







牛客网专项练习----算法
1.在索引顺序表中,实现分块查找,在等概率查找情况下,其平均查找长度不仅与表中元素个数有关,而且与每块中元素个数有关()
答案:是
2.既希望较快的查找又便于线性表动态变化的查找方法是()
答案:索引顺序查找
选c,答案提示错误,不是索引?希望较快而不是很快,并且希望便于动态变化,这个用C而不是D,如果哈希法的存储不是链式,一般的情况下随着关键字的增多,冲突频繁发生,查找性能会急剧下降,其实并不是太利于动态变化,索引顺序由于一般块内可以无序,因此块内可以方便地减少增加
3.不知道是不是bug 第三题和第二题一样
4.采用折半查找方法进行查找,数据文件应为(),且限于()
答案:有序表 顺序存储结构
5.已知二叉树后序遍历序列是bfegcda,中序遍历序列是badefcg,它的前序遍历序列是:
答案:abdcefg
树的形状为ab dce gf
6.在有序表(12,24,36,48,60,72,84)中二分查找关键字72时所需进行的关键字比较次数是多少?
答案:2第一次二分查找取序列中间值48,比较72>48第二次查找取48右侧的子序列60,72,84的中值72,比较72==72,返回。查找完成7. 在序列 [22, 34, 55, 77, 89, 93, 99, 102, 120, 140] 中,采用二分查找,分别查找77,34,99,所需的查找次数分别为()答案:22 34 55 77 89 93 99 102 120 1400 1 2 3 4 5 6 7 8 9假设低下标用low表示,高下标用high表示。查找77:开始low = 0, high = 9第一次查找,找到中心的下标为(0+9)/2 = 4,即89,由于89大于77,所以,调整low = 0,high = 3( 注意:由于知道下标为4的元素比77大,所以不会让high等于4)第二次查找,找到中心的下标为(0+3)/2 = 1,即34,由于34小于77,所以,调整low = 2,high = 3第三次查找,找到中心的下标为(2+3)/2 = 2,即55,由于55小于77,所以,调整low = 3,high = 3第四次查找,找到中心的下标为(3+3)/2 = 3,即77,找到所要找的元素查找34和99的过程类似。。。8. KMP算法下,长为n的字符串中匹配长度为m的子串的复杂度为()答案: O(M+N)kmp算法完成的任务是:给定两个字符串O和f,长度分别为n和 m,判断f是否在O中出现,如果出现则返回出现的位置。常规方法是遍历O的每一个位置,然后从该位置开始和f进行匹配,但是这种方法的复杂度是 O(nm)。kmp算法通过一个O(m)的预处理,使匹配的复杂度降为O(n+m)。kmp算法思想
我们首先用一个图来描述kmp算法的思想。在字符串O中寻 找f,当匹配到位置i时两个字符串不相等,这时我们需要将字符串f向前移动。常规方法是每次向前移动一位,但是它没有考虑前i-1位已经比较过这个事实, 所以效率不高。事实上,如果我们提前计算某些信息,就有可能一次前移多位。假设我们根据已经获得的信息知道可以前移k位,我们分析移位前后的f有什么特点。我们可以得到如下的结论:
- A段字符串是f的一个前缀。
- B段字符串是f的一个后缀。
- A段字符串和B段字符串相等。
所以前移k位之后,可以继续比较位置i的前提是f的前i-1个位置满足:长度为i-k-1的前缀A和后缀B相同。只有这样,我们才可以前移k位后从新的位置继续比较。
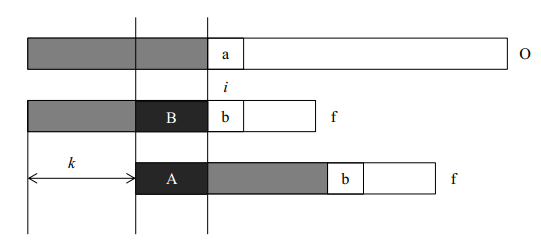
所以kmp算法的核心即是计算字符串f每一个位置之前的字 符串的前缀和后缀公共部分的最大长度(不包括字符串本身,否则最大长度始终是字符串本身)。获得f每一个位置的最大公共长度之后,就可以利用该最大公共长 度快速和字符串O比较。当每次比较到两个字符串的字符不同时,我们就可以根据最大公共长度将字符串f向前移动(已匹配长度-最大公共长度)位,接着继续比 较下一个位置。事实上,字符串f的前移只是概念上的前移,只要我们在比较的时候从最大公共长度之后比较f和O即可达到字符串f前移的目的。
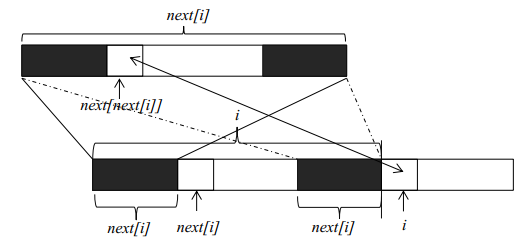
next数组计算
