






1. 白皮书
第五天的白皮书提供了一份 AI Agents 运营生命周期的全面技术指南。重点关注 Agent 的部署、扩展与生产化落地。
搭建一个 AI agent 原型只需要几分钟,甚至几秒钟就能完成。但要把这个看似精巧的演示版本,打磨成企业可信赖、能稳定依赖的生产级系统,真正的考验才刚刚开始。这便是行业内常说的 “最后一公里” 生产鸿沟。我们在与客户的实际合作中发现,推进 agent 落地的过程里,约 80% 的精力并非用于优化 agent 的核心智能,而是投入到基础设施搭建、安全防护强化与合规验证等工作中,唯有做好这些,才能确保 agent 可靠、安全地运行。
Agent 具备自主交互能力、状态持续性,且执行路径动态可变 —— 这些特性使其运营复杂度远超传统系统,也因此带来了三类独特的运营痛点,需要针对性策略破解:
- 动态工具编排(Dynamic Tool Orchestration):agent 会根据任务需求实时选择、组合工具,形成独特的 “执行轨迹”。这意味着系统需要具备稳健的版本管理、严格的权限控制与全面的可观测性(observability),以应对 agent 每次运行时截然不同的行为模式。
- 可扩展状态管理(Scalable State Management):agent 能在多轮交互中保留 “记忆”,而如何在大规模场景下,安全且一致地管理会话与记忆数据,是系统设计层面的复杂难题。
- 不可预测的成本与延迟(Unpredictable Cost & Latency):agent 获取答案的路径灵活多变,若缺乏智能预算管控与缓存机制,其运行成本与响应时间将难以预估和控制,可能给企业带来隐性的资源浪费。
要成功跨越这些障碍,搭建 Agent 生产化的坚实基础,需依托三大核心支柱:自动化评估(Automated Evaluation)、自动化部署(CI/CD) 与 全面可观测性(Comprehensive Observability)。
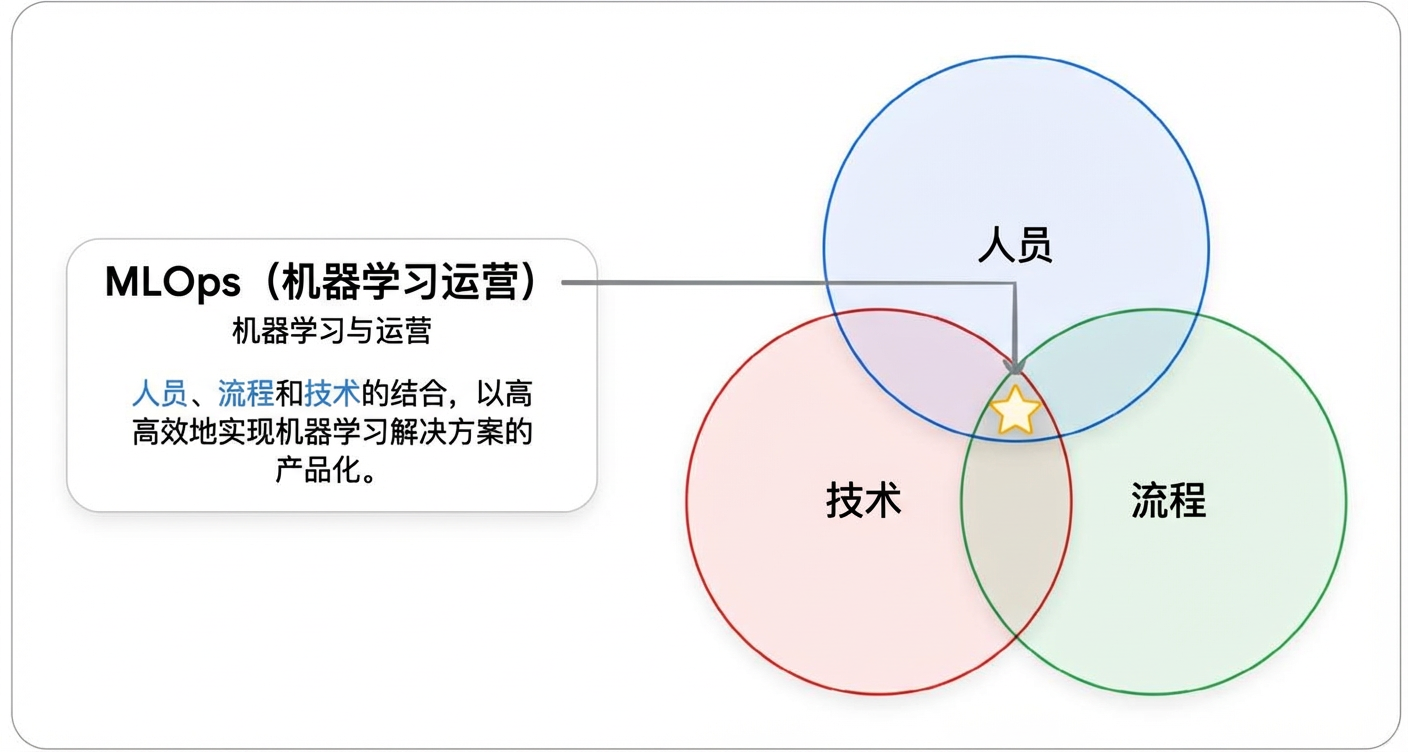
1.1. 人和流程
在谈论了那么多关于持续集成/持续部署、可观测性和动态流水线之后,为什么要把重点放在人员和流程上呢?因为如果没有合适的团队来构建、管理和治理,世界上最好的技术也会变得无效。
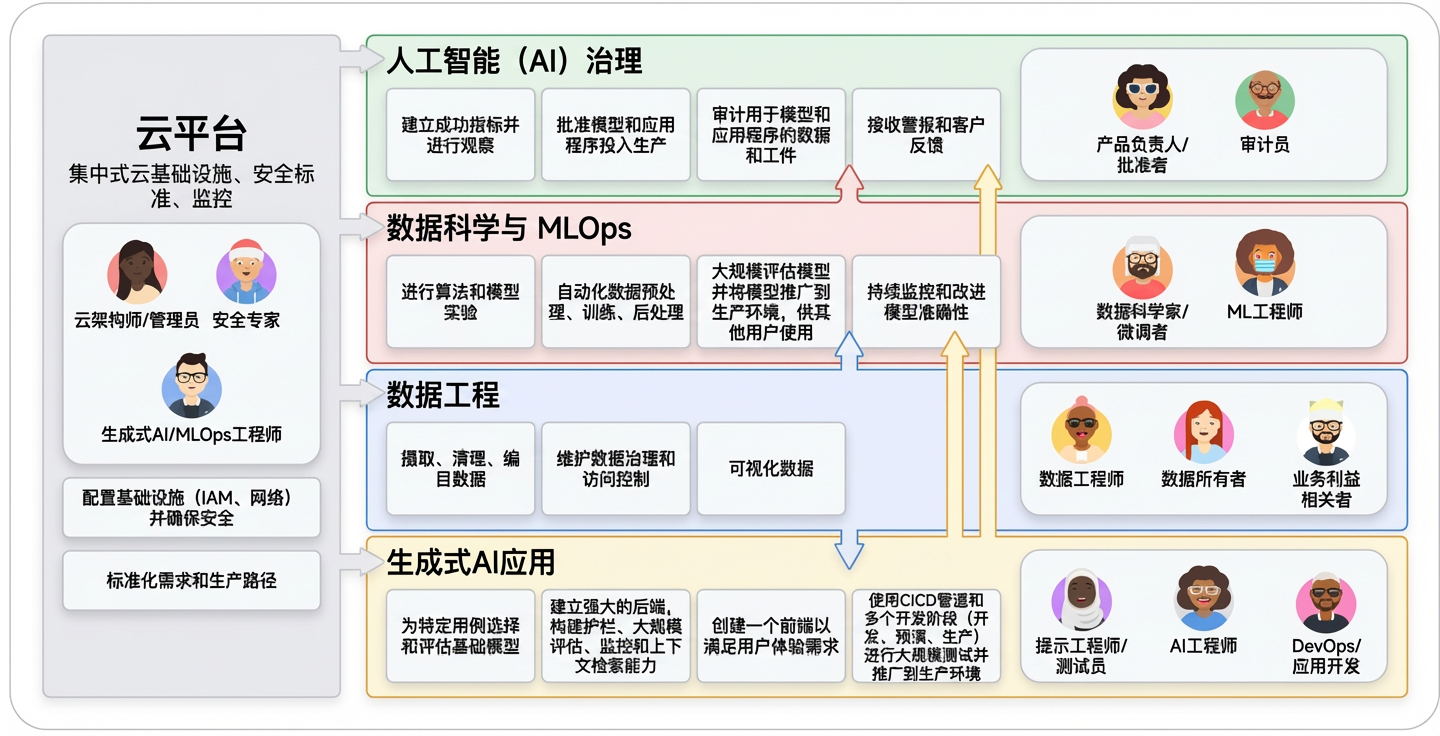
在传统的 MLOps 环境中,这涉及到几个关键团队:
- 云平台团队:由云架构师、管理员和安全专家组成,该团队负责管理基础云基础设施、安全性和访问控制。团队为工程师和服务账户授予最小权限角色,确保仅能访问必要的资源。
- 数据工程团队:数据工程师和数据所有者构建并维护数据管道,负责数据的摄入、准备和质量标准。
- 数据科学与MLOps团队:该团队包括进行模型试验和训练的数据科学家,以及利用CI/CD大规模自动化端到端机器学习管道(例如预处理、训练、后处理)的机器学习工程师。MLOps工程师通过构建和维护标准化的管道基础设施来为团队提供支持。
- 机器学习治理:这一集中式职能(包括产品负责人和审计人员)负责监督机器学习的生命周期,作为工件和指标的存储库,以确保合规性、透明度和问责制。
生成式人工智能为这一领域增添了新的复杂性层面和专门角色:
- Prompt 工程师:虽然这个职位名称在行业中仍在演变,但这类人员将编写提示词的技术技能与深厚的领域专业知识相结合。他们为模型确定合适的问题和预期答案,不过在实际中,这项工作可能由人工智能工程师、领域专家或专职专家负责,具体取决于组织的成熟度。
- AI 工程师:他们负责将生成式人工智能解决方案扩展到生产环境,构建强大的后端系统,其中包含大规模评估、防护措施以及检索增强生成/工具集成。
- DevOps/App 开发:这些开发人员构建与生成式人工智能后端集成的前端组件和用户友好型界面。
组织的规模和结构会影响这些角色;在小型公司中,个人可能身兼数职,而成熟的组织则会拥有更多专业化的团队。有效协调所有这些不同的角色,对于建立坚实的运营基础以及成功将传统机器学习和生成式人工智能项目投入生产至关重要。
1.2. 走向生产
如何将所有这些专业人员的工作转化为一个可信赖、可靠且面向用户的系统呢?答案在于一套规范化的生产前流程,该流程建立在一个核心原则之上:评估门控部署(Evaluation-Gated Deployment):任何 Agent 版本在面向用户之前,都必须先通过全面评估,以此证明其质量与安全性。在生产前阶段,我们用自动化的确定性替代了人工操作的不确定性,这一阶段主要由三大支柱构成:
- 一是作为质量关卡的严格评估流程;
- 二是保障该流程落地的自动化 CI/CD 流水线;
- 三是降低生产上线最后一步风险的安全发布策略。
1.2.1. 作为质量关卡的评估
传统的软件测试对于具有推理和适应能力的系统来说是不够的,评估 Agent 与评估 LLM 也不同:不仅需要评估最终答案,还需要评估完成任务所采取的整个推理和行动轨迹。一个 Agent 可能通过了其工具的100项单元测试,但仍可能因选择错误的工具或生成幻觉性的响应而彻底失败。我们需要评估其行为质量,而不仅仅是功能正确性。这个关卡主要可以通过两种方式实现:
- 人工 “Pre PR” 评估:在提交代码拉取请求(PR)前,由 AI 工程师、Prompt 工程师或组织中负责 Agent 行为的人员,在本地运行评估套件,生成一份 “新 Agent 与生产基准的性能对比报告”。这份报告必须作为 PR 描述的附件,成为人工审核的必备材料 —— 审核者(通常是另一位 AI 工程师或机器学习主管)不仅要检查代码本身,还要重点评估 Agent 的行为变化,比如是否存在护栏(guardrails)违规、是否能抵御提示注入漏洞,确保每一次变更都不会引发行为风险。
- 自动化流水线内关卡:将评估与 CI/CD 流水线深度绑定,用程序化规则保障一致性。由数据科学与 MLOps 团队搭建并维护 “评估工具框架”,直接集成到 CI/CD 流程中:只要评估不通过,部署流程会自动阻断,严格执行机器学习治理团队制定的质量标准。
无论选择哪种方式,核心原则始终不变:没有通过质量检查的 Agent,绝对不能进入生产环境。
1.2.2. 自动化CI/CD流水线
一个完整的 Agent 不仅包含源代码,还涵盖提示词、工具定义与配置文件。这就引发了两个关键问题:如何确保修改提示词后,工具性能不会受影响?如何在这些组件面向用户前,充分测试它们之间的交互逻辑?想要解决这些问题,搭建一套自动化 CI/CD(持续集成 / 持续部署)流水线是核心方案。它绝非简单的自动化脚本,而是能帮助团队协作管理复杂性、保障质量的结构化流程,通过分阶段测试变更,在 Agent 发布前逐步建立可靠性信心。
