







Redis集群详解
- ————————————————
版权声明:本文为CSDN博主「怪 咖@」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_43888891/article/details/131208398
目录
一、前言
二、Redis 集群方案应该怎么做?都有哪些方案?
三、twemproxy
四、分而治之-codis
1、codis简介
2、Codis 分片原理
3、不同的 Codis 实例之间槽位关系如何同步?
4、假如Redis扩容,如何调整槽位的?
5、codis优缺点
6、MGET 指令的操作过程
五、众志成城-cluster
1、cluster简介
2、槽位定位算法
3、Redis 集群一致性保证
4、集群参数配置
5、搭建cluster集群
5.1.安装Redis
5.2.创建3主3从配置文件
5.3.将6个节点合成一个集群
5.4.redis集群如何分配这6个节点?
5.5.什么是slots(槽)
5.6.slot相关的一些命令
5.7.AnotherRedisDesktopManager 客户端
5.8.故障恢复
6、Redis cluster 优缺点
六、Jedis连接cluster模式
七、SpringBoot整合cluster模式
注:本篇部分知识点来源于【Redis深度历险-核心原理和应用实践】书籍当中!
一、前言
在了解Redis集群之前尽量先了解清楚Redis的主从复制和哨兵机制。
https://blog.csdn.net/weixin_43888891/article/details/131039418
Redis的主从复制主要有两个作用:
- 读写分离,性能扩展,降低主服务器的压力
- 容灾,快速恢复,主机挂掉时,从机变为主机
哨兵机制:
哨兵机制:
- Redis 主从模式不具备自动容错和恢复功能,如果主节点宕机,Redis 集群将无法工作,此时需要人为干预,将从节点提升为主节点。
- 哨兵机制作用主要是监控主从节点,当主节点挂掉,通过内部投票机制,从 从节点当中选出一个主节点,这样可以避免人工成本。
虽然主从+哨兵采用了多节点,但是他们存在的目的主要是解决容灾问题,而并非性能问题。
那目前Redis性能存在什么问题?
- Redis 内存太大会导致 rdb文件过大,进一步导致主从同步时全量同步时间过长,在实例重启恢复时也会消耗很长的数据加载时间,特别是在云环境下,单个实例内存往往都是受限的。
单个 Redis 实例只能利用单个核心,这单个核心要完成海量数据的存取和管理工作压力会非常大。
单台redis内存容量限制,如何进行扩容?继续加内存、加硬件么?
互联网分布式架构设计,提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。
-
垂直扩展:提升单机处理能力。增强单机硬件性能,例如:增加CPU核数如32核,升级更好的网卡如万兆,升级更好的硬盘如SSD,扩充硬盘容量如2T,扩充系统内存如128G;
-
水平扩展:只要增加服务器数量,就能线性扩充系统性能。水平扩展对系统架构设计是有要求的,如何在架构各层进行可水平扩展的设计,以及互联网公司架构各层常见的水平扩展实践,是本文重点讨论的内容。
在互联网业务发展非常迅猛的早期,如果预算不是问题,强烈建议使用“增强单机硬件性能”的方式提升系统并发能力,因为这个阶段,公司的战略往往是发展业务抢时间,而“增强单机硬件性能”往往是最快的方法。
单机性能总是有极限的。所以互联网分布式架构设计高并发终极解决方案还是水平扩展。
Redis性能问题如何解决?
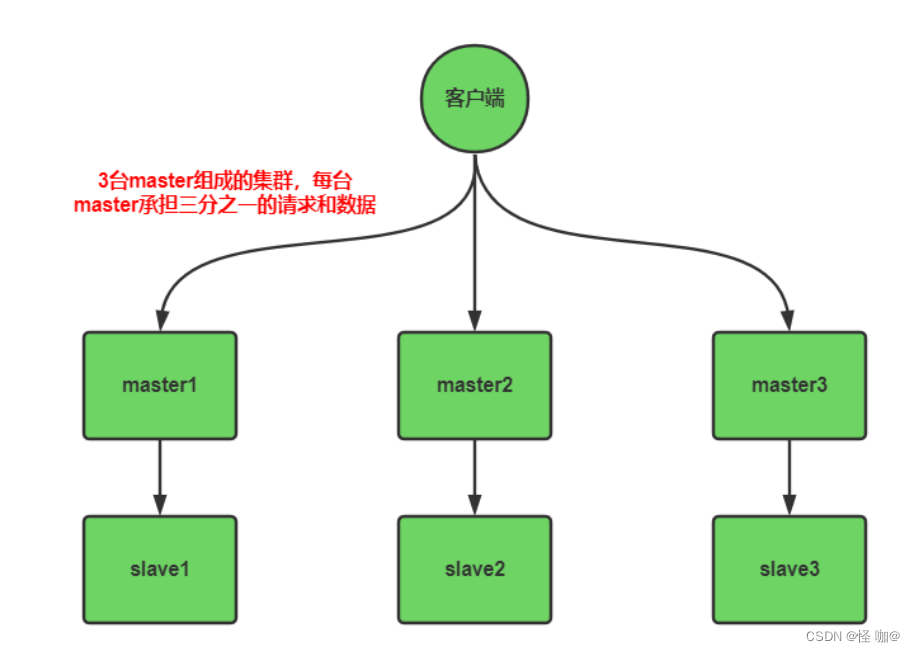
正是在这样的大数据高并发的需求之下,Redis 集群方案应运而生。redis集群是对redis的水平扩容,即启动N个redis节点,将整个数据分布存储在这个N个节点中,每个节点存储总数据的1/N。
如下图:由3台master和3台slave组成的redis集群,每台master承接客户端三分之一请求和写入的数据,当master挂掉后,slave会自动替代master,做到高可用。
二、Redis 集群方案应该怎么做?都有哪些方案?
提到集群必然离不开数据分片,数据分片指按照 某个维度将存放在单一数据库中的数据 分散地 存放至 多个数据库或表中以达到提升性能瓶颈以及可用性的效果。那么我们如何实现数据分片?
注意:数据分片不仅仅涉及到数据的存储,还涉及到数据的提取,假设有三台redis节点集群,分别是a、b、c,然后我set test value 将test的key value存储到了三个节点其中一个节点,当我get的时候我还要保证他能找到当时存储的节点,只有找到节点才能拿到当时存储的数据。
关于分片有下面三种方案:
-
客户端分片:客户端通过固定的Hash算法,针对不同的key计算对应的Hash值,然后对不同的Redis节点进行读写。说白了就是自己实现分片算法。这样对于程序代码侵入性太强,一般也很少有人会这么搞。
-
代理分片:理解为业务只连一个代理应用,代理应用后面会控制连接哪些实例。对于代理现在已经有两个现成可使用的,分别是Twemproxy、Codis。
-
Redis Cluster:Redis3.*自带的应用。Redis Cluster将所有Key映射到16384个Slot中,集群中每个Redis实例负责一部分,业务程序通过集成的Redis Cluster客户端进行操作。客户端可以向任一实例发出请求,如果所需数据不在该实例中,则该实例引导客户端自动去对应实例读写数据。

