










自组织映射
自组织映射是一种基于拓扑表示法的数据降维技术。这样的技术有很多,其中主成分分析便是比较有名的一种。然而,作为降维技术和可视化形式,自组织映射自有其独到之处。
自组织映射入门
自组织映射算法需要反复迭代一些简单的操作。在目标数据集很小时,自组织映射与k均值聚类非常类似(后面很快会讲到);目标数据集较大时,自组织映射就会用一种强大的方式展现复杂数据集的拓扑结构。
自组织映射是由许多节点构成的网格(一般是矩形或六边形),每个节点都包含一个权重向量,该权重向量的维度与输入数据集相同。节点可以随机初始化,但与数据集分布大致相似的初始化能令算法训练得更快。
算法会随观测值的输入而迭代,迭代的形式如下所示。
- 找出现有配置下的激活节点,即最佳匹配单元(best matching
unit,BMU)。通过度量输入向量与所有权重向量间的欧几里得距离,可以决定BMU1。 - 根据输入向量调整BMU(将BMU向输入向量移动)。
- 通常以较小量调整临近节点2,临近节点调整的幅度由邻域函数决定。(邻域函数有很多种,使用高斯邻域函数。)
与输入向量距离最近的权重向量所在节点即最佳匹配单元。
即优胜邻域内的节点,其中优胜邻域也是由邻域函数决定的。
该过程可能会重复多次,并运用合适的取样方法,直到网络收敛(当新输入项增加时,损失无法进一步降低)。
与神经网络的节点不同,自组织映射的节点通常会包含一个长度与输入数据集维度相同的权重向量,也就是说,输入数据集的拓扑结构可以用一个低维映射来存储并进行可视化。
目前,先在熟悉的环境下应用自组织映射算法。
部署自组织映射
前面提到过,自组织映射算法是迭代的,建立在向量间欧几里得距离之上。
该映射会形成一个清晰易读的2D网格。就通用的鸢尾花教学数据集来说,自组织映射可以非常简洁地进行映射(见图1-8)。
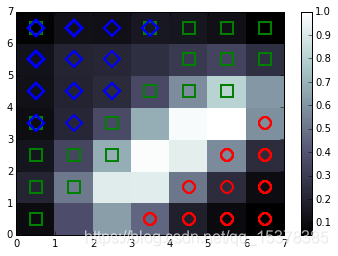
图 1-8
图中的类得到了有效划分,且按空间进行了排序。此例中的背景色代表的是聚类密度。蓝色类和绿色类出现了细微的重叠,此处自组织映射的分类也不够理想。在鸢尾花数据集中,自组织映射会在100次迭代后得到收敛的解决方案,而迭代增加到1000次时,效果提升并不明显。对分类不清的更复杂的数据集来说,该过程可能会持续成千上万次迭代。
尴尬的是,Python目前没有类似scikit-learn这种包含自组织映射算法的包。因此,我们必须自己动手实现。
我们将处理的自组织映射代码位于相应的GitHub库中。现在我们先来看一下相关脚本,并大致理解代码的运行。
import numpy as np
from sklearn.datasets import load_digits
from som import Som
from pylab import plot,axis,show,pcolor,colorbar,bone
digits = load_digits()
data = digits.data
labels = digits.target
至此,我们就加载好了digits数据集,并根据数据标签定义了变量labels。这样做可以方便我们观察自组织映射算法是如何通过低维映射进行类区分的。
som = Som(16,16,64,sigma=1.0,learning_rate=0.5)
som.random_weights_init(data)
print("Initiating SOM.")
som.train_random(data,10000)
print("\n. SOM Processing Complete")
bone()
pcolor(som.distance_map().T)
colorbar()
这里我们使用了Som.py文件中定义的Som类,该类包含了我们用来实现自组织映射算法的方法。我们将提供映射的维度(经过一系列尝试后,本例将16×16作为网格规模,因为这样的网格规模能够给特征映射留有充足的延伸空间,即使仍可能存在一些簇间的重叠)和输入数据的维度(用来确定自组织映射节点的权重向量的维度)作为函数的参数,同时提供sigma值和学习率。
本例中的sigma定义了邻域函数的覆盖范围。如前文所述,我们使用的是高斯邻域函数。最恰当的sigma值与网格规模有关。对8×8的网格来说,sigma的值一般取1.0,而本例16×16的网格对应的最佳sigma值为1.3。sigma取值不恰当是很容易发现的。当sigma过小时,数据点会在网格的中心聚集;当sigma过大时,网格中心就会出现若干较大空白。
不言自明,指标学习率指的是自组织映射的初始学习率。随着映射的迭代,学习率会根据以下公式进行调整:
学 习 率 ( t ) = 学 习 率 / ( 1 + 0.5 ∗ t ) 学习率 (t) = 学习率 / (1+0.5*t) 学习率(t)=学习率/(1+0.5∗t)
其中t为迭代指数。
先用随机权重来初始化我们的自组织映射。
与k均值聚类相同,自组织映射的随机初始化比基于近似数据分布的初始化要慢。应用与k均值++算法相似的预处理步骤,可以节约自组织映射的运行时间。目前来看,我们的自组织映射已经在digits数据集上运行得很快了,因此没必要进行这样的优化。
接下来,给每个类定义标签并分配颜色,以便在自组织映射图像中区分它们。然后遍历每个数据点。
每次迭代时,都要根据自组织映射算法的计算结果标出表明类的BMU。
自组织映射结束迭代时,需要添加U矩阵(一种表示相对观测密度的颜色矩阵)作为一个单色图层:
labels[labels == '0'] = 0
labels[labels == '1'] = 1
labels[labels == '2'] = 2
labels[labels == '3'] = 3
labels[labels == '4'] = 4
labels[labels == '5'] = 5
labels[labels == '6'] = 6
labels[labels == '7'] = 7
labels[labels == '8'] = 8
labels[labels == '9'] = 9
markers = ['o', 'v', '1', '3', '8', 's', 'p', 'x', 'D', '*']
colors = ["r", "g", "b", "y", "c", (0,0.1,0.8), (1,0.5,0), (1,1,0.3),
"m", (0.4,0.6,0)]
for cnt,xx in enumerate(data):
w = som.winner(xx)
plot(w[0]+.5,w[1]+.5,markers[labels[cnt]],
markerfacecolor='None', markeredgecolor=colors[labels[cnt]],
markersize=12, markeredgewidth=2)
axis([0,som.weights.shape[0],0,som.weights.shape[1]])
show()
以上代码可以得到的图像如图1-9所示。
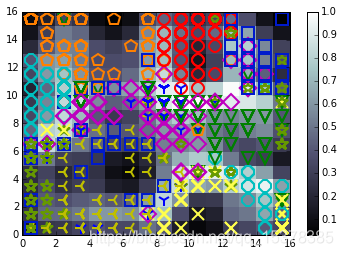
图 1-9
这段代码生成了一幅16×16个节点的自组织映射图像。由图可知,映射成功将每个簇分离成了拓扑上截然不同的图像区域。虽然其中几个类(尤其是蓝绿色圆圈代表的数字5和绿色星号代表的数字9)出现在了自组织映射空间的许多位置,但大多数情况下,每个类都单独占据一块区域,这说明自组织映射还是非常有效的。U矩阵表明,数据点密度较高的区域往往会包含多个类的数据,这一点我们在k均值聚类和主成分分析图像中早已见过,并不足为奇。















 859
859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