一个稳健的 CI/CD 流水线遵循 “漏斗式” 设计思路,核心是 “左移” 原则 —— 尽早、以最低成本捕获错误,同时将快速的合并前检查与资源密集型的合并后部署清晰分离。具体而言,这套渐进式工作流程分为三个关键阶段:
- 合并前集成(CI):主要作用是为发起拉取请求(PR)的 AI 工程师或提示工程师提供快速反馈。该阶段会自动触发,充当主分支的 “把关人”,运行单元测试、代码 lint 检查、依赖项扫描等快速验证任务。尤为关键的是,这一阶段是运行提示工程师设计的 Agent 质量评估套件的理想时机 —— 能在变更合并前,针对关键场景即时反馈变更对 Agent 性能的影响(是提升还是下降),从而避免问题污染主分支。例如,使用 Agent Starter Pack(ASP)生成的 PR 检查配置模板,就能借助 Cloud Build 实现该阶段的落地。
- 合并后预发布环境验证(CD):当变更通过所有 CI 检查(包括性能评估)并完成合并后,工作重点会从代码与性能正确性,转向集成系统的运维就绪性。通常由 MLOps 团队负责的 CD 流程,会将 Agent 打包并部署到 “预发布环境”(生产环境的高保真复制品)。在这里,会开展更全面、资源消耗更大的测试,比如负载测试、针对远程服务的集成测试;同时,这也是 “内部试用(Dogfooding)” 的关键阶段 —— 公司内部人员可提前与 Agent 交互,提供定性反馈,确保 Agent 作为集成系统,在类生产环境下能可靠、高效运行,之后才会进入发布考量环节。而 ASP 中的预发布部署模板,就能为该阶段的部署提供参考示例。
- 生产环境受控部署:在预发布环境完成全面验证后,便可推进生产部署,但这一步几乎不会完全自动化,通常需要产品负责人最终签字确认,确保 Human-in-the-Loop。获得批准后,在预发布环境中经过测试验证的部署制品,会被正式推广到生产环境。ASP 生成的生产部署模板,就演示了如何检索验证后的制品,并在完善的安全保障下完成生产部署。

要实现这一三相CI/CD工作流,需要强大的自动化基础设施和适当的密钥管理。这种自动化由两项关键技术提供支持:
- 基础设施即代码(IaC):像Terraform这样的工具通过编程方式定义环境,确保环境具有一致性、可重复性且受版本控制。例如 template generated with Agent Starter Pack 提供了完整智能体基础设施的Terraform配置,包括Vertex AI、Cloud Run和BigQuery资源。
- 自动化测试框架:像Pytest这样的框架会在每个阶段执行测试和评估,处理智能体特有的产物,如对话历史、工具调用日志和动态推理轨迹。
此外,像工具的API密钥这类敏感信息,应当使用Secret Manager之类的服务进行安全管理,并在运行时注入智能体的环境中,而不是硬编码到代码仓库里。
1.2.3. 安全部署策略
因实际应用中难免出现预生产检查未覆盖的问题,需通过 “逐步发布 + 监控” 降低风险,4 类经典策略如下:
- Canary:先面向 1% 用户上线,监控提示注入、异常工具调用,稳定后扩量,问题可即时回滚
- Blue-Green: 维护两套相同生产环境,蓝环境承流、绿环境部署新版本,切换流量实现零停机
- A/B Testing:分两组用户用新旧版本,对比业务指标(如任务完成率),数据驱动发布决策
- Feature Flags:先部署新功能代码,用开关控制生效范围,先对特定用户测试
严格版本控制 —— 代码、提示词、模型端点、评估数据集等所有组件均需版本化,相当于生产 “undo 按钮”,问题可快速回滚到稳定版本。
用 Agent Engine 或者 Cloud Run 部署 Agent,借助 Cloud Load Balancing 管理多版本流量;Agent Starter Pack 提供 GitOps 模板,部署对应 Git 提交、回滚对应 Git revert,仓库成为 “唯一真实来源”。
1.2.4. 从开始就构建安全性
安全部署策略能帮你规避漏洞与停机风险,但 AI Agent 面临一个独特挑战:它们具备自主推理与行动能力。即便 Agent 部署过程毫无问题,若构建时未采取恰当的安全与责任保障措施,仍可能造成危害。这就要求从项目启动之初,就将全面的治理策略嵌入流程,而非事后补充。
与遵循固定路径的传统软件不同,Agent 拥有决策能力:它们会解读模糊请求、调用多种工具,还能在不同会话间保留记忆。这种自主性带来了三类独特风险:
- 提示词注入与恶意行为:恶意用户可能诱导 Agent 执行非预期操作,或绕过安全限制。
- 数据泄露:Agent 可能在响应内容或工具使用过程中,无意间泄露敏感信息。
- 记忆中毒:存储在 Agent 记忆中的虚假信息,会破坏后续所有交互的准确性。
幸运的是,谷歌的 Google’s Secure AI Agents approach Google Secure
AI Framework (SAIF) 等工具,通过三层防御体系应对这些挑战:
- 政策定义与系统指令(Agent 章程)
首先明确 Agent “应做” 与 “不应做” 的行为准则,并将这些准则转化为 “系统指令(SI)”,作为 Agent 的核心行为纲领。 - 护栏、保障措施与过滤(执行层)
这一层是硬性安全屏障,具体包括:- 输入过滤:借助分类器与 Perspective API 等服务,在恶意输入触达 Agent 前对其分析并拦截。
- 输出过滤:Agent 生成响应后,Vertex AI 内置安全过滤器 ¹⁴会进行最终检查,排查有害内容、个人身份信息(PII)或违规内容,还可配置拦截含特定 PII、有毒语言等内容的输出。
- 人工介入(HITL)升级:若 Agent 需执行高风险操作或面对模糊请求,系统会暂停流程,将问题升级至人工审核,待确认后再推进。
- 持续保障与测试
安全并非一次性设置,需持续评估与调整,关键措施包括:- 严格评估:模型或其安全系统若有任何变更,必须通过 Vertex AI Evaluation,重新运行完整的综合评估流程。
- 专项负责任 AI(RAI)测试:通过创建专项数据集或使用模拟 Agent,针对特定风险开展严格测试,包括中立视角(NPOV)评估与公平性(Parity)评估。
- 主动红队测试:通过创新性人工测试与 AI 驱动的角色模拟,主动尝试突破安全系统,提前发现漏洞。
1.3. 生产中的运营
你的 Agent 已上线。现在重点从开发转向了一个截然不同的挑战:在它与数千用户交互时,确保系统可靠、经济且安全。传统服务按照可预测的逻辑运行。相比之下,Agent 是自主的行动者。它能够遵循意想不到的推理路径,这意味着它可能会表现出突发行为,并且在没有直接监督的情况下累积成本。
管理这种自主性需要一种不同的运营模式。高效的团队不再采用静态监控,而是采用一个持续循环:实时观察系统行为,采取行动以维持性能和安全性,并根据生产经验改进智能体。这个集成循环是在生产环境中成功运营 Agent 的核心原则。