在早期搭建集群很多都是采用代理分片,因为当时redis cluster发布得比较晚(2015年才发布正式版 ),各大厂等不及了,陆陆续续开发了自己的redis数据分片集群模式,比如:Twemproxy、Codis等。都属于当时的产物,现在codis已经彻底不更新了,而Twemproxy更新速度非常缓慢。所以基本上现在搭建集群都是使用官方的Redis Cluster!
三、twemproxy
twemproxy源码:https://github.com/twitter/twemproxy
Twemproxy是一种代理分片机制,由Twitter开源。Twemproxy作为代理,可接受来自多个程序的访问,按照路由规则,转发给后台的各个Redis或memcached服务器,再原路返回。
Twemproxy 搭建 redis 集群有以下的优势:
快速 — 据测试,直连 twenproxy 和直连 redis 相比几乎没有性能损失,读写分离后更是能够极大地提高集群响应能力
轻量级 — Twemproxy 通过透明连接池、内存零拷贝以及 epoll 模型实现了足够的快速和轻量化,源码较为简洁精炼
降低负载 — 透明连接池保持前端的连接数,减少后端的连接数,让后端的 redis 节点负载大为降低
分片 — Twemproxy 通过一致性 hash 算法将数据进行分片,从而实现 redis 集群的高速缓存,降低负载
多协议 — 同时支持 redis 与 memcache 集群的搭建
多算法 — 支持多种算法实现一致性哈希分片,包括crc32,crc16,MD5等
配置简单
监控报警丰富 — 虽然他提供的原生监控功能一般较少使用,但其提供的统计信息,如发送了多少读写命令还是有很大的价值的
但它的痛点就是无法在线扩容、缩容,这就导致运维非常不方便,而且也没有友好的运维UI可以使用。Codis就是因为在这种背景下才衍生出来的。
四、分而治之-codis
1、codis简介
cocdis源码:https://github.com/CodisLabs/codis
中文使用教程:https://github.com/CodisLabs/codis/blob/master/doc/tutorial_zh.md
cocdis已经近五年没有过更新迭代了,但是在早期是相当的火的,就好比当时的Hibernate!
Codis 是 Redis 集群方案之一,令我们感到骄傲的是,它是中国人开发并开源的,来自前豌豆荚中间件团队。绝大多数国内的开源项目都不怎么靠谱,但是 Codis 非常靠谱。有了Codis 技术积累之后,项目「突头人」刘奇又开发出来中国人自己的开源分布式数据库 ——TiDB,可以说 6 到飞起。
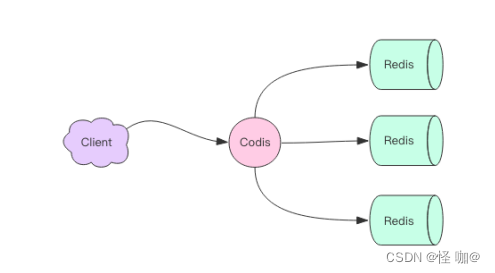
Codis 使用 Go 语言开发,它是一个代理中间件,它和 Redis 一样也使用 Redis 协议对外提供服务,当客户端向 Codis 发送指令时,Codis 负责将指令转发到后面的 Redis 实例来执行,并将返回结果再转回给客户端。客户端操纵 Codis 同操纵 Redis 几乎没有区别,还是可以使用相同的客户端 SDK,不需要任何变化。
Codis 上挂接的所有 Redis 实例构成一个 Redis 集群,当集群空间不足时,可以通过动态增加 Redis 实例来实现扩容需求。
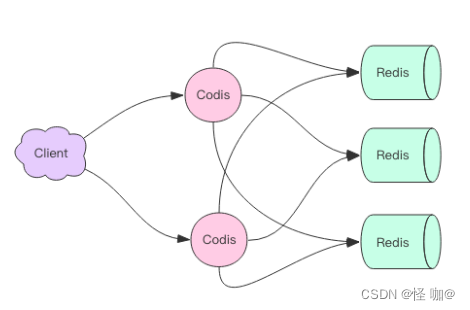
因为 Codis 是无状态的,它只是一个转发代理中间件,这意味着我们可以启动多个Codis 实例,供客户端使用,每个 Codis 节点都是对等的。因为单个 Codis 代理能支撑的QPS 比较有限,通过启动多个 Codis 代理可以显著增加整体的 QPS 需求,还能起到容灾功能,挂掉一个 Codis 代理没关系,还有很多 Codis 代理可以继续服务。
无状态:无状态指的是对于请求方的每个请求,接收方都当这次请求是第一次请求。为什么叫做无状态呢?因为对于请求方而言,每次请求时,接收方就像是失忆了一样,并不会依赖请求方以往的请求所生成的数据作回应。也就是说,就像是接收方没有保存请求方的状态(数据)一样,所以叫无状态。常用的HTTP就是无状态协议!
2、Codis 分片原理
Codis 要负责将特定的 key 转发到特定的 Redis 实例,那么这种对应关系 Codis 是如何管理的呢?
Codis 将所有的 key 默认划分为 1024 个槽位(slot),它首先对客户端传过来的 key 进行 crc32 运算计算哈希值,再将 hash 后的整数值对 1024 这个整数进行取模得到一个余数,这个余数就是对应 key 的槽位。
- crc32
- hash值
- 对 1023 取模,得到余数,就是 槽位
- 假如是 666,一个3个节点。就是 存到 第二个节点了
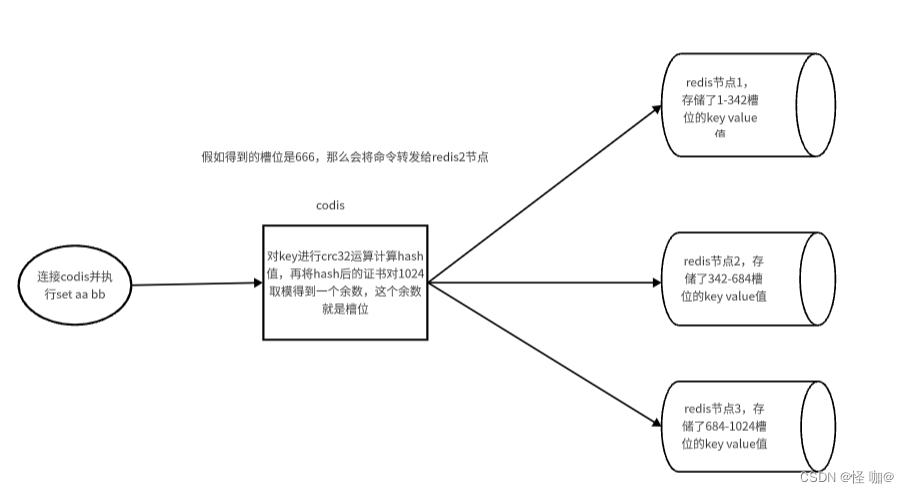
每个槽位都会唯一映射到后面的多个 Redis 实例之一,Codis 会在内存维护槽位和Redis 实例的映射关系。这样有了上面 key 对应的槽位,那么它应该转发到哪个 Redis 实例就很明确了。
槽位数量默认是 1024,它是可以配置的,如果集群节点比较多,建议将这个数值配置大一些,比如 2048、4096。
3、不同的 Codis 实例之间槽位关系如何同步?
如果 Codis 的槽位映射关系只存储在内存里,那么不同的 Codis 实例之间的槽位关系就无法得到同步。所以 Codis 还需要一个分布式配置存储数据库专门用来持久化槽位关系。Codis 开始使用 ZooKeeper,后来连 etcd 也一块支持了。
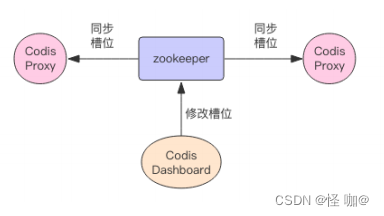
Codis 将槽位关系存储在 zk 中,并且提供了一个 Dashboard 可以用来观察和修改槽位关系,当槽位关系变化时,Codis Proxy 会监听到变化并重新同步槽位关系,从而实现多个Codis Proxy 之间共享相同的槽位关系配置。
4、假如Redis扩容,如何调整槽位的?
刚开始 Codis 后端只有一个 Redis 实例,1024 个槽位全部指向同一个 Redis。然后一个 Redis 实例内存不够了,所以又加了一个 Redis 实例。这时候需要对槽位关系进行调整,将一半的槽位划分到新的节点。这意味着需要对这一半的槽位对应的所有 key 进行迁移,迁移到新的 Redis 实例。
那 Codis 如果找到槽位对应的所有 key 呢?
Codis 对 Redis 进行了改造,增加了 SLOTSSCAN 指令,可以遍历指定 slot(槽位) 下所有的key。Codis 通过 SLOTSSCAN 扫描出待迁移槽位的所有的 key,然后挨个迁移每个 key 到新的 Redis 节点。
在迁移过程中,Codis 还是会接收到新的请求打在当前正在迁移的槽位上,因为当前槽位的数据同时存在于新旧两个槽位中,Codis 如何判断该将请求转发到后面的哪个具体实例呢?
Codis 无法判定迁移过程中的 key 究竟在哪个实例中,所以它采用了另一种完全不同的思路。当 Codis 接收到位于正在迁移槽位中的 key 后,会立即强制对当前的单个 key 进行迁移,迁移完成后,再将请求转发到新的 Redis 实例。
我们知道 Redis 支持的所有 Scan 指令都是无法避免重复的,同样 Codis 自定义的SLOTSSCAN 也是一样,但是这并不会影响迁移。因为单个 key 被迁移一次后,在旧实例中它就彻底被删除了,也就不可能会再次被扫描出来了。
自动均衡
Redis 新增实例,手工均衡 slots 太繁琐,所以 Codis 提供了自动均衡功能。自动均衡会在系统比较空闲的时候观察每个 Redis 实例对应的 Slots 数量,如果不平衡,就会自动进行迁移。
5、codis优缺点
缺点:
