







JDK版本:jdk-6u45-linux-x64.bin
(下载网址:http://www.oracle.com/technetwork/java/javase/downloads/index.html,请到Previous Releases里面找)
Hadoop版本:hadoop-0.20.203.0rc1.tar.gz
(网上大多数教程都是这个版本的,其实新版的已经出了很久了,但是新版的教程很少,学习阻力太大,所以暂时还是用这个版本吧)
用到的所有文件都存放在/home/kevin 目录下(我的用户组的名字是kevin,也就是存放在Documents文件夹所在的目录),要不然后面会遇到很多权限的问题,而且,最好不要用root用户登录,虽然网上很多教程都说转到root用户下,这样做不好。
1、安装Hadoop的运行环境——JDK
其实安装JDK很简单。下载好JDK,修改权限:
|
1
|
sudo chmod u+x jdk-6u45-linux-x64.bin
|
然后执行如下解压语句:
|
1
|
sudo ./jdk-6u45-linux-x64.bin
|
一长串解压过程飞速闪过之后,JDK就解压完了。
但是也有像我一样没怎么学过linux的新手,执行这条命令时不成功。观察他们的命令,发现他们没有进到jdk所在的文件夹,而直接在“/”后面输入了jdk所在的绝对路径。只是不能成功的,应该进入到jdk所在的文件夹,或者将jdk拷贝到当前路径。
现在,配置环境变量。打开profile文件:
|
1
|
sudo gedit /etc/profile
|
将下面几行添加到文件末尾:
|
1
2
3
|
export JAVA_HOME=/home/kevin/jdk
export HADOOP_HOME=/home/kevin/hadoop
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
|
最后,文件如下:

其中,hadoop的地址也一次性加到了其中。最后,保存退出。
执行如下命令,更新环境变量(这一步也可以放在Hadoop安装完成后执行):
|
1
|
source /etc/profile
|
现在输入如下命令可以验证Java是否安装成功:
|
1
|
java -version
|
如果显示如下,则表示安装成功:

现在,Java安装完成~~~~~
2、配置SSH无密码登录:
首先,更新一下系统(其实不必要,主要是因为有可能安装openssh-server不成功,所以,还是先更新一下吧)
|
1
|
sudo apt-get update
|
一长串更新进程结束后,开始安装SSH。
执行如下命令安装openssh-server:
|
1
|
sudo apt-get install openssh-server
|
跑完后就安装成功。
接下来,配置无密码登录:
|
1
|
ssh-keygen -t rsa -P
""
|
出现如下提示:

这是让你输入公钥和私钥的存放路径,括号里的表示默认路径,这里直接回车,选用默认路径。
然后显示如下:

这将生成一个隐藏文件 .ssh,进入这个文件夹,然后将公钥追加到authorized_keys文件中,此文件最初并不存在,但执行追加命令后将自动生成:
|
1
2
|
cd .ssh
cat id_rsa.pub >> authorized_keys
|
如图:

最后,验证是否安装成功。用能否登录本机来验证,命令如下:
|
1
|
ssh localhost
|
显示如下:

输入yes(不用在意其中的“can't be established”提示),回车,显示如下:

然后执行退出命令:
|
1
|
exit
|
如图:

现在,无密码登录配置成功~~~~
3、终于开始安装Hadoop了
下载好Hadoop,然后修改权限:
|
1
|
sudo chmod
777
hadoop-
0.20
.
203
.0rc1.tar.gz
|
然后解压:
|
1
|
sudo tar zxvf hadoop-
0.20
.
203
.0rc1.tar.gz
|
修改解压出来的文件夹的权限(可以看到,解压出来的文件夹上有个灰颜色的锁,至少我这儿是这样)
|
1
|
sudo chmod
777
-R hadoop-
0.20
.
203
|
也可以将文件夹的名字改得短一点,后文中笔者就用改后的名字:
|
1
|
mv hadoop-
0.20
.
203
hadoop
|
解压工作完成,现在开始配置:
进入hadoop/conf文件夹中
|
1
|
cd hadoop/conf
|
打开hadoop-env.sh文件,找到exportJAVA_HOME这句话,去掉注释标记,等号后面改成你的JDK路径,保存退出
如图:
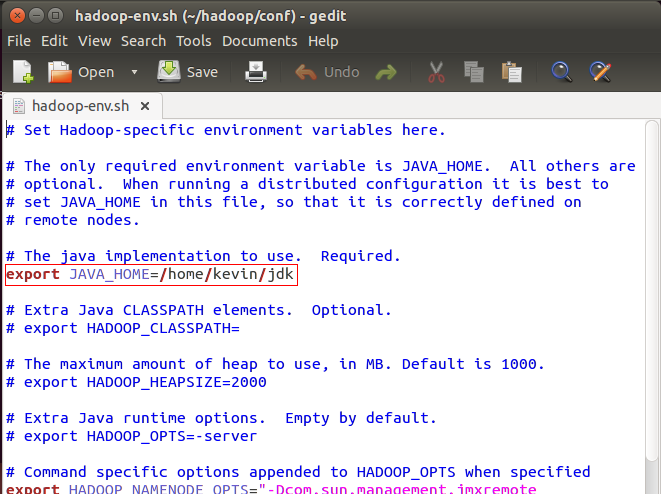
红框位置,图为去掉#号后的截图
接下来将配置三个文件core-site.xml,hdfs-site.xml,mapred-site.xml,其中,加入的内容都在<configuration>与</configuration>之间添加,后面不在一一赘述
配置hdfs-site.xml文件:
加入如下内容:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
<property>
<name>dfs.replication</name>
<value>
1
</value>
</property>
<property>
<name>dfs.permissions</name>
<value>
false
</value>
</property>
<property>
//用于存放主节点的信息,比如fsimage文件(这个文件相当重要,没有他无法读取HDFS的内容),一般设置多个地址,
//只需在<value>与</value>之间以逗号分隔每个地址
<name>dfs.name.dir</name>
<value>/home/kevin/hadoop/namedata</value>
</property>
<property>
//设置从节点数据的存放位置,也可以设置多个
<name>dfs.data.dir</name>
<value>/home/kevin/hadoop/data</value>
</property>
|
保存退出。
配置core-site.xml文件:
加入如下内容(此文件千万别复制哦~~~~~):
|
1
2
3
4
5
6
7
8
|
<property>
<name>fs.
default
.name</name>
<value>hdfs:
//kevin:9000</value> //将kevin改成各位@后面的名字
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/kevin/hadoop/tmp</value>
</property>
|
保存退出
配置mapred-site.xml文件:
如下(别复制哦~~~):
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
<property>
<name>mapred.job.tracker</name>
<value>kevin:
9001
</value>
//将“kevin”改成各位的用户组(@后面那个)的名字
</property>
//一下的内容可以暂时不用设置,但从经验来看,还是设置一下为好
<property>
//一个节点上最大能运行的Map数量(默认是两个,但从经验来看,数据量大而机器又旧,两个是带不起来的)
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>
1
</value>
</property>
<property>
//每个节点最大能运行的reduce数量,默认是1个,这里写出来是为了让大家知道在哪里改这个数据
<name>mapred.tasktracker.reduce.tasks.maximum</name>
<value>
1
</value>
</property>
<property>
//我相信大家一定会遇到“java heap space”的问题,除非各位是算法高手,并且机器内存很大
//这个用于设置程序运行时(jvm虚拟机)的内存容量
<name>mapred.child.java.opts</name>
<value>-Xmx4096m</value>
</property>
|
所有配置都已完成,现在格式化:
执行如下命令:
|
1
|
hadoop namenode -format
|
出现如下画面:

各位不用去一行一行对照看是不是一样,接下来的操作一样可以验证。
有的人在执行这句命令时可能出现hadoop : command not found。这是因为环境变量中没有该命令,而这就极可能是没有刷新/etc/profile文件,再执行一次jdk安装时的source命令即可。或者,也可以执行如下命令,不过前提是进入到hadoop文件夹:
|
1
|
sudo bin/hadoop namenode -format
|
但还是建议大家source一下profile文件,要不然以后都只有进入到bin文件夹中才能hadoop上的操作
启动hadoop:
|
1
|
start-all.sh
|
出现如下过程:
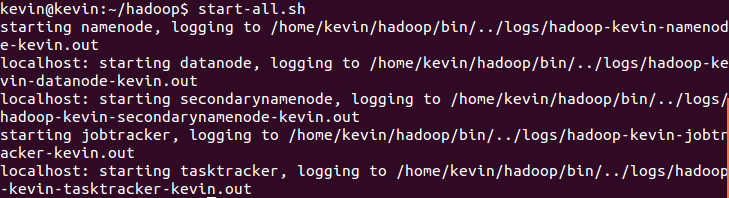
表示启动成功~~
输入jps看有几个java进程(成功的话应该有如下五个,不算Jps进程):

安装成功~~~~~
此处有可能无法启动DataNode,笔者遇到的主要原因是多次格式化,而以前的tmp和logs文件夹没有删除所致。删除这两个文件夹,然后新建即可(别忘了该权限哦)
可以打开浏览器看看。在浏览器地址栏中输入kevin:50070和kevin:50030