1.3.1. 观察:Agent 的感知系统
要信任并管理一个自主 Agent,你首先必须了解它的运行过程。可观测性提供了这种关键的洞察力,充当了后续“行动”和“进化”阶段的感知系统。一套完善的可观测性实践建立在三大支柱之上,这些支柱协同工作,以全面呈现智能体的行为。
- Logs:详细、真实记录所发生情况的日记,记录每一次工具调用、错误和决策。
- Traces:连接各个日志的叙述,揭示智能体采取特定行动的因果路径。
- Metrics:汇总的成绩单,总结大规模情况下的性能、成本和运营健康状况,以展示系统的运行情况。
通过实施这些支柱,我们从盲目操作转变为对智能体的行为拥有清晰、数据驱动的认知,这为在生产环境中有效管理智能体奠定了必要的基础。
1.3.2. 行动:操作控制的杠杆
在 AI Agent 从原型落地生产的全流程中,“观察(Observe)” 是获取数据的基础,而 “执行(Act)” 才是将数据转化为系统稳定性的关键。“执行(Act)” 阶段的核心是构建系统的自动化 “反应机制”,实时维护 Agent 在生产环境中的稳定;这与后续将提及的 “进化(Evolve)” 阶段形成鲜明对比 —— 后者是通过学习行为、优化系统的战略性过程,而 “执行” 更侧重即时干预。
由于 Agent 具备自主决策能力,无法预先为所有可能结果编写程序,因此必须建立强有力的机制来引导其生产环境中的行为。这些操作手段主要分为两大核心方向:管理系统健康(覆盖性能、成本与规模)与管理安全风险。
1.3.2.1. 管理系统健康
不同于传统微服务,Agent 的工作负载兼具动态性与状态性,想要保障其稳定运行,需从架构设计到目标平衡层层布局:
- 规模化设计核心:解耦逻辑与状态
这是 Agent 实现规模化的基础前提,只有将业务逻辑与运行状态分离,才能为后续扩展扫清架构障碍。- 水平扩展:无状态容器化 + 自动扩缩容
将 Agent 设计为无状态的容器化服务,借助外部状态存储,让任意实例都能处理任意请求。这种架构可适配 Cloud Run、托管版 Vertex AI Agent Engine Runtime 等无服务器平台,实现流量波动时的自动扩缩容。 - 异步处理:保障长任务响应性
针对数据分析等长时间运行的任务,采用事件驱动模式分流。例如在谷歌云平台中,可将任务发布到 Pub/Sub,再触发 Cloud Run 服务进行异步处理,既不影响 Agent 对用户请求的实时响应,又能高效完成后台复杂工作。 - 外部化状态管理:LLM 无状态的必然选择
由于大语言模型(LLM)本身无状态,Agent 的记忆必须通过外部存储持久化。此时有两种架构选择:一是直接使用 Vertex AI Agent Engine 内置的持久化会话与记忆服务,快速落地;二是通过 Cloud Run 灵活集成 AlloyDB、Cloud SQL 等数据库,适配自定义需求。
- 水平扩展:无状态容器化 + 自动扩缩容
- 平衡三大目标:速度、可靠性与成本的 “三角博弈”
规模化过程中,速度(延迟)、可靠性(故障处理)与成本常相互制约,需通过精细化设计找到平衡点:- 速度优化:通过并行处理减少等待时间,对高频请求结果 “积极缓存”,日常简单任务使用更小、更高效的模型,降低响应延迟;
- 可靠性保障:面对工具调用失败等临时故障,配置自动重试机制(优先采用指数退避策略,为服务恢复留足时间),同时设计 “可安全重试(幂等)” 的工具,避免重复收费等漏洞;
- 成本控制:缩短提示词减少 token 消耗,简单任务用低成本模型替代高算力模型,将多个请求 “批量发送”,从细节处压缩运行成本。
1.3.2.1. 管理安全风险
Agent 的自主性也带来了安全隐患,因此必须制定标准化的 “安全响应手册(Playbook)”,在威胁出现时按 “遏制 - 分类处置 - 解决” 的清晰流程快速应对:
- 即时遏制,优先止损
发现威胁后,首要目标是阻止伤害扩散。最常用的手段是 “断路器”—— 通过功能标志(Feature Flag)立即禁用受影响的工具,避免风险扩大。 - 分类处置,明确影响范围
威胁得到遏制后,将可疑请求路由至 “人工介入(HITL)” 审核队列,由工作人员排查漏洞的利用范围与实际影响,为后续修复提供依据。 - 彻底解决,闭环安全漏洞
团队针对漏洞开发修复方案(如更新输入过滤器、优化系统提示),并通过自动化 CI/CD 流水线部署。确保修复经过全面测试后,再彻底阻断该漏洞,避免问题复发。
1.3.3. 进化:从生产环境中学习
在 AI Agent 的生产运维全流程中,“执行(Act)” 阶段负责即时的战术性响应,而 “进化(Evolve)” 阶段则聚焦长期的战略性改进 —— 它以 “观察(Observe)” 阶段收集的行为模式与趋势数据为起点,核心是解决一个关键问题:“如何从根源上修复问题,让它不再发生?”
这一阶段标志着运维思路的转变:从被动应对生产事故,转向主动提升 Agent 的智能度、效率与安全性。通过将 “观察” 阶段的原始数据,转化为 Agent 架构、逻辑与行为层面的持久优化,真正实现 Agent 的持续成长。
1.3.3.1. 进化的核心引擎:自动化 CI/CD 流水线
生产环境中的洞见,只有快速落地才能体现价值。比如发现 30% 用户在某任务中失败,若团队需 6 个月才能部署修复,这份洞见便毫无意义。而预生产阶段搭建的自动化 CI/CD 流水线,正是推动 Agent 快速演进的核心引擎 —— 它能将 “观察 - 改进” 的循环周期从数周、数月压缩至数小时、数天,成为运营闭环中最关键的组件。
当识别到潜在改进点(无论是优化提示词、新增工具,还是更新安全护栏),需遵循标准化自动化流程落地:
- 提交变更:将改进方案提交至版本控制仓库,确保所有修改可追溯;
- 触发自动化:提交操作自动触发 CI/CD 流水线,无需人工干预;
- 严格验证:流水线针对更新后的数据集,运行全套单元测试、安全扫描与 Agent 质量评估套件,确保改进不引入新问题;
- 安全部署:验证通过后,通过金丝雀发布等安全策略将变更部署到生产环境。
这套流程彻底改变了传统演进模式 —— 将缓慢、高风险的手动操作,转化为快速、可重复、数据驱动的标准化过程。
1.3.3.2. 演进工作流:从洞见到落地的三步闭环
- 分析生产数据:从生产日志中挖掘用户行为趋势、任务成功率、安全事件等关键信息,定位待改进方向;
- 更新评估数据集:将生产环境中出现的失败案例,转化为新的测试用例,补充到 “黄金数据集” 中 —— 让过去的问题成为未来的防护盾;
- 优化与部署:提交改进方案(如优化提示词、新增工具、更新护栏),触发自动化流水线,完成从开发到生产的落地。
通过这一闭环,Agent 能在每一次用户交互中积累经验,实现持续自我完善。
1.3.4. 不断发展的安全性:生产反馈循环