不支持事务: Codis 中所有的 key 分散在不同的 Redis 实例中,所以事务就不能再支持了,事务只能在单个 Redis 实例中完成。
很多redis命令也不再支持: rename 操作也很危险,它的参数是两个 key,如果这两个 key 在不同的 Redis 实例中,rename 操作是无法正确完成的。Codis 的官方文档中给出了一系列不支持的命令列表。
单个 key 对应的 value 不宜过大: 因为集群的迁移的最小单位是key,对于一个 hash 结构,它会一次性使用 hgetall 拉取所有的内容,然后使用 hmset 放置到另一个节点。如果 hash 内部的 kv 太多,可能会带来迁移卡顿。官方建议单个集合结构的总字节容量不要超过 1M。如果我们要放置社交关系数据,例如粉丝列表这种,就需要注意了,可以考虑分桶存储,在业务上作折中。
增加了网络开销: Codis 因为增加了 Proxy 作为中转层,所有在网络开销上要比单个 Redis 大,毕竟数据包多走了一个网络节点,整体在性能上要比单个 Redis 的性能有所下降。但是这部分性能损耗不是太明显,可以通过增加 Proxy 的数量来弥补性能上的不足。
增加了运维成本: Codis 的集群配置中心使用 zk 来实现,意味着在部署上增加了 zk 运维的代价。
优点:
- 设计上简单: Codis 在设计上相比 Redis Cluster 官方集群方案要简单很多,因为它将分布式的问题交给了第三方 zk/etcd去负责,自己就省去了复杂的分布式一致性代码的编写维护工作。而Redis Cluster的内部实现非常复杂,它为了实现去中心化,混合使用了复杂的 Raft 和Gossip协议,还有大量的需要调优的配置参数,当集群出现故障时,维护人员往往不知道从何处着手。
- 有图形化界面: Codis 有个特色的地方在于强大的 Dashboard 功能,能够便捷地对 Redis 集群进行管理。这是 Redis 官方所欠缺的。另外 Codis 还开发了一个 Codis-fe(federation 联邦) 工具,可以同时对多个 Codis 集群进行管理。在大型企业,Codis 集群往往会有几十个,有这样一个便捷的联邦工具可以降低不少运维成本。
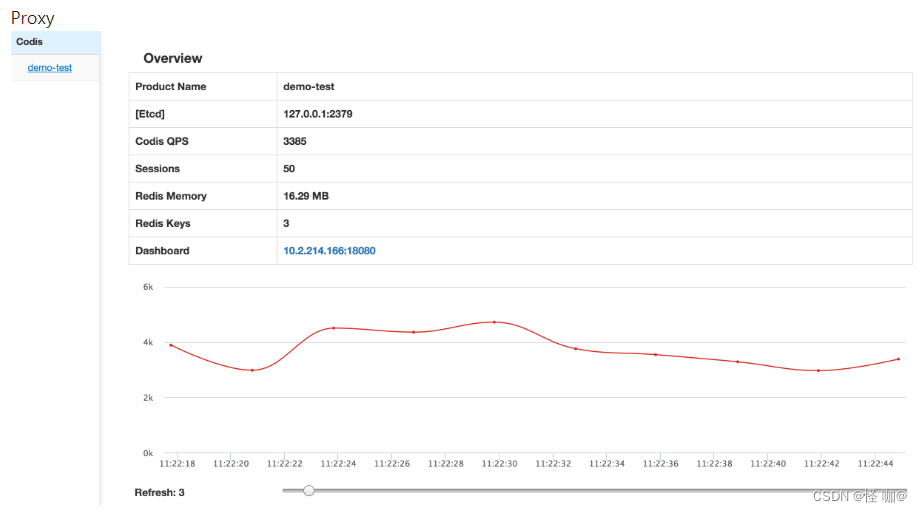
后台管理的界面非常友好,使用了最新的 BootStrap 前端框架。比较酷炫的是可以看到实时的 QPS 波动曲线。
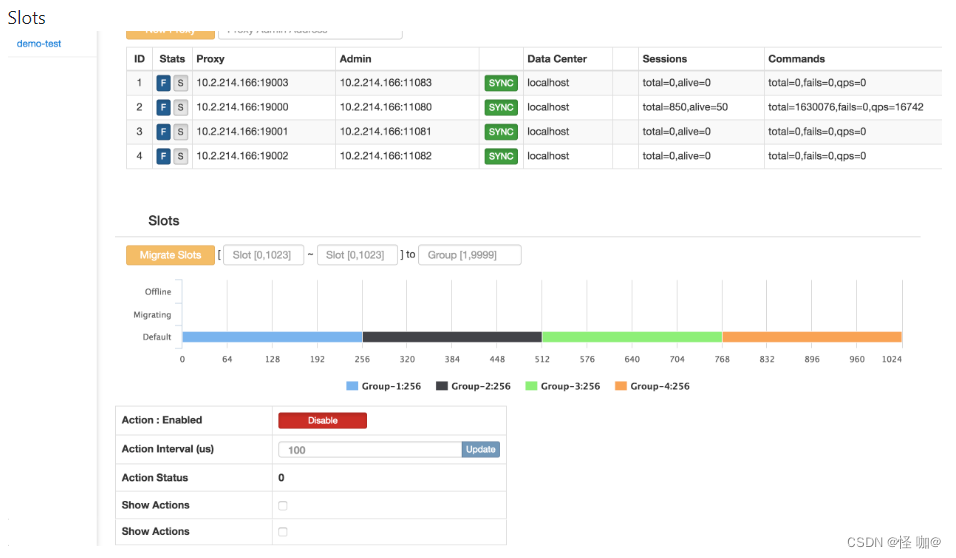
同时还支持服务器集群管理功能,可以增加分组、增加节点、执行自动均衡等指令,还可以直接查看所有 slot 的状态,每个 slot 被分配到哪个 Redis 实例。
6、MGET 指令的操作过程
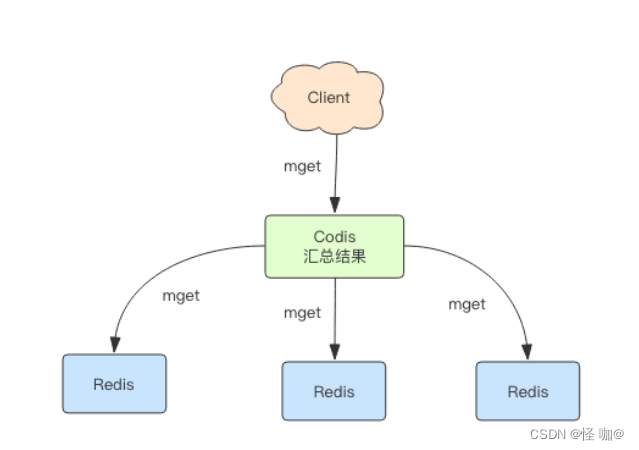
mget 指令用于批量获取多个 key 的值,这些 key 可能会分布在多个 Redis 实例中。Codis 的策略是将 key 按照所分配的实例打散分组,然后依次对每个实例调用 mget 方法,最后将结果汇总为一个,再返回给客户端。
五、众志成城-cluster
cluster
英
/ˈklʌstə(r)/
n.
组,簇;星团;一连串同类事件;(聚集在同一地方的)一群人;(计算机磁盘上的)丛集,群集;辅音群,辅音连缀;基
v.
群聚,聚集;(数据点)具近似数值
1、cluster简介
官网教程:https://redis.com.cn/topics/cluster-tutorial.html
RedisCluster 是 Redis 的亲儿子,它是 Redis 作者自己提供的 Redis 集群化方案。
相对于 Codis 的不同,它是去中心化的,如图所示,该集群有三个 Redis 节点组成,每个节点负责整个集群的一部分数据,每个节点负责的数据多少可能不一样。这三个节点相互连接组成一个对等的集群,它们之间通过一种特殊的二进制协议相互交互集群信息。
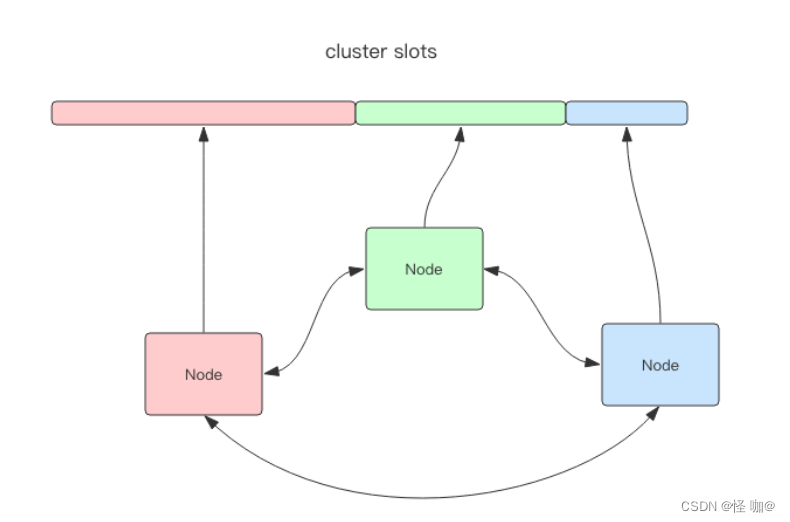
Redis Cluster 将所有数据划分为 16384 的 slots,它比 Codis 的 1024 个槽划分的更为精细,每个节点负责其中一部分槽位。槽位的信息存储于每个节点中,它不像 Codis,它不需要另外的分布式存储来存储节点槽位信息。
当 Redis Cluster 的客户端来连接集群时,
- 它也会得到一份集群的槽位配置信息。这样当客户端要查找某个 key 时,可以直接定位到目标节点。这点不同于 Codis,Codis 需要通过 Proxy 来定位目标节点,
- RedisCluster 是直接定位。
- 客户端为了可以直接定位某个具体的 key 所在的节点,它就需要缓存槽位相关信息,这样才可以准确快速地定位到相应的节点。同时因为槽位的信息可能会存在客户端与服务器不一致的情况,还需要纠正机制来实现槽位信息的校验调整。
另外,RedisCluster 的每个节点会将集群的配置信息持久化到配置文件中,所以必须确保配置文件是可写的,而且尽量不要依靠人工修改配置文件。
调整槽位
Redis Cluster 提供了工具 redis-trib 可以让运维人员手动调整槽位的分配情况,它使用Ruby 语言进行开发,通过组合各种原生的 Redis Cluster 指令来实现。
这点 Codis 做的更加人性化,它不但提供了 UI 界面可以让我们方便的迁移,还提供了自动化平衡槽位工具,无需人工干预就可以均衡集群负载。不过 Redis 官方向来的策略就是提供最小可用的工具,其它都交由社区完成。
端口
每个Redis集群节点需要打开两个TCP连接。端口6379提供给客户端连接,外加上一个端口16379,记起来也比较容易,在6379的基础上加10000。
端口16379提供给集群总线使用,总线用来集群节点间通信,使用的是二进制协议。
- 集群总线的作用:失败检测、配置升级、故障转移授权等。
- 客户端只能连接6379端口,不能连接端口16379。防火墙需要确保打开这两个端口,否则集群节点之间不能通信。
2、槽位定位算法
Cluster 默认会对 key 值使用 crc32 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模来得到具体槽位。
- crc32
- hash
- 16384 取模,得到槽位
Cluster 还允许用户强制某个 key 挂在特定槽位上,通过在 key 字符串里面嵌入 tag 标记,这就可以强制 key 所挂在的槽位等于 tag 所在的槽位。
当客户端向一个错误的节点发出了指令,该节点会发现指令的 key 所在的槽位并不归自己管理,这时它会向客户端发送一个特殊的跳转指令携带目标操作的节点地址,告诉客户端去连这个节点去获取数据。关于这一点在后面会重点进行演示!
3、Redis 集群一致性保证
Redis集群不能保证强一致性。一些已经向客户端确认写成功的操作,会在某些不确定的情况下丢失。
产生写操作丢失的第一个原因,是因为主从节点之间使用了异步的方式来同步数据。
一个写操作是这样一个流程:
- 客户端向主节点B发起写的操作
- 主节点B回应客户端写操作成功
- 主节点B向它的从节点B1,B2,B3同步该写操作
从上面的流程可以看出来,主节点**B并没有等从节点B1,B2,B3写完之后再回复客户端这次操作的结果。**所以,如果主节点B在通知客户端写操作成功之后,但同步给从节点之前,主节点B故障了,其中一个没有收到该写操作的从节点会晋升成主节点,该写操作就这样永远丢失了。
如果真的需要,Redis集群支持同步复制的方式,通过WAIT 指令来实现,这可以让丢失写操作的可能性降到很低。但就算使用了同步复制的方式,Redis集群依然不是强一致性的,在某些复杂的情况下,比如从节点在与主节点失去连接之后被选为主节点,不一致性还是会发生。
4、集群参数配置

