







使用计算机视觉在传送带上实时检测和计数物体
在许多制造环境中,传送带用于在生产的各个阶段运输物体,特别是螺栓、螺母或其他紧固件等小部件。能够实时可靠地统计这些物品可以改善库存管理、质量保证和整体效率。本文中我们将介绍一种使用计算机视觉检测和计数传送带上物体的端到端方法。我们将关注的场景是计算沿输送线移动的螺栓和螺母,但这种方法也适用于其他物体和环境。该项目涉及以下步骤:
数据集准备与标注
准确的目标检测始于注释良好的数据。你的第一步是收集代表现实世界条件的图像或视频帧。
数据收集
录制短视频:从不同角度和不同光照条件下拍摄螺栓和螺母(或您选择的物体)的1-2分钟片段。确保视频涵盖了可能遇到的各种情况,包括不同的背景、遮挡和物体密度。这将有助于模型学习识别物体的关键特征,并提高其泛化能力。
提取帧

使用Roboflow或OpenCV,自动将视频转换为帧。每秒大约1-2个图像帧就足够了,可以平衡全面覆盖和可管理的数据集大小。例如,对于一个60秒的视频,以每秒两帧的速度抽取,最终将得到约120张图片。这不仅简化了后续处理,还减少了训练所需的时间和资源。
自动数据标注
带有自动标签的自动注释:的内置自动标签功能利用了先进的短语接地模型——Grounding DINO,根据简单的文本提示为对象建议边界框。例如,输入提示如“螺栓”和“六角螺母”。这种方法大大加快了标注过程,同时保持了高精度。如果需要更精细控制,还可以手动调整生成的边界框。
数据集拆分
将带标注的数据集拆分为训练集(70%)、验证集(20%)和测试集(10%)。这样的分割比例有助于确保模型既能在已知数据上表现良好,也能对未见过的数据做出准确预测。
预处理
应用数据增强,如水平翻转、亮度调整或随机裁剪,以提高模型对现实世界变化的鲁棒性。数据增强技术通过模拟各种成像条件,使模型更加通用,从而在实际部署中表现出更好的性能。