安全不是一份静态的清单,而是一个动态、持续的适应过程。生产环境是最终的测试场,在那里收集的见解对于强化智能体抵御现实世界的威胁至关重要。
而实现安全动态升级的关键,正是 “观察→行动→演进(Observe→Act→Evolve)” 的闭环机制,这一机制是 Agent 整体进化工作流在安全领域的直接延伸,具体落地分为三步:
- 观察(Observe):依托监控与日志系统,实时捕捉新的威胁向量。比如发现能绕过现有过滤器的新型提示注入技术,或是因意外交互导致轻微数据泄露的异常情况,这些都需要通过观测体系及时察觉。
- 行动(Act):一旦发现威胁,即时安全响应团队需按照既定流程快速遏制风险,避免威胁扩散,为后续彻底修复争取时间。
- 演进(Evolve):这是构建 Agent 长期安全韧性的核心环节,需将安全洞察深度融入开发生命周期:
- 把新发现的威胁(如新型提示注入攻击)转化为永久测试用例,补充到评估套件中,让后续版本不再重蹈覆辙;
- 由提示工程师或 AI 工程师优化 Agent 的系统提示、输入过滤器或工具使用政策,从技术层面阻断新攻击向量;
- 工程师提交这些安全改进,触发完整 CI/CD 流水线,经过新扩展评估集的严格验证后,将更新后的 Agent 部署到生产环境,彻底修复漏洞。
这形成了一个强大的反馈循环,每一次生产事件都会让你的智能体更强大、更具韧性,将你的安全态势从防御姿态转变为持续、主动的改进。
要了解更多关于负责任的人工智能以及保障人工智能智能体系统安全的信息,请参考白皮书《谷歌的安全人工智能智能体方法》
1.4. A2A - 可复用性和标准化
你在整个组织内构建了数十个专门的 Agents,但问题在于:这些 Agents 无法互通,形成 “信息孤岛”。——无论是因为它们是在不同的框架、项目中创建的,还是完全在不同的云端创建的。
要解决此问题,需依托两套互补的标准化协议实现 Agents 互操作性:
- MCP 协议:适用于无状态的简单功能调用,如获取天气数据、查询数据库,核心是执行 “具体指令”;
- A2A 协议:针对 Agents 间复杂、有状态的协作场景,如 “分析上季度客户流失并提出 3 个干预方案”,支持代理自主推理、规划与行动,核心是达成 “复杂目标”。
1.4.1. A2A协议:从概念到实现
A2A协议 旨在打破组织壁垒,实现 Agents 之间的无缝协作。
合作的第一步是找到合适的 Agent 进行委托——这通过 Agent Cards 得以实现,Agent Cards 是标准化的JSON规范,相当于每个 Agent 的名片。它会描述智能体的功能、安全要求、技能以及联系方式(url),使生态系统中的任何其他 Agents 都能动态发现它。以下是 Agent Card 的示例:
"name": "check_prime_agent",
"version": "1.0.0",
"description": "一款专门用于判断数字是否为质数的代理",
"capabilities": {},
"securitySchemes": {
"agent_oauth_2_0": {
"type": "oauth2"
}
},
"defaultInputModes": ["text/plain"],
"defaultOutputModes": ["application/json"],
"skills": [
{
"id": "prime_checking",
"name": "质数判断",
"description": "使用高效算法判断数字是否为质数",
"tags": ["mathematical", "computation", "prime"]
}
],
"url": "http://localhost:8001/a2a/check_prime_agent"
}
使用 Goolge ADK的 to_a2a 工具包装现有 Agent 并将其暴露以进行 A2A 通信:
# 示例:使用ADK通过A2A协议暴露代理
from google.adk.a2a.utils.agent_to_a2a import to_a2a
# 你的现有代理(此处为示例代理,实际需替换为你的业务代理)
root_agent = Agent(
name='hello_world_agent', # 代理名称:"hello_world_agent"
)
# 将现有代理改造为A2A协议兼容版本
# 参数说明:root_agent为待改造的现有代理,port=8001为A2A协议通信端口
a2a_app = to_a2a(root_agent, port=8001)
# 方式1:使用uvicorn服务启动A2A兼容代理(uvicorn为Python常用ASGI服务器)
# 启动命令:uvicorn agent:a2a_app --host localhost --port 8001
# 方式2:使用Agent Engine(Vertex AI提供的托管代理引擎)启动
# from vertexai.preview.reasoning_engines import A2aAgent
# from google.adk.a2a.executor.a2a_agent_executor import A2aAgentExecutor
# a2a_agent = A2aAgent(
# agent_executor_builder=lambda: A2aAgentExecutor(agent=root_agent)
# )
一旦某个智能体被公开,其他任何 Agents 都可以通过引用其 Agent Card 来使用它。例如,客服智能体现在可以查询远程的产品目录智能体,而无需了解其内部运作方式,使用 ADK 的RemoteA2aAgent 类连接并使用远程 Agent:
# Example using ADK: Consuming a remote agent via A2A
from google.adk.agents.remote_a2a_agent import RemoteA2aAgent
prime_agent = RemoteA2aAgent(
name="prime_agent",
description="Agent that handles checking if numbers are prime.", agent_card="http://localhost:8001/a2a/check_prime_agent/ .well-known/agent-card.json"
)
在ADK Python的分层智能体结构中,将远程A2A智能体(prime_agent)用作sub-agent:
# Example using ADK: Hierarchical agent composition
# ADK Local sub-agent for dice rolling
roll_agent = Agent(