5、搭建cluster集群
5.1.安装Redis
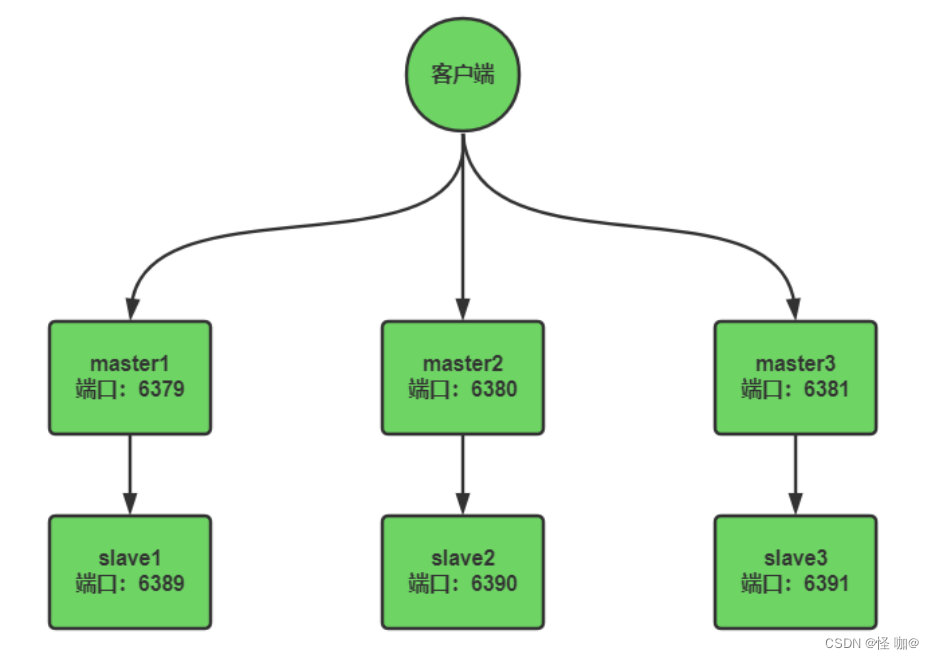
下面我们来配置一个3主3从的集群,每个主下面挂一个slave,master挂掉后,slave会被提升为master。
为了方便,我们在一台Linux机器上进行模拟,通过端口来区分6个不同的节点,配置信息如下
(1)停止redis
假如linux当中安装的有redis,可以先全部停掉,停止所有的redis命令:
ps -ef | grep redis | awk -F" " '{print $2;}' | xargs kill -9
(2)下载redis,然后将redis上传到opt目录
如果没有安装wget请先安装:
cd /opt
yum -y install wget
wget https://download.redis.io/redis-stable.tar.gz
(3)安装redis
要编译 Redis,首先是 tar解压,切换到根目录,然后运行make:
tar -xzvf redis-stable.tar.gz
cd redis-stable
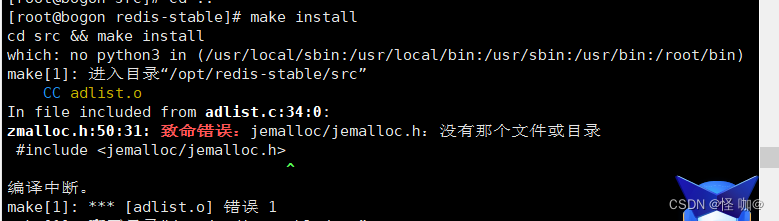
make install
假如make install报如下异常,直接使用make install MALLOC=libc
安装过后你会在src目录中找到几个 Redis 二进制文件,包括:
- redis-server:Redis 服务器本身
- redis-cli:是与 Redis 对话的命令行界面实用程序,俗称客户端。
基本规划和配置
5.2.创建3主3从配置文件
执行下面命令创建 /opt/cluster 目录,本次所有操作,均在 cluster 目录进行。
(1)创建cluster目录并且将redis.conf复制到cluster目录
log目录专门来存储节点产生的日志
mkdir /opt/redis-stable/cluster
mkdir /opt/redis-stable/cluster/log
cd /opt/redis-stable/cluster
cp /opt/redis-stable/redis.conf /opt/redis-stable/cluster/
现在我们需要创建6个配置文件,6个配置文件只有如下几行是不一样的:
port 6379
# 持久化文件
dbfilename dump_6379.rdb
pidfile /var/run/redis_6379.pid
logfile "/opt/redis-stable/cluster/log/6379.log"
# 设置节点配置文件
cluster-config-file node-6379.conf
(2)创建master1的配置文件:redis-6379.conf
touch redis-6379.conf
vi redis-6379.conf
编辑为如下内容:
bind 0.0.0.0:表示允许所有ip地址访问,默认是127.0.0.1,只允许当前主机连接,假如这里要是配置成当前机器的ip或者是127.0.0.1,那么可能会导致在windows当中无法连接Redis。
master
在/opt/redis-stable/cluster/目录创建 redis-6379.conf 文件,内容如下
include /opt/redis-stable/cluster/redis.conf
# 当我们采用yes时,redis会在后台运行,此时redis将一直运行,除非手动kill该进程。
daemonize yes
bind 0.0.0.0
dir /opt/redis-stable/cluster/
port 6379
dbfilename dump_6379.rdb
pidfile /var/run/redis_6379.pid
logfile "/opt/redis-stable/cluster/log/6379.log"
# 开启集群设置
cluster-enabled yes
# 设置节点配置文件
cluster-config-file node-6379.conf
# 设置节点失联时间,超过该时间(毫秒),集群自动进行主从切换
cluster-node-timeout 15000
(3)创建master2的配置文件:redis-6380.conf
include /opt/redis-stable/cluster/redis.conf
daemonize yes
bind 0.0.0.0
dir /opt/redis-stable/cluster/
port 6380
dbfilename dump_6380.rdb
pidfile /var/run/redis_6380.pid
logfile "/opt/redis-stable/cluster/log/6380.log"
# 开启集群设置
cluster-enabled yes
# 设置节点配置文件
cluster-config-file node-6380.conf
# 设置节点失联时间,超过该时间(毫秒),集群自动进行主从切换
cluster-node-timeout 15000
(4)创建master3的配置文件:redis-6381.conf
include /opt/redis-stable/cluster/redis.conf
daemonize yes
bind 0.0.0.0
dir /opt/redis-stable/cluster/
port 6381
dbfilename dump_6381.rdb
pidfile /var/run/redis_6381.pid
logfile "/opt/redis-stable/cluster/log/6381.log"
# 开启集群设置
cluster-enabled yes
# 设置节点配置文件
cluster-config-file node-6381.conf
# 设置节点失联时间,超过该时间(毫秒),集群自动进行主从切换
cluster-node-timeout 15000
slave
(5)创建slave1的配置文件:redis-6389.conf
include /opt/redis-stable/cluster/redis.conf
daemonize yes
bind 0.0.0.0
dir /opt/redis-stable/cluster/
port 6389
dbfilename dump_6389.rdb
pidfile /var/run/redis_6389.pid
logfile "/opt/redis-stable/cluster/log/6389.log"
# 开启集群设置
cluster-enabled yes
# 设置节点配置文件
cluster-config-file node-6389.conf
# 设置节点失联时间,超过该时间(毫秒),集群自动进行主从切换
cluster-node-timeout 15000
(6)创建slave2的配置文件:redis-6390.conf
include /opt/redis-stable/cluster/redis.conf
daemonize yes
bind 0.0.0.0
dir /opt/redis-stable/cluster/
port 6390
dbfilename dump_6390.rdb
pidfile /var/run/redis_6390.pid
logfile "/opt/redis-stable/cluster/log/6390.log"
# 开启集群设置
cluster-enabled yes
# 设置节点配置文件
cluster-config-file node-6390.conf
# 设置节点失联时间,超过该时间(毫秒),集群自动进行主从切换
cluster-node-timeout 15000
(7)创建slave3的配置文件:redis-6391.conf
include /opt/redis-stable/cluster/redis.conf
daemonize yes
bind 0.0.0.0
dir /opt/redis-stable/cluster/
port 6391
dbfilename dump_6391.rdb
pidfile /var/run/redis_6391.pid
logfile "/opt/redis-stable/cluster/log/6391.log"
# 开启集群设置
cluster-enabled yes
# 设置节点配置文件
cluster-config-file node-6391.conf
# 设置节点失联时间,超过该时间(毫秒),集群自动进行主从切换
cluster-node-timeout 15000
启动
(8)启动master、slave1、slave2**
# 方便演示,停止所有的redis
ps -ef | grep redis | awk -F" " '{print $2;}' | xargs kill -9
/opt/redis-stable/src/redis-server /opt/redis-stable/cluster/redis-6379.conf
/opt/redis-stable/src/redis-server /opt/redis-stable/cluster/redis-6380.conf
/opt/redis-stable/src/redis-server /opt/redis-stable/cluster/redis-6381.conf
/opt/redis-stable/src/redis-server /opt/redis-stable/cluster/redis-6389.conf
/opt/redis-stable/src/redis-server /opt/redis-stable/cluster/redis-6390.conf
/opt/redis-stable/src/redis-server /opt/redis-stable/cluster/redis-6391.conf
(9)查看6个redis的启动情况
ps -ef | grep redis

