







主要思路:相同key值的消息写入同一个partition(partition内的消息是有序的),一个partition的消息只会被一个消费者消费。
如果一个消费者是多个线程消费,则需要把pull来的消息按照key值写入不同的内存队列中,相同key值的消息写入同一个内存队列(内存队列内的消息是有序的),然后一个线程消费一个内存队列。
kafka
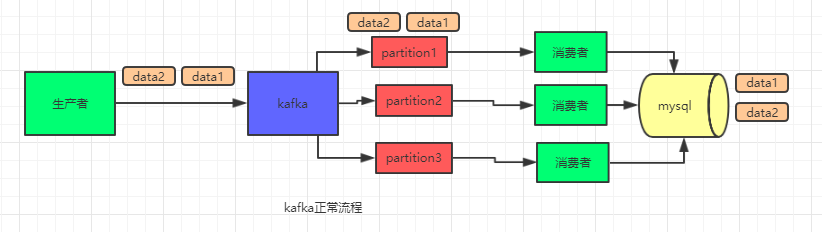
如图,在 kafka 中,你对数据指定某个 key,那么这些数据会到同一个 partition 里面,在 partition 里面这些数据是有顺序的。从这里看没啥问题,插入到数据库的数据都是有序的。
但是,我们在消费端可能会使用多线程来处理,因为单线程的处理速度慢,为了加快处理时间和吞吐量,会使用 thread 来处理。在消费端加入线程之后,就会出现顺序不一致的情况。
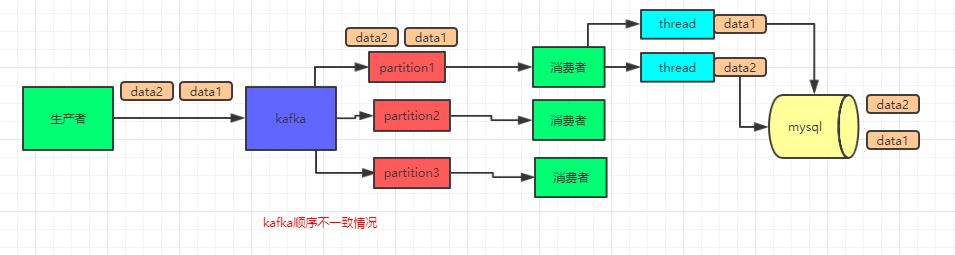
如图,就是使用了多线程之后,数据顺序不一致情况。
在使用了多线程之后,如何来解决数据顺序问题?
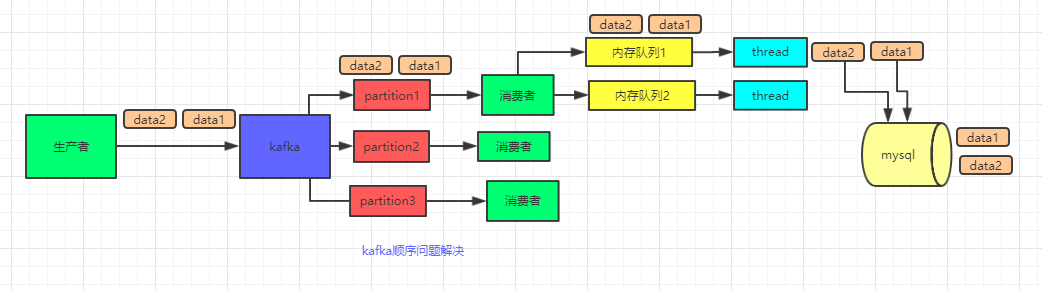
如图,在消费端使用内存队列,队列里的数据使用 hash 进行分发,每个线程对应一个队列,这样可以保证数据的顺序。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