name="roll_agent",
instruction="You are an expert at rolling dice."
)
# ADK Remote A2A agent for prime checking
prime_agent = RemoteA2aAgent(
name="prime_agent",
agent_card="http://localhost:8001/.well-known/agent-card.json"
)
# ADK Root orchestrator combining both
root_agent = Agent(
name="root_agent",
instruction="""Delegate rolling dice to roll_agent, prime checking
to prime_agent.""",
sub_agents=[roll_agent, prime_agent]
)
实现 AI 代理自主协作需两项核心技术:一是分布式追踪(含唯一追踪 ID,用于跨代理调试与审计),二是强大状态管理(靠持久层保障交互进度与事务完整保存)。
协议选择建议:跨团队正式集成用 A2A,单应用内紧耦合任务用轻量本地 sub-agents;新构建的 Agent 应原生支持这两种协议,确保每个新组件都能立即被发现、互操作和重用,从而增加整个系统的价值。
1.4.2. A2A 与 MCP 如何协同工作
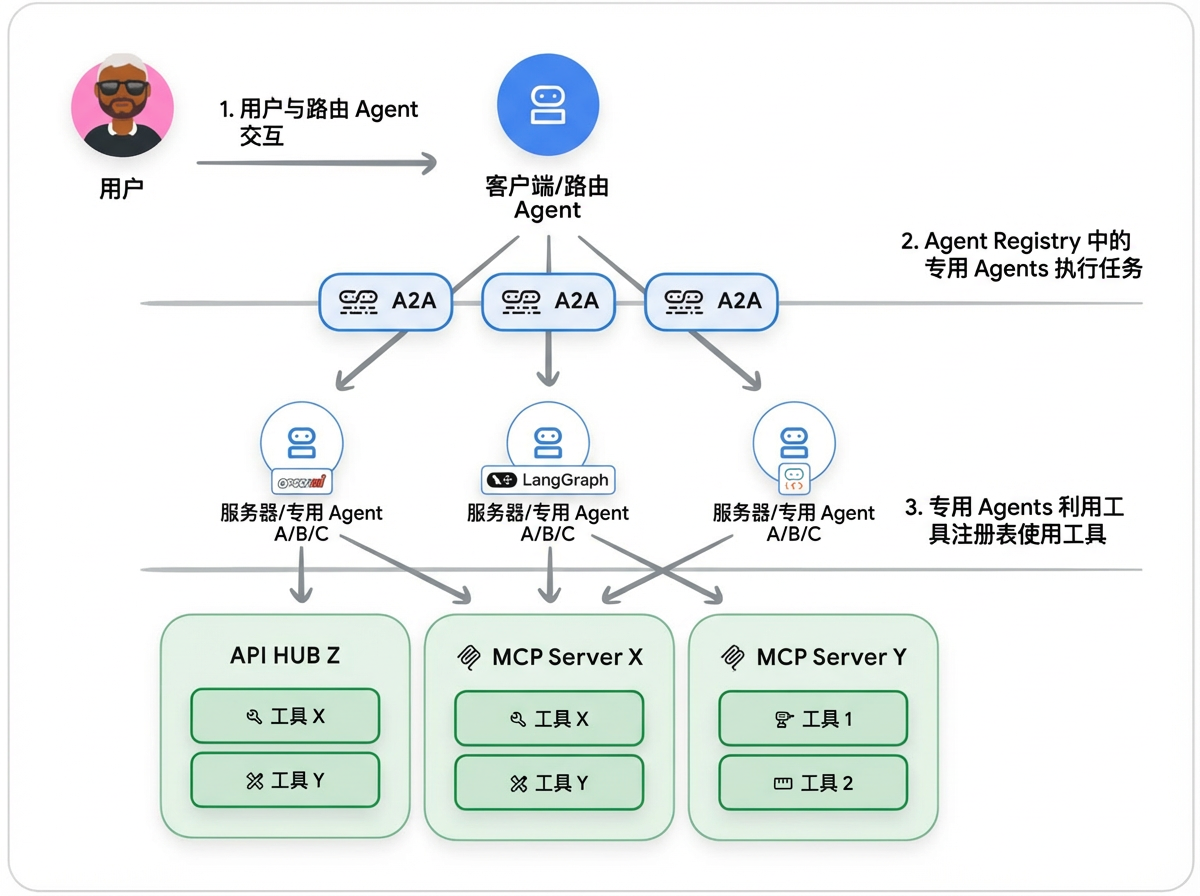
A2A 与 MCP 并非竞争关系,而是适配不同抽象层级的互补协议,核心区别在于 AI Agent的交互对象。
- MCP 聚焦工具与资源交互
- A2A 则面向 Agent 间协作,服务于能推理、规划、多工具调用且需维持状态以实现复杂目标的自主 Agents。
一个实用的类比是一家由 AI agents 组成的汽车修理店:
- User-to-Agent:客户与“商店经理” Agent 沟通,描述一个大致问题:“我的车发出咯咯声。”
- Agent-to-Agent:商店经理进行多轮诊断对话,然后再次使用 A2A 将任务委派给专门的“机械师” Agent。
- Agent-to-Tool :机械师 Agent 现在需要执行特定操作。它使用MCP调用其专用工具:在诊断扫描仪上运行
scan_vehicle_for_error_codes(),通过get_repair_procedure()查询维修手册数据库,以及使用raise_platform()操作平台升降机。 - Agent-to-Agent:在诊断问题后,机械师 Agent 确定需要某个零件。它使用A2A与外部的“零件供应商” Agent 进行通信,以查询可用性并下订单。
在这个工作流程中,A2A促进了客户、店铺 Agents 和外部供应商之间更高层次、对话式且面向任务的交互。同时,MCP提供了标准化的基础架构,使机械 Agent 能够可靠地使用其特定的结构化工具来完成工作。
1.4.3. 注册中心架构:何时以及如何构建它们
当 tools 数量较少时(50),手动管理尚能应对;可一旦规模突破阈值(5000 个且跨多团队),你就需要一个系统性的解决方案去发现他们并调用。
Tool Registry 使用类似 MCP 的协议来编目所有资产,从函数到API。你无需让 Agents 访问数千种 tools ,而是创建精选列表,这会形成三种常见模式:
- 通用 Agents:可访问完整目录,以速度和准确性换取范围。
- 专业 Agents:使用预定义的子集以获得更高性能。
- 动态 Agents:在运行时查询注册表以适应新工具。
Agent Registry 将相同的概念应用于 agents,采用 A2A 的 AgentCards 等格式。它有助于团队发现和重用现有的 agents,减少重复工作。这也为 agents 之间的自动委托奠定了基础,尽管这仍是一种新兴模式。
1.5. 整合:Agent 运维生命周期
现在我们可以将这些支柱整合为一个单一、连贯的架构。生命周期始于开发者的内循环——这是一个快速进行本地测试和原型设计以塑造智能体核心逻辑的阶段。一旦一项变更准备就绪,它就会进入正式的预生产引擎,在那里,自动化评估关卡会根据黄金数据集验证其质量和安全性。之后,安全部署会将其发布到生产环境,在那里,全面的可观测性会捕获推动持续进化循环所需的真实世界数据,将每一个洞见转化为下一次改进。
要全面了解 AI agents 的实际应用操作,包括评估、工具管理、CI/CD标准化和有效的架构设计,请观看:AgentOps: Operationalize AI Agents video
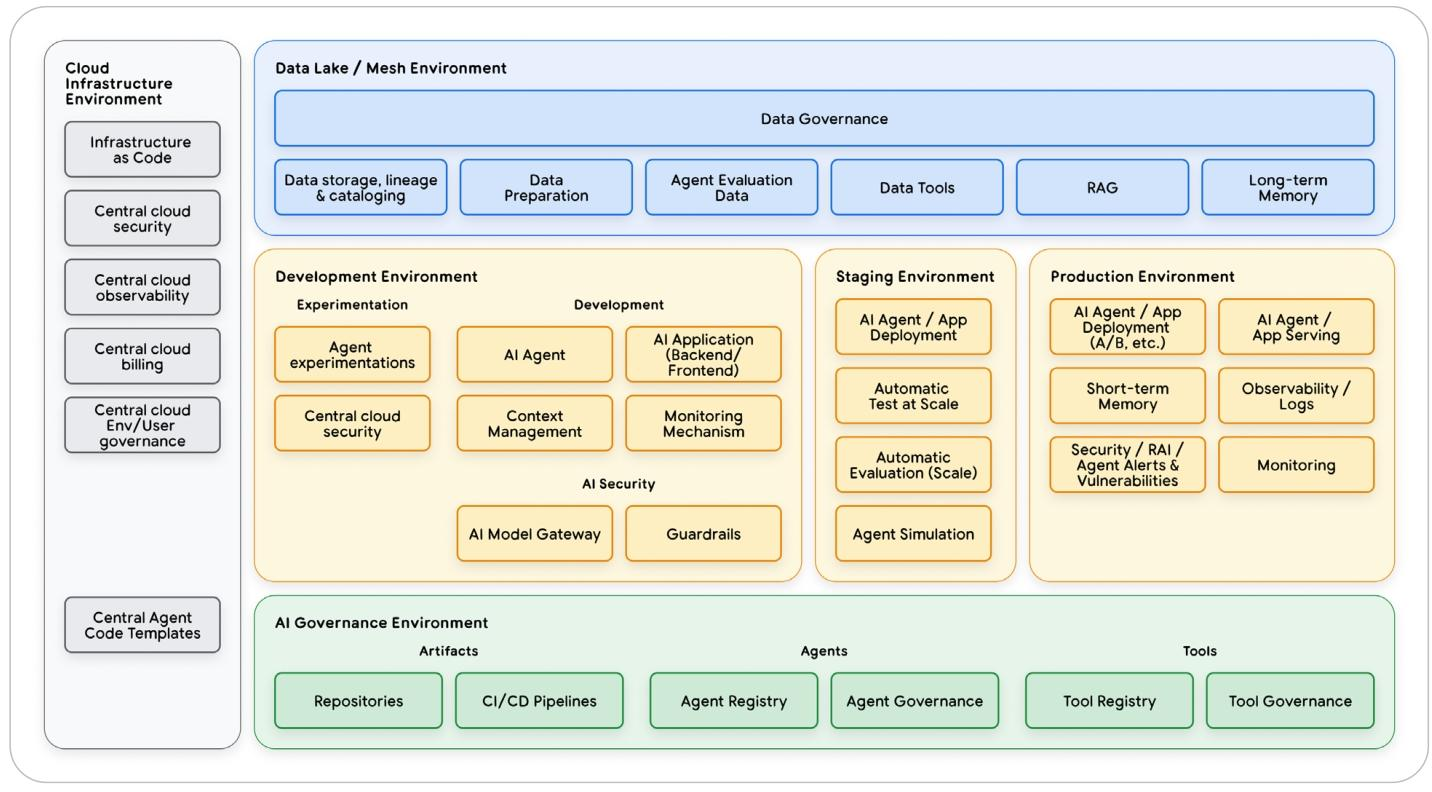
1.6. 总结:用 AgentOps 跨越 AI 原型到生产的"最后一公里"
将 AI 原型落地为生产系统,本质是一场需要新运营规范 ——AgentOps 支撑的组织变革。多数 AI 智能体项目折戟 “最后一公里”,根源并非技术不足,而是自主系统的运营复杂性被低估。
要弥合这一差距,需遵循清晰路径:先以 “人员与流程” 筑牢治理根基;再靠 “评估控制部署” 的预生产策略,实现高风险发布自动化;上线后,通过 “观察→行动→进化” 循环,把每次用户交互转化为优化洞见以备后续优化;最后借互操作性协议,将孤立智能体打造成协作生态,完成系统规模化。
至于落地路径,可分阶段推进:
- 起步阶段聚焦基础,搭建首份评估数据集、部署 CI/CD 流水线、建立全面监控,借助 “智能体入门包” 能快速启动(几分钟即可生成含基础功能的生产级项目);
- 规模化阶段则需升级,一方面自动化 “生产洞察→部署改进” 的反馈循环,另一方面以互操作性协议为标准,构建生态而非零散的点解决方案。
未来,AI 发展的核心不仅是打造更优的单个智能体,更是构建能学习、会协作的复杂多智能体系统 —— 而 AgentOps 正是实现这一目标的关键基石。跨越 “最后一公里”,从来不是项目的终点,而是创造 AI 价值的起点。
2. 代码实验室
2.1. Agent2Agent
A2A协议在三种场景中特别有用:
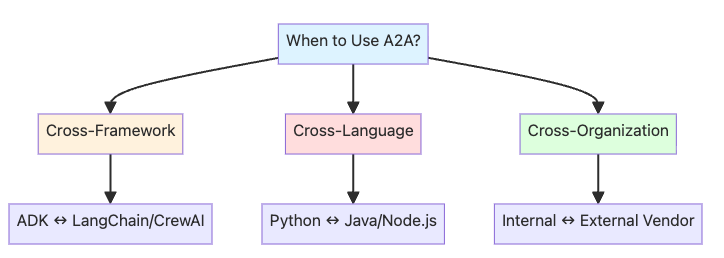
- 跨框架集成:ADK智能体与其他智能体框架通信
- 跨语言通信:Python智能体调用Java或Node.js智能体
- 跨组织边界:你的内部智能体与外部供应商服务集成
我们将构建一个电子商务系统:
1. Product Catalog Agent :提供产品信息的外部供应商服务
2. Customer Support Agent :你的内部智能体,通过查询产品数据为客户提供帮助
┌──────────────────────┐ ┌──────────────────────┐