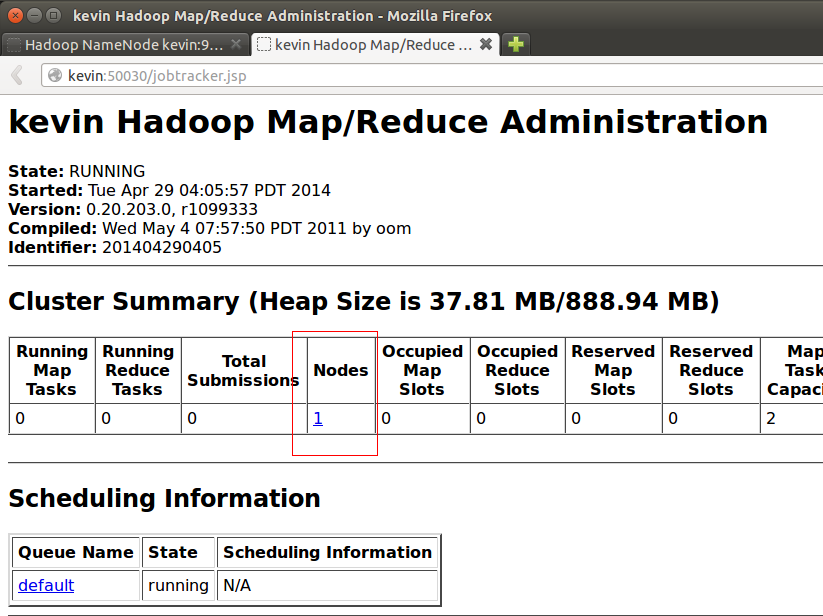
上面的是50070的,下面的是50030的。
配置成功了~~~~~~~
现在,来跑一个入门的程序wordcount吧:
在Hadoop的HDFS文件系统上建立一个input文件夹,作为输入源,命令如下:
|
1
|
hadoop fs -mkdir input
|

将一个测试文件上传到input文件夹中,测试文件的内容就是“hello world,hello hadoop"。执行如下命令:
|
1
|
hadoop fs -put /home/kevin/Desktop/hello.txt input
|
然后执行Hadoop自带的测试程序wordcount,命令如下:
|
1
|
hadoop jar hadoop-examples-
0.20
.
203.0
.jar wordcount input output
|
然后等待它跑完吧:
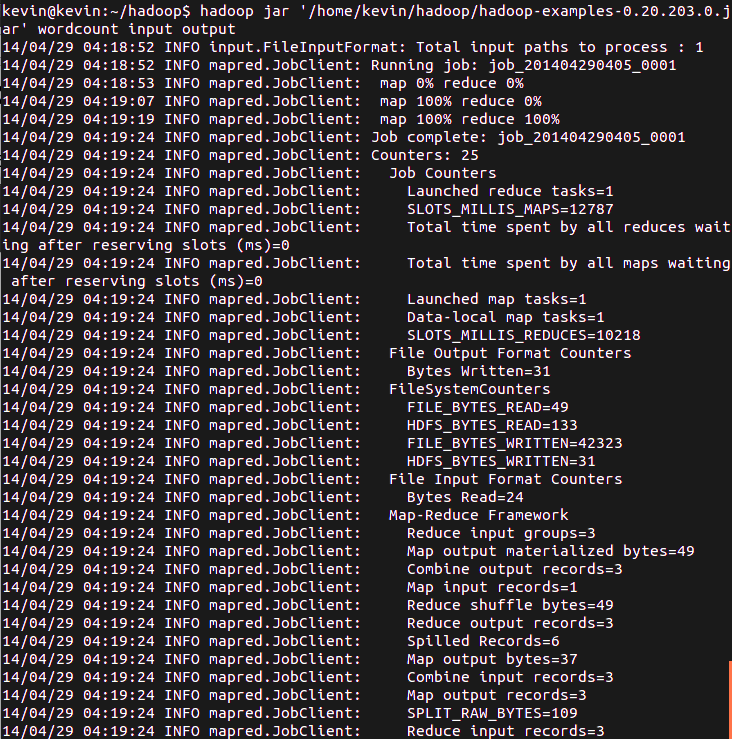
看看结果是否正确。显示结果的内容,命令如下:
|
1
|
hadoop fs -cat output/part-r-
00000
|
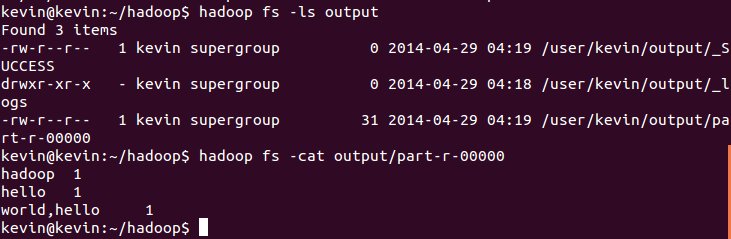
OK~~~Hadoop安装成功,也能跑了~~~~















 1556
1556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