模型训练过程
一旦你的数据集被标注和整理,是时候训练你的模型了。简化了这一过程,消除了设置训练管道通常带来的大部分复杂性。
训练流程
- 选择模型:选择以MS COCO检查点为起点的3.0模型。这个预训练的主干利用了从数万个日常物品中学习到的丰富特征,让你的模型领先一步。
- 启动训练:直接从浏览器开始培训。处理基于云的训练基础设施,使您能够专注于模型的性能。
- 监控指标:在大约20分钟内,您将看到平均精度(mAP)、损失曲线甚至混淆矩阵等性能指标。评估模型是否能够可靠地区分螺栓和螺母,并在需要时使用这些见解进行迭代。
- 快速验证:训练后,使用的实时推理工具——使用智能手机扫描二维码或上传图像——测试模型的检测能力。这种即时反馈机制可以帮助快速识别潜在问题并优化模型配置。
当然,上面的步骤也可以使用YOLOv8或者YOLOv11来完成,这两个模型以其速度和准确性而闻名,非常适合工业应用场景。
构建跟踪和计数逻辑
单独的检测模型输出可能不足以进行准确计数。对象可能出现在多个帧中,从而导致重复计数。这就是工作流的用武之地,您可以将后处理步骤链接在一起,将原始检测转换为有用的可部署应用程序。
创建工作流
- 添加对象检测:从训练好的检测模型开始,作为工作流中的第一个块。
- 集成ByteTrack进行跟踪:添加一个跟踪块(我们将使用ByteTrack),为跨帧的对象分配一致的ID。这可以防止在同一物体沿传送带移动时对其进行多次计数。
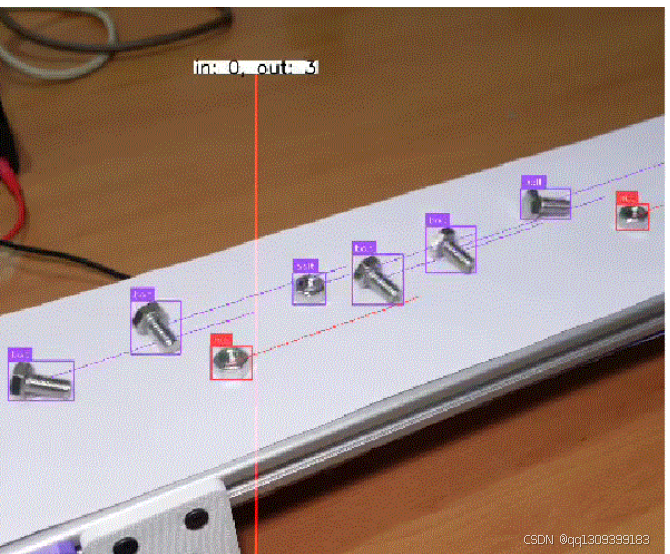
- 基于行的计数:添加行计数器定义传送带框架上的一条或多条虚拟线。当一个对象穿过一条线时,它会递增计数。
- 可视化块:包括可视化块,以便您可以实时查看边界框、对象ID和计数覆盖。这些信息不仅可以帮助调试系统,还可以提供给操作人员作为实时监控工具。
本地部署
在中定义并测试了您的工作流程后,是时候将其应用于现实世界了。对于视频推断,您可以使用专用部署(连接到分配给您使用的云服务器)或本地主机。在本项目中,我们将重点介绍Localhost,以便您可以在本地计算机上运行工作流。
本地部署步骤
- 安装环境:按照推理文档的指导,安装Python、Docker,并运行
pip install inference-cli && inference-server start。这将设置必要的软件环境,使您能够在本地机器上执行推理任务。 - 拉取推理服务器:使用Roboflow inference拉取推理服务。这一步骤确保了最新的模型权重和依赖项已经被下载到本地环境中。
- 运行Python应用程序:编写一段Python代码来读取视频流,调用工作流进行推理,并将结果保存为.mp4文件。这段代码还将实时显示推理结果,让用户直观地观察到系统的性能。
# Import the InferencePipeline object
from inference import InferencePipeline
import cv2
# Define the output video parameters
output_filename = "output_conveyor_count.mp4" # Name of the output video file
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # Codec for the MP4 format
fps = 30 # Frames per second of the output video
frame_size = None # Will be determined dynamically based on the first frame
# Initialize the video writer object
video_writer = None
def my_sink(result, video_frame):
global video_writer, frame_size
if result.get("output_image"):
# Extract the output image as a numpy array
output_image = result["output_image"].numpy_image
# Dynamically set the frame size and initialize the video writer on the first frame
if video_writer is None:
frame_size = (output_image.shape[1], output_image.shape[0]) # (width, height)
video_writer = cv2.VideoWriter(output_filename, fourcc, fps, frame_size)
# Write the frame to the video file
video_writer.write(output_image)
# Optionally display the frame
cv2.imshow("Workflow Image", output_image)
cv2.waitKey(1)
# Initialize a pipeline object
pipeline = InferencePipeline.init_with_workflow(
api_key="*******************",
workspace_name="[workspace_name]",
workflow_id="[workflow_id]",
video_reference="[video_reference]", # Path to video, device id (int, usually 0 for built-in webcams), or RTSP stream URL
max_fps=30,
on_prediction=my_sink
)
# Start the pipeline
pipeline.start()
pipeline.join() # Wait for the pipeline thread to finish
# Release resources
if video_writer:
video_writer.release()
cv2.destroyAllWindows()
现在,您可以开始实时处理视频帧。当对象通过行计数器时,观察计数会自动更新。此解决方案不仅提高了生产线上物品计数的准确性,还提供了宝贵的数据,可用于进一步分析和优化生产流程。此外,该系统易于扩展,可以根据特定需求定制,成为强大的生产级解决方案的一部分。
代码数据获取
文章底部卡片获取


















 336
336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