│ Customer Support │ ─A2A──▶ │ Product Catalog │
│ Agent (Consumer) │ │ Agent (Vendor) │
│ Your Company │ │ External Service │
│ (localhost:8000) │ │ (localhost:8001) │
└──────────────────────┘ └──────────────────────┘
系统架构如下:
参考: A2A in LangGraph 我们用 LangGraph 复刻这个case:
Product Catalog Agent
#!/usr/bin/env python3
"""
LangGraph A2A - Product Catalog Agent (Server)
这是一个产品目录代理,通过A2A协议暴露服务。
对应Google ADK示例中的Product Catalog Agent。
技术要点:
1. 使用 messages key 的状态结构来兼容A2A协议
2. 定义product lookup工具
3. 通过 langgraph dev 或部署到生产环境来暴露A2A端点
"""
from __future__ import annotations
from pathlib import Path
from typing import Any, Dict, List, TypedDict, Annotated
import yaml
from langgraph.graph import StateGraph
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI
from langchain_core.messages import AIMessage, SystemMessage, BaseMessage
from langchain_core.tools import tool as tool_decorator
from langgraph.prebuilt import ToolNode
def get_product_info(product_name: str) -> str:
"""获取产品信息
Args:
product_name: 产品名称(例如:"iPhone 15 Pro", "MacBook Pro")
Returns:
产品信息字符串
"""
# 模拟产品数据库 - 生产环境中应该查询真实数据库
product_catalog = {
"iphone 15 pro": "iPhone 15 Pro, $999, 库存不足 (8 units), 128GB, 钛金色",
"samsung galaxy s24": "Samsung Galaxy S24, $799, 有货 (31 units), 256GB, 幻影黑",
"dell xps 15": 'Dell XPS 15, $1,299, 有货 (45 units), 15.6" 显示屏, 16GB RAM, 512GB SSD',
"macbook pro 14": 'MacBook Pro 14", $1,999, 有货 (22 units), M3 Pro 芯片, 18GB RAM, 512GB SSD',
"sony wh-1000xm5": "Sony WH-1000XM5 耳机, $399, 有货 (67 units), 降噪, 30小时续航",
"ipad air": 'iPad Air, $599, 有货 (28 units), 10.9" 显示屏, 64GB',
"lg ultrawide 34": 'LG UltraWide 34" 显示器, $499, 缺货, 预计: 下周到货',
}
product_lower = product_name.lower().strip()
if product_lower in product_catalog:
return f"产品: {product_catalog[product_lower]}"
else:
available = ", ".join([p.title() for p in product_catalog.keys()])
return f"抱歉,没有 {product_name} 的信息。可用产品: {available}"
class State(TypedDict):
"""Product Catalog Agent的状态结构
重要:A2A协议要求状态中必须包含 messages 字段
使用 Annotated 和 add_messages 来正确处理消息列表
"""
messages: Annotated[List[BaseMessage], add_messages]
@tool_decorator
def product_lookup(product_name: str) -> str:
"""查询产品信息
Args:
product_name: 产品名称
"""
return get_product_info(product_name)
def call_model(state: State) -> Dict[str, Any]:
"""处理消息并使用LLM生成响应
这个节点会:
1. 读取最新的用户消息
2. 调用LLM(配置了产品查询工具)
3. 返回响应消息
"""
# 初始化OpenAI客户端
config_path = Path(__file__).parent.parent.parent / "config.yaml"
with open(config_path, 'r', encoding='utf-8') as f:
config = yaml.safe_load(f)
# 初始化模型(从配置文件读取模型配置)
llm = ChatOpenAI(
model=config['model'],
api_key=config['api_key'],
base_url=config['base_url'],
temperature=config['temperature']
)
# 绑定工具到LLM
tools = [product_lookup]
llm_with_tools = llm.bind_tools(tools)
# 构建消息列表
system_message = SystemMessage(content="""你是一个产品目录专家,来自外部供应商。
当用户询问产品时,使用 product_lookup 工具从目录中获取数据。
提供清晰、准确的产品信息,包括价格、库存和规格。
如果询问多个产品,逐个查询。
保持专业和友好。""")