稍后我们会将6个实例合并到一个集群,在组合之前,我们要确保6个redis实例启动后,nodes-xxxx.conf文件都生成正常,如下, /opt/redis-stable/config 目录中确实都生成成功了
- /opt/redis-stable/cluster 应该是这个目录
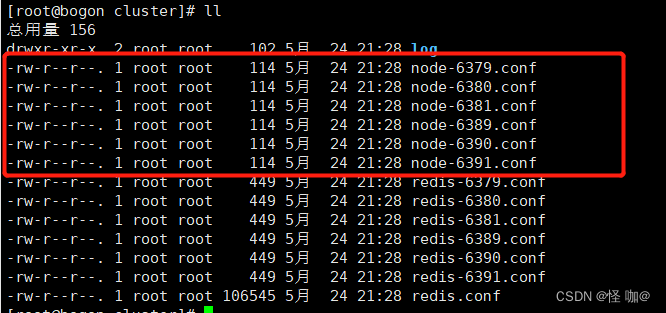
这时候node*.conf文件只存储了一个节点id。

(10)关闭防火墙
假如不关闭防火墙,可能会出现windows无法连接我们刚刚在虚拟机安装的redis的情况
设置开机启用防火墙:systemctl enable firewalld.service
设置开机禁用防火墙:systemctl disable firewalld.service
启动防火墙:systemctl start firewalld
关闭防火墙:systemctl stop firewalld
检查防火墙状态:systemctl status firewalld
5.3.将6个节点合成一个集群
(1)将6个redis合体
执行下面命令,将6个redis合体
/opt/redis-stable/src/redis-cli --cluster create --cluster-replicas 1 192.168.0.101:6379 192.168.0.101:6380 192.168.0.101:6381 192.168.0.101:6389 192.168.0.101:6390 192.168.0.101:6391
/opt/redis-stable/src/redis-cli --cluster create --cluster-replicas 1 192.168.70.127:6379 192.168.70.127:6380 192.168.70.127:6381 192.168.70.127:6389 192.168.70.127:6390 192.168.70.127:6391 -a 123456
合体的命令后面会跟上所有节点的ip:port列表,多个之间用空格隔开,注意ip不要写127.0.0.1,要写真实ip
–cluster-replicas 1:表示采用最简单的方式配置集群,即每个master配1个slave,6个节点就形成了3主3从
遇到如下报错,redis认为远程连接不安全,所以阻止你对redis进行操作

