







1.DNN-HMM混合系统
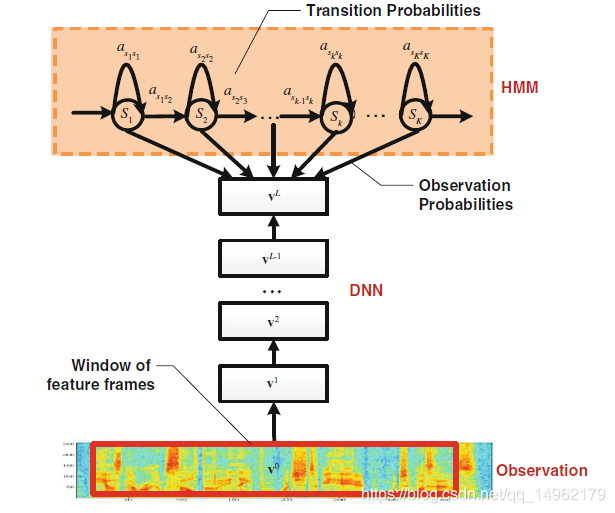
[HMM对语音信号的序列特性进行建模,DNN对所有聚类后的状态(聚类后的三音素状态)的似然度进行建模。对时间上的不同点采用同样的DNN]
HMM描述语音信号的动态变化,DNN估计输入特征的观测概率。在给定声学观察特征的条件下,用DNN的每个输出节点来估计连续密度HMM的某个状态的后验概率。
早期对上下文相关(音素状态绑定)的后验概率建模为:
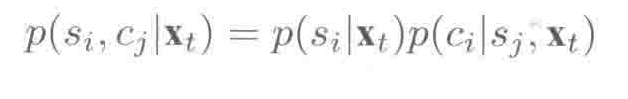
或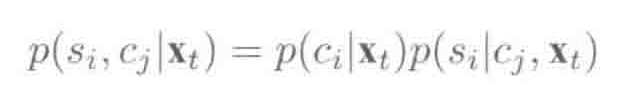
Xt是t时刻的声学观察值,Cj是聚类后的上下文状态,Si是上下文无关的单音素或音素中的状态。
提高语音识别性能的方法:
深层网络代替浅层网络;
使用聚类后的状态(绑定后的三因素状态)代替单音素状态作为神经网络的输出单元;
DNN的输入不是采用单一的一帧,而是采用上下文窗口,使得相邻帧的信息可以被有效利用。
DNN和GMM的区别是:在CD-DNN-HMM中,对所有状态s,只训练一个完整的DNN来估计状态的后验概率p(qt=s|Xt),而GMM是使用多个不同的GMM分别对每一个状态建模。
2.用CD-DNN-HMM解码
解码使用贝叶斯公式:
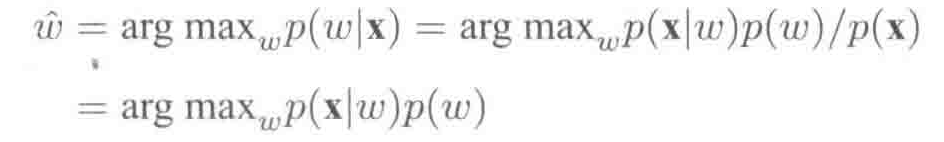
p(w)是语言模型(LM)概率,
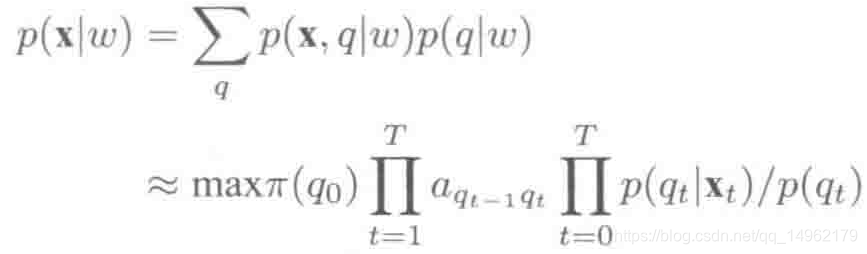
p(x|w)是声学模型(AM)概率。feature->state->words.
其中,p(qt|xt)是由DNN计算得出的观察概率,p(qt)是状态先验概率,是从训练集中统计qt状态的先验概率,等于属于状态s的帧数除以总帧数。pai(q0)是初始状态概率,aqt-1qt是状态转移概率,由HMM决定。
与GMM-HMM中类似,语言模型权重系数lambda通常被用于平衡声学和语言模型得分。最终解码路径由以下公式确定:

3.CD-DNN-HMM训练
使用嵌入的维特比算法来训练CD-DNN-HMM
CD-DNN-HMM包含三个组成部分:dnn,hmm,一个状态先验概率分布prior,即p(qt)。
训练步骤:

CD-DNN-HMM和CD-GMM-HMM系统共享音素绑定结构,即共享HMM拓扑结构。
2.使用训练数据训练一个CD-GMM-HMM系统,DNN训练标注是由GMM-HMM系统采用维特比算法得到的。
3.使用已经训练好的GMM-HMM模型hmm0,在训练数据上采用维特比算法生成一个状态层面的强制对齐。
4.利用stateTosenoneIDMap,把状态名转换为senoneID;
5.生成特征到senoneID的映射对(featuresenoneIDPairs).
6.预训练ptdnn,可以省略;
7.GMM-HMM转换为DNN-HMM,包含于hmm0相同的转移概率。
8.featuresenoneIDPairs用来估计senone先验概率。
9.反向传播计算梯度;
10.更新值。
对含有T帧的句子,嵌入的维特比训练算法最小化交叉熵的平均值,其等价于负的对数似然:
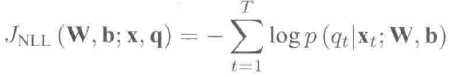
4.输入帧上下文窗口的影响
引入相邻帧,DNN可以对不同特征之间的相互关系进行建模,这样部分缓和了传统的HMM无法满足观察值独立性假设的问题。
每个字词序列的分数为:
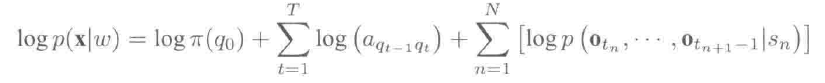
T是特征的长度,N<=T是状态序列的长度,sn是状态序列中第n个状态,qt是t时刻的状态,tn是第n个状态的起始时间。假设状态时长可以用一个马尔科夫链模拟。
观察值分数logp(otn,…,otn+1 -1|sn)表示给定状态的情况下,观察到的特征段的对数似然概率,可被用于基于分段的模型。
在HMM中,每个特征帧都假设与其它特征帧条件独立,因此:
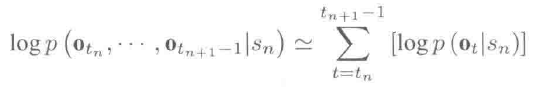














 94
94











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









