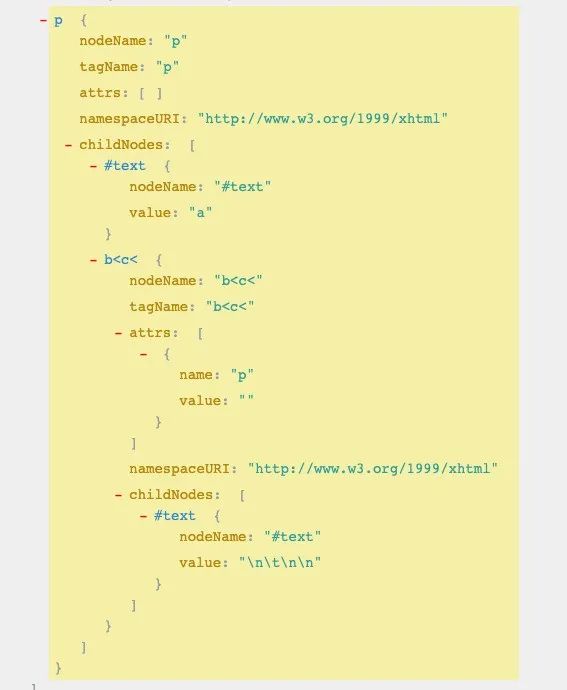
输入有问题的 <p>a<b<c</p>,观察发现其产生的是一个名为 b<c< ,带一个 p 属性的节点,与标准文档的描述一致。
继续脑洞替换策略:原则上不希望影响 UI;我们在 < 与会产生 tag 的字符之间,加一个不会在渲染树产生节点的空注释节点即可,效果如下。
HTML 输入:<p>a<b<c</p>
效果:
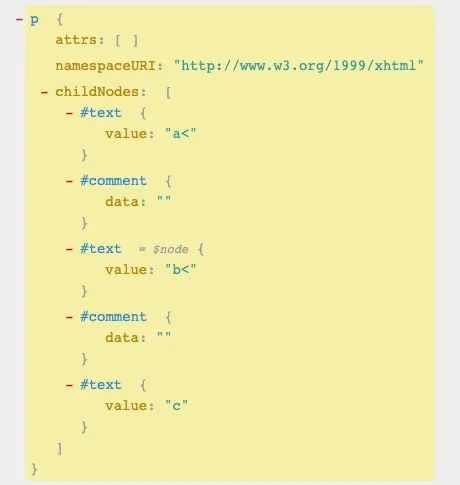
显示也符合预期:
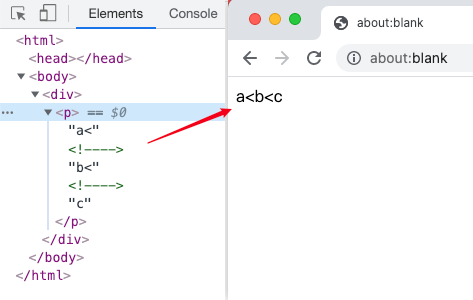
篇幅有限,其他几种情况生成的 Node 暂且不表(<! / <? / </,以及它们的组合),有兴趣的读者可以自行尝试 :P
再补充完善一些关于 Entity 的细节,得到最终解决方案,在实体编码前加上这么一道字符串正则过滤(因为是 hack 代码,需要写上足量的注释,避免未来翻车):
/**
* 根据 whatwg 的状态机,解析到 "<" 时会进入 Tag open state
* 下一个字符若遇到以下 1-4 情况,会导致显示不全
* 1. "!",会导致后面字符按注释解析
* 2. "/",导致按结束标签解析,若下一个字母是 ascii alpha 产生结束标签,若是 ">" 则空,其他情况会变成注释
* 3. "?",导致后面变成注释,不显示
* 4. ascii alpha 字母,进入 tag name 状态,接下来的字符都会变成标签名,导致无显示
* 5. 其他情况:正常产生 "<"
*
* 替换策略:当匹配到情况 1-4 时,给 "<" 与符号之间补一个空注释节点 <!---->
*
* 详情:https://html.spec.whatwg.org/multipage/parsing.html#tag-open-state
*
* @param {string} input 输入的带实体HTML字符串
*/
function replaceHTMLEntityTagStr(input = '') {
// entity 有三种:命名、十六进制、十进制
return input.replace(
/((<)|(<)|(<))(!|\/|\?|[a-zA-Z])/gi,
(all, p1, p2, p3, p4, p5) => `${p1}<!---->${p5}`
);
}
兼容性的考虑:
HTML Tag 解析属于浏览器最最基础的功能,理论上不会有兼容问题(在 Safari / Chromium 的爷爷 WebKit 的最初版本,可以找到与此一致的 Tokenizer 代码,与最新的代码相比并无明显改动)
问题页面用于移动端(iOS 统一系统 WebView;Android 有 QQ 浏览器 X5 内核),可以保持一个比较高版本的 WebKit / Chromium 浏览器内核
本替换逻辑在 IE 7 以上测试均可用,iOS 11 的 Safari / Chromium 44 / Firefox 91.01 测试正常(其他版本暂未验证)
hack 心得
与 bug 的互怼中感触良多,简单总结几点「人生的经验」:
1. 相比于手段而言,更需要关注的是目的本身,罗马只有一个,但通往罗马的道路可以有千万条。在通常的视角,DOM 决定了 UI 的展示,我们的关注点一般会放在 DOM 上,这也成为了一个思维定势。
一棵 DOM 树的来源可以分为这两块:
浏览器解析 HTML,在词法分析中构建起 DOM 树
在 JavaScript 层面,通过 createElement、appendChild 等 API 去构造;在 React / Vue 等 GUI 框架等层面,它将这些方法封装起来,通过构造 Object 树,然后统一 Render 出对应的 DOM 节点
而这一次的异常 hack 场景因为现实条件限制,关注点已不仅仅是 DOM 层面,所以我们的 “罗马” 也放在最终的 UI 上。相同的 UI 展示的背后,可能对应不同的 DOM 树,从数学的角度类似一个 n --> 1 的映射。当一条路难以走通时,我们可以不走寻常路,用另外的方式达成相同的目的。当然,不走寻常路,也意味着自己需要独自去面对一些少有人遇到的风险。
2. 虽然是写前端页面(俗称 “切图”),但计算机基础知识也总在不经意间用上,尝试抓住一些共性的东西,在适当的时候可以实现降维打击;当然这里也不需要太过于高深,一些基础的编译原理知识足矣,标准文档早已把所有要用到的术语概念、算法等都写在了上面,需要的仅仅是静下来阅读的心境。
3. 事物的发展总在一种渐进式的状态,达到理想并非一蹴而就之事,先稳住局面,才有时间优化。一开始可能难以做得完美,更多的是先完成再完美的状态。由此也想到,对于工程师这一角色的要求,除了代码质量外,更重要的大概是一种,在有限的时间内,面向业务对质量与效率的不同需求,得到最合适的解决方案的能力,类似 “快速达到 60 分” 与 “精细打磨到 90 + 分” 之间的一个灵活控制。

关于奇舞团
奇舞团是 360 集团最大的大前端团队,代表集团参与 W3C 和 ECMA 会员(TC39)工作。奇舞团非常重视人才培养,有工程师、讲师、翻译官、业务接口人、团队 Leader 等多种发展方向供员工选择,并辅以提供相应的技术力、专业力、通用力、领导力等培训课程。奇舞团以开放和求贤的心态欢迎各种优秀人才关注和加入奇舞团。
















 254
254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