解决连接不安全的2种方式
解决方法:
方式一:在redis.conf配置文件有一个protected-mode默认为yes,设置为no
方式二:在redis.conf配置文件通过requirepass设置密码
- 更改配置文件,关闭所有集群,然后重新启动
- 合并集群指令 加上 -a 123456
这里我选择了方式二,设置密码。通过在命令当中-a来指定密码,执行过程如下,期间会让我们确定是否同样这样的分配方式,输入:yes,然后等几秒,集群合体成功
root@127:/opt/redis-stable/cluster# /opt/redis-stable/src/redis-cli --cluster create --cluster-replicas 1 192.168.70.127:6379 192.168.70.127:6380 192.168.70.127:6381 192.168.70.127:6389 192.168.70.127:6390 192.168.70.127:6391 -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.70.127:6390 to 192.168.70.127:6379
Adding replica 192.168.70.127:6391 to 192.168.70.127:6380
Adding replica 192.168.70.127:6389 to 192.168.70.127:6381
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: f25857941a701d1766716110b92609f79b5ccd9f 192.168.70.127:6379
slots:[0-5460] (5461 slots) master
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
yWaiting for the cluster to join
>>> Performing Cluster Check (using node 192.168.70.127:6379)
M: f25857941a701d1766716110b92609f79b5ccd9f 192.168.70.127:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: a3620ea50164296270d9e23217813580323a7ab8 192.168.70.127:6390
slots: (0 slots) slave
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
(2)查看集群节点信息
[root@bogon cluster]# /opt/redis-stable/src/redis-cli -c -h 127.0.0.1 -p 6379 -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> cluster nodes
如下图,对 cluster nodes 的结果做下解释,先看下红字的注释,集群中的每个节点都会生成一个ID,这个ID信息会被写到node-xxxx.conf文件中,为什么要生成id呢?
因为节点的ip和端口可能会发生变化,但是节点的ID是不会变的,其他节点可以通过其他节点的ID来认识各个节点。

- 从节点的主节点ID
- 6389 的主节点是 6379
- 槽位:0-5460,5461-10922,10923-16383
- 16383 / 3= 5461
- 所以:0-5460
这里是cluster nodes命令查出来的其实和生成的node-xxx.conf文件的配置是一样的!
(3)验证集群数据的读写操作
如下,我们连接 6379 这个节点,然后执行一个set操作,效果如下,写入成功

set name ready
-> Redirected to slot [5798] located at 192.168.70.127:6380
OK
大家可能注意到了,我们明明在 6379 上操作的,但是请求被转发到了6380这个节点去处理了,这里就是我们后面要说的slot的知识了,先向后看。
5.4.redis集群如何分配这6个节点?
一个集群至少有3个主节点,因为新master的选举需要大于半数的集群master节点同意才能选举成功,如果只有两个master节点,当其中一个挂了,是达不到选举新master的条件的。
选项–cluster-replicas 1表示我们希望为集群中的每个主节点创建一个从节点。
分配原则尽量保证每个主库运行在不同的ip,每个主库和从库不在一个ip上,这样才能做到高可用。
5.5.什么是slots(槽)
如下图,咱们再来看看集群合并的过程中输出的一些信息

同样,执行get也会被重定向,效果如下

Redis集群内部划分了16384个slots(插槽),合并的时候,会将每个slots映射到一个master上面,比如上面3个master和slots的关系如下(通过cluster nodes命令也可以查看):
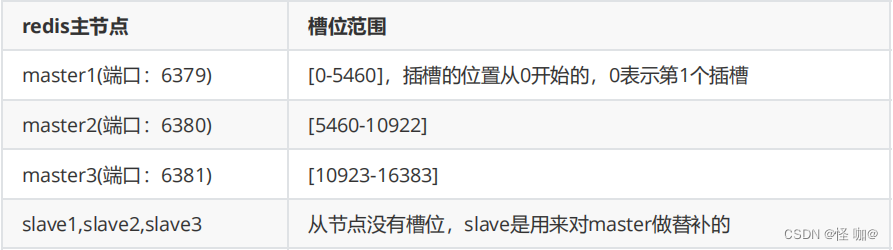
不在一个slot下面,不能使用mget、mset等多键操作,效果如下
- 同时设置多个值:mset
- 同时获取多个值:mget
上面set的一个a1在7785槽位,而a2 set后再11786槽位,两个不在一个槽位导致mget和mset命令异常