理解了kmp算法的基本原理,下一步就是要获得字符串f每一个位置的最大公共长度。这个最大公共长度在算法导论里面被记为next数组。 在这里要注意一点, next 数组表示的是长度,下标从 1 开始;但是在遍历原字符串时,下标还是从 0 开始。假设我们现在已经求得next[1]、next[2]、……next[i],分别表示长度为1到i的字符串的前缀和后缀最大公共长度,现在要求next[i+1]。由上图我们可以看到,如果位置i和位置next[i]处的两个字符相同( 下标从零开始), 则next[i+1]等于next[i]加1。如果两个位置的字符不相同,我们可以将长度为next[i]的字符串继续分割,获得其最大公共长度 next[next[i]],然后再和位置i的字符比较。这是因为长度为next[i]前缀和后缀都可以分割成上部的构造,如果位置 next[next[i]]和位置i的字符相同,则next[i+1]就等于next[next[i]]加1。如果不相等,就可以继续分割长度为 next[next[i]]的字符串,直到字符串长度为0为止。由此我们可以写出求next数组的代码( Java版):上述代码需要注意的问题是,我们求取的next数组表示长度为1 到m的字符串f前缀的最大公共长度,所以需要多分配一个空间。而在遍历字符串f的时候,还是从下标0开始(位置0和1的next值为0,所以放在循环外 面),到m-1为止。代码的结构和上面的讲解一致,都是利用前面的next值去求下一个next值。
publicint[] getNext(String b){intlen=b.length();intj=0;intnext[]=newint[len+1];//next表示长度为i的字符串前缀和后缀的最长公共部分,从1开始next[0]=next[1]=0;for(inti=1;i<len;i++)//i表示字符串的下标,从0开始{//j在每次循环开始都表示next[i]的值,同时也表示需要比较的下一个位置while(j>0&&b.charAt(i)!=b.charAt(j))j=next[j];if(b.charAt(i)==b.charAt(j))j++;next[i+1]=j;}returnnext;}字符串匹配
计算完成next数组之后,我们就可以利用next数组在 字符串O中寻找字符串f的出现位置。匹配的代码和求next数组的代码非常相似,因为匹配的过程和求next数组的过程其实是一样的。假设现在字符串f的 前i个位置都和从某个位置开始的字符串O匹配,现在比较第i+1个位置。如果第i+1个位置相同,接着比较第i+2个位置;如果第i+1个位置不同,则出 现不匹配,我们依旧要将长度为i的字符串分割,获得其最大公共长度next[i],然后从next[i]继续比较两个字符串。这个过程和求next数组一 致,所以可以匹配代码如下(java版):上述代码需要注意的一点是,每次我们得到一个匹配之后都要对j重新赋值。
publicvoidsearch(String original, String find,intnext[]) {intj =0;for(inti =0; i < original.length(); i++) {while(j >0&& original.charAt(i) != find.charAt(j))j = next[j];if(original.charAt(i) == find.charAt(j))j++;if(j == find.length()) {System.out.println("find at position "+ (i - j));System.out.println(original.subSequence(i - j +1, i +1));j = next[j];}}}9. 下面哪一方法可以判断出一个有向图是否有环(回路)()答案:深度优先遍历拓扑排序判断是否有环方法:1.拓扑排序2.深度优先遍历3.广度优先遍历
10.要进行顺序查找,则线性表 1 ;要进行折半查询,则线性表 2 ;
A. 必须以顺序方式存储; B. 必须以链式方式存储;C. 既可以以顺序方式存储,也可以链式方式存储; D. 必须以顺序方式存储,且数据已按递增或递减顺序排好; E. 必须以链式方式存储,且数据已按递增或递减的次序排好。
若表中元素个数为 n, 则顺序查找的平均比较次数为 3 ;折半查找的平均比较次数为 4 。A.n B.n/2 C.n*n D.n*n/2 E.log 2 n F.nlog 2 n G.(n+1)/2 H.log 2(n+1)答案: CDGH















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