可以通过{}来定义组的概念,从而使key中{}内相同的键值放到一个slot中去,效果如下
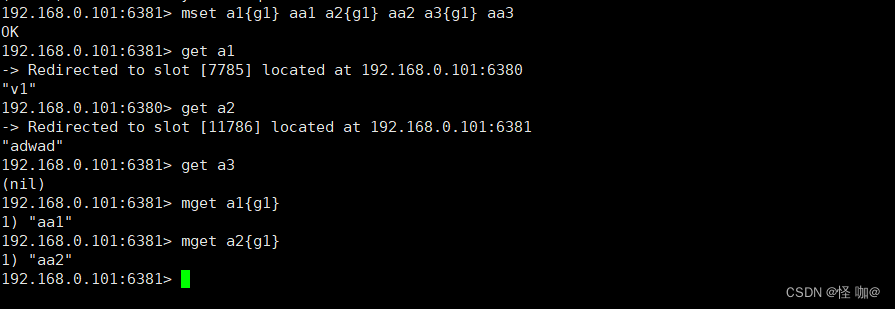
5.6.slot相关的一些命令
cluster keyslot :计算key对应的slot
cluster coutkeysinslot :获取slot槽位中key的个数
cluster getkeysinslot 返回count个slot槽中的键
192.168.0.101:6381> mget a1{g1} a2{g1} a3{g1}
1) "aa1"
2) "aa2"
3) "aa3"
192.168.0.101:6381> cluster countkeysinslot 13519
(integer) 3
192.168.0.101:6381> cluster getkeysinslot 13519 3
1) "a3{g1}"
2) "a2{g1}"
3) "a1{g1}"
5.7.AnotherRedisDesktopManager 客户端
AnotherRedisDesktopManager 一款比较稳定简洁的 redis UI 工具。可以使用集群方式连接,如下:
这时候我们set了好多值,其中值都被分到了不同的节点上
然我们连的只是一个节点,但是我们使用的是集群方式连接所以这里看到的是所有节点汇聚起来的全量数据!
5.8.故障恢复
如果主节点下线,从节点是否能够提升为主节点?注意:要等15秒
下面我们来试试,如下,连接master1,然后将master1停掉
[root@bogon cluster]# /opt/redis-stable/src/redis-cli -c -h 127.0.0.1 -p 6379 -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> shutdown

这是什么原因?不是按正常来说一个主机挂掉,从机应该故障恢复吗?怎么整个集群都宕机了。。。
查看了一下日志发现如下:出现大量的同步失败的日志。
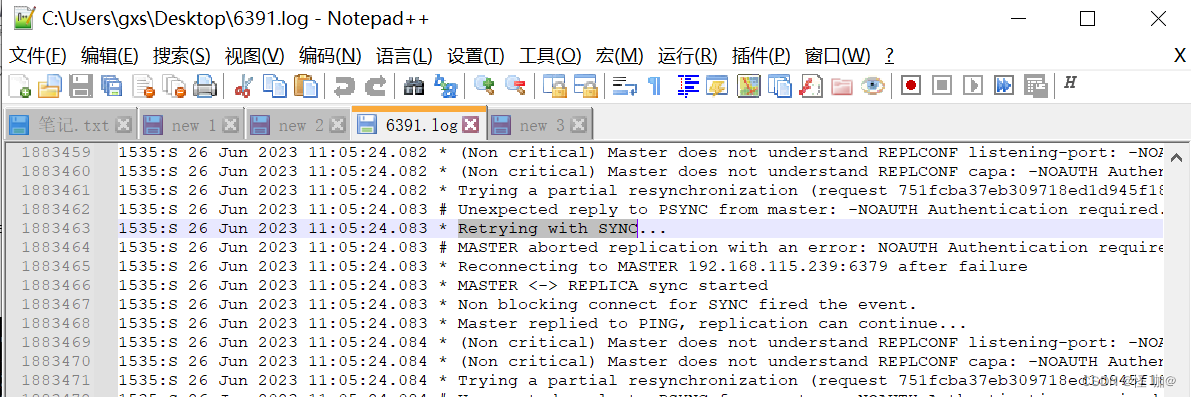
我们需要在从数据库当中配置主数据库的密码,不然他同步数据的时候会出现失败的情况,这样会导致他会一直在重连,日志文件也会一直在逐渐的变大。
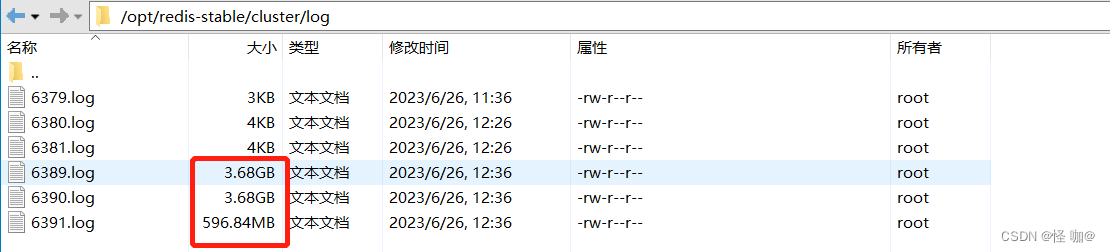
在所有的配置文件下添加:masterauth 123456 然后重启重新测试故障转移。
[root@bogon cluster]# /opt/redis-stable/src/redis-cli -c -h 127.0.0.1 -p 6379 -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> shutdown
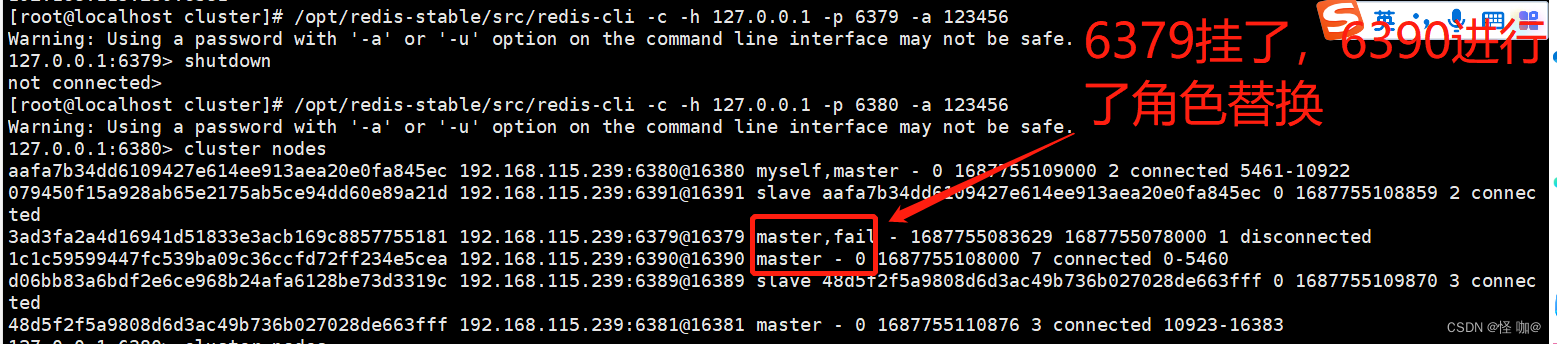
执行下面命令,连接master2,看下集群节点的信息
[root@localhost cluster]# /opt/redis-stable/src/redis-cli -c -h 127.0.0.1 -p 6380 -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6380> cluster nodes
下面我们再来启动6379,然后再看看集群变成什么样了,命令如下
[root@localhost cluster]# /opt/redis-stable/src/redis-server /opt/redis-stable/cluster/redis-6379.conf
[root@localhost cluster]# /opt/redis-stable/src/redis-cli -c -h 127.0.0.1 -p 6379 -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> cluster nodes

如果某一段插槽的主从都宕机了,redis服务是否还能继续?
这个时候要看 cluster-require-full-coverage 参数的值了
yes(默认值):整个集群都都无法提供服务了
no:宕机的这部分槽位数据全部不能使用,其他槽位正常
我们使用redis的主从同步的时候会发现在从机当中set值会异常,因为从机只可以读,而redis集群当中也有主从,但是他可以通过连接从机执行set,不会异常,只会将值存储到指定槽位的主数据库当中。
6、Redis cluster 优缺点
优点:
- 实现扩容
分摊压力
无中心配置相对简单
高可用,支持集群的主从配置,并且支持主从之间的故障转移
就算主从都挂掉,只会导致部分槽位不可用,其他的仍然可以提供服务!
提供了有关于槽位相关的命令,比如查看指定槽位的key,以及指定向哪个槽位存放数据等。
缺点:
- 多键操作是不被支持的
多键的Redis事务是不被支持的。lua脚本不被支持
由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。
六、Jedis连接cluster模式
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.4.2</version>
</dependency>
import redis.clients.jedis.*;
import java.util.HashSet;
import java.util.Set;
public class ClusterDemo {
public static void main(String[] args) {
JedisPoolConfig config = new JedisPoolConfig();
//最大空闲连接数, 默认8个
config.setMaxIdle(8);
//最大连接数, 默认8个
config.setMaxTotal(8);
//最小空闲连接数, 默认0
config.setMinIdle(0);
//获取连接时的最大等待毫秒数(如果设置为阻塞时BlockWhenExhausted),如果超时就抛异常, 小于零:阻塞不确定的时间, 默认-1
config.setMaxWaitMillis(3000);
//在获取连接的时候检查有效性,表示取出的redis对象可用, 默认false
config.setTestOnBorrow(true);
//redis服务器列表
Set<HostAndPort> cluster = new HashSet<>();
// 有多少节点这里就配置多少个
cluster.add(new HostAndPort("192.168.115.239", 6379));
cluster.add(new HostAndPort("192.168.115.239", 6380));
// connectionTimeout连接超时时间,soTimeout读取数据超时,maxAttempts重试次数,password密码
//public JedisCluster(Set<HostAndPort> jedisClusterNode, int connectionTimeout, int soTimeout, int maxAttempts, String password, String clientName, GenericObjectPoolConfig<Jedis> poolConfig) {
JedisCluster jedisCluster = new JedisCluster(cluster, 2000, 2000, 5, "123456", config);
jedisCluster.set("key", "hello world");
String aa1 = jedisCluster.get("aa1");
System.out.println(aa1);
jedisCluster.close();
}
}
七、SpringBoot整合cluster模式
(1)引入redis的maven配置
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
(2)application.properties中配置redis sentinel信息
# 集群节点(host:port),多个之间用逗号隔开
spring.redis.cluster.nodes=192.168.115.239:6379,192.168.115.239:6380,192.168.115.239:6381,192.168.115.239:6389,192.168.115.239:6390,192.168.115.239:6391
# 连接超时时间(毫秒)
spring.redis.timeout=60000
spring.redis.password=123456
# Redis默认情况下有16个分片,这里配置具体使用的分片,默认是0
database: 0
(3)使用RedisTemplate工具类操作redis
springboot中使用RedisTemplate来操作redis,需要在我们的bean中注入这个对象,代码如下:
@Autowired
private RedisTemplate<String, String> redisTemplate;
// 用下面5个对象来操作对应的类型
this.redisTemplate.opsForValue(); //提供了操作string类型的所有方法
this.redisTemplate.opsForList(); // 提供了操作list类型的所有方法
this.redisTemplate.opsForSet(); //提供了操作set的所有方法
this.redisTemplate.opsForHash(); //提供了操作hash表的所有方法
this.redisTemplate.opsForZSet(); //提供了操作zset的所有方法
(4)RedisTemplate示例代码
@RestController
@RequestMapping("/redis")
public class RedisController {
@Autowired
private RedisTemplate<String, String> redisTemplate;
/**
* string测试
*
* @return
*/
@RequestMapping("/stringTest")
public String stringTest() {
this.redisTemplate.delete("name");
this.redisTemplate.opsForValue().set("name", "路人");
String name = this.redisTemplate.opsForValue().get("name");
return name;
}
/**
* list测试
*
* @return
*/
@RequestMapping("/listTest")
public List<String> listTest() {
this.redisTemplate.delete("names");
this.redisTemplate.opsForList().rightPushAll("names", "刘德华", "张学友",
"郭富城", "黎明");
List<String> courses = this.redisTemplate.opsForList().range("names", 0,
-1);
return courses;
}
/**
* set类型测试
*
* @return
*/
@RequestMapping("setTest")
public Set<String> setTest() {
this.redisTemplate.delete("courses");
this.redisTemplate.opsForSet().add("courses", "java", "spring",
"springboot");
Set<String> courses = this.redisTemplate.opsForSet().members("courses");
return courses;
}
/**
* hash表测试
*
* @return
*/
@RequestMapping("hashTest")
public Map<Object, Object> hashTest() {
this.redisTemplate.delete("userMap");
Map<String, String> map = new HashMap<>();
map.put("name", "路人");
map.put("age", "30");
this.redisTemplate.opsForHash().putAll("userMap", map);
Map<Object, Object> userMap =
this.redisTemplate.opsForHash().entries("userMap");
return userMap;
}
/**
* zset测试
*
* @return
*/
@RequestMapping("zsetTest")
public Set<String> zsetTest() {
this.redisTemplate.delete("languages");
this.redisTemplate.opsForZSet().add("languages", "java", 100d);
this.redisTemplate.opsForZSet().add("languages", "c", 95d);
this.redisTemplate.opsForZSet().add("languages", "php", 70);
Set<String> languages =
this.redisTemplate.opsForZSet().range("languages", 0, -1);
return languages;
}
/**
* 查看redis机器信息
*
* @return
*/
@RequestMapping(value = "/info", produces = MediaType.TEXT_PLAIN_VALUE)
public String info() {
Object obj = this.redisTemplate.execute(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws
DataAccessException {
return connection.execute("info");
}
});
return obj.toString();
}
生产环境集群配置
redis:
cluster:
nodes: 192.168.70.176:6379,192.168.70.177:6380,192.168.70.178:6381,192.168.70.176:6389,192.168.70.177:6390,192.168.70.178:6391
#指定客户端在执行命令时允许的最大重定向次数。客户端会自动进行重定向,并跟随重定向指示执行命令
max-redirects: 3
#一般将其设置为5000毫秒。lettuce redis建立连接超时时间connectTimeout,默认:10S。Duration类型配置S或s和M结尾都一样。或者毫秒。
connect-timeout: 5000
password: xxxx
database: 0
lettuce:
cluster:
refresh:
#拓扑动态感应即客户端能够根据 redis cluster 集群的变化,动态改变客户端的节点情况,完成故障转移。自动刷新集群 默认false关闭
adaptive: true
# 是否发现和查询所有群集节点以获取群集拓扑。设置为false时,仅将初始种子节点用作拓扑发现的源
#dynamic-refresh-sources: true
#集群拓扑刷新周期。定时刷新。10M
#period: 30s
#连接池中的关闭超时时间。关机超时时限。宕机超时时间,默认100ms。
#shutdown-timeout: 1s
pool:
#连接池最大连接数(使用负值表示没有限制)默认是:8。
max-active: 100
#连接池中的最大空闲连接。默认是:8。设置在 max-active 的一半到三分之二,例如 25 到 50。
#当连接池中的连接数超过 max-idle 时,多余的连接将被关闭并从连接池中移除。太多的 max-idle 值可能会导致服务器资源消耗过多
max-idle: 50
#连接池最大阻塞等待时间(使用负值表示没有限制)。如 -1
max-wait: 2000
#连接池中的最小空闲连接 默认是0。设置为一定数量,例如 10,以确保始终有一定数量的空闲连接可用。
min-idle: 5
#配置空闲连接回收间隔时间,min-idle才会生效,否则不生效
time-between-eviction-runs: 2000
#lettuce redis命令操作超时时间timeout,默认:60S。读取超时。
timeout: 5000














 922
922











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