# state.messages 已经是 BaseMessage 对象列表,直接使用
messages = [system_message] + list(state["messages"])
# 调用LLM
response = llm_with_tools.invoke(messages)
# 检查是否需要调用工具
if response.tool_calls:
# 添加AI响应到消息列表
messages.append(response)
# 使用 ToolNode 来处理工具调用
# ToolNode 会正确处理 Claude/Bedrock 的特殊格式要求
tool_node = ToolNode([product_lookup])
# 调用工具节点
tool_result = tool_node.invoke({"messages": messages})
# 将工具结果添加到消息列表
messages.extend(tool_result["messages"])
# 再次调用LLM生成最终响应
final_response = llm.invoke(messages)
ai_content = final_response.content
else:
ai_content = response.content
# 创建响应消息 (AIMessage 对象)
response_message = AIMessage(content=ai_content)
return {
"messages": [response_message] # add_messages 会自动追加
}
def create_product_catalog_graph():
"""创建产品目录代理图
START → call_model → END
"""
workflow = StateGraph(State)
workflow.add_node("call_model", call_model)
workflow.add_edge("__start__", "call_model")
graph = workflow.compile()
return graph
graph = create_product_catalog_graph()
Customer Support Agent
#!/usr/bin/env python3
"""
LangGraph A2A - Customer Support Agent (Consumer)
这是一个客户支持代理,通过A2A协议消费Product Catalog Agent的服务。
对应Google ADK示例中的Customer Support Agent。
技术要点:
1. 使用 messages key 的状态结构来兼容A2A协议
2. 通过HTTP调用远程A2A端点来获取产品信息
3. 实现与远程代理的通信逻辑
"""
from __future__ import annotations
import asyncio
import json
import uuid
from pathlib import Path
from typing import Any, Dict, List, TypedDict, Annotated
import aiohttp
import yaml
from langgraph.graph import StateGraph
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI
from langchain_core.messages import AIMessage, SystemMessage, BaseMessage
class State(TypedDict):
"""Customer Support Agent的状态结构"""
messages: Annotated[List[BaseMessage], add_messages]
async def call_product_catalog_agent(message: str, product_catalog_url: str) -> str:
"""通过A2A协议调用远程Product Catalog Agent
Args:
message: 要发送给产品目录代理的消息
product_catalog_url: 产品目录代理的A2A端点URL
Returns:
远程代理的响应内容
"""
# 构建A2A协议消息
payload = {
"jsonrpc": "2.0",
"id": str(uuid.uuid4()),
"method": "message/send",
"params": {
"message": {
"role": "user",
"parts": [{"kind": "text", "text": message}]
},
"messageId": str(uuid.uuid4()),
"thread": {"threadId": str(uuid.uuid4())}
}
}
headers = {"Accept": "application/json", "Content-Type": "application/json"}
async with aiohttp.ClientSession() as session:
async with session.post(
product_catalog_url,
json=payload,
headers=headers,
timeout=aiohttp.ClientTimeout(total=30)
) as response:
response.raise_for_status()
result = await response.json()
# 从A2A响应中提取文本
artifacts = result.get("result", {}).get("artifacts", [])
if artifacts and artifacts[0].get("parts"):
return artifacts[0]["parts"][0].get("text", "无响应内容")
return "无法解析响应"
def call_model(state: State) -> Dict[str, Any]:
"""处理客户消息并生成响应
这个节点会:
1. 读取用户消息
2. 判断是否需要查询产品信息
3. 如果需要,调用远程Product Catalog Agent(通过A2A)
4. 生成最终响应
"""
# 初始化OpenAI客户端
config_path = Path(__file__).parent.parent.parent / "config.yaml"
with open(config_path, 'r', encoding='utf-8') as f:
config = yaml.safe_load(f)
# 初始化模型(从配置文件读取模型配置)
llm = ChatOpenAI(
model=config['model'],
api_key=config['api_key'],
base_url=config['base_url'],
temperature=config['temperature']
)
# 先不构建 messages,等获取产品信息后再构建
system_prompt = """你是一个友好且专业的客户支持代理。
当客户询问产品时:
1. 判断客户是否在询问产品信息
2. 如果是,你需要调用远程产品目录服务获取信息
3. 提供清晰的答案,包括价格、库存和规格
4. 如果产品缺货,提及预计到货时间
5. 保持友好和专业!
注意:你无法直接查询产品信息,需要告诉用户你将查询产品目录系统。"""
# 获取最新的用户消息
latest_message = state["messages"][-1]
user_content = latest_message.content
assistant_config_path = Path(__file__).parent / "assistant_config.json"
with open(assistant_config_path, 'r') as f:
assistant_config = json.load(f)
product_catalog_url = assistant_config["product_catalog"]["a2a_endpoint"]
# 在同步函数中运行异步调用
try:
loop = asyncio.get_event_loop()
except RuntimeError:
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
print(f"XXXXA:{user_content}")
product_info = loop.run_until_complete(
call_product_catalog_agent(user_content, product_catalog_url)
)
print(f"XXXXB:{product_info}")
system_prompt = f"""{system_prompt}
产品目录系统返回的信息:
{product_info}
请根据这些产品信息回答客户的问题。"""
messages = [SystemMessage(content=system_prompt)] + list(state["messages"])
response = llm.invoke(messages)
return {"messages": [response]}
def create_customer_support_graph():
"""创建客户支持代理图
START → call_model → END
"""
workflow = StateGraph(State)
workflow.add_node("call_model", call_model)
workflow.add_edge("__start__", "call_model")
graph = workflow.compile()
return graph
# 导出图实例 - 供 langgraph.json 使用
graph = create_customer_support_graph()
langgraph.json
这个文件定义了 LangGraph 项目的配置,包括 graphs 和 assistants:
{
"$schema": "https://langgra.ph/schema.json",
"dependencies": ["."],
"graphs": {
"product_catalog_agent": "./a2a_product_catalog_agent.py:graph",
"customer_support_agent": "./a2a_customer_support_agent.py:graph"
},
"env": ".env",
"assistants": {
"product_catalog": {
"graph": "product_catalog_agent",
"name": "Product Catalog Agent",
"description": "产品目录代理,提供产品信息查询服务",
"config": {
"configurable": {}
}
},
"customer_support": {
"graph": "customer_support_agent",
"name": "Customer Support Agent",
"description": "客户支持代理,通过A2A调用产品目录服务",
"config": {
"configurable": {}
}
}
}
}
setup_assistants.py
这个脚本用于在 LangGraph 服务器上创建 assistant 实例,并保存到 assistant_config.json 文件中:
#!/usr/bin/env python3
"""
初始化 LangGraph Assistants
这个脚本会:
1. 在两个 LangGraph 服务器上创建 assistants
2. 保存 assistant UUIDs 到配置文件
3. 更新测试脚本使用正确的 UUIDs
"""
import requests
import json
from pathlib import Path
def create_assistant(base_url: str, graph_id: str, name: str) -> dict:
"""创建一个 assistant"""
url = f"{base_url}/assistants"
payload = {
"graph_id": graph_id,
"config": {"configurable": {}},
"metadata": {"description": f"{name} for A2A communication"},
"name": name
}
response = requests.post(url, json=payload)
if response.status_code == 200:
return response.json()
else:
print(f"❌ 创建 assistant 失败: {response.status_code}")
print(response.text)
return None
def main():
# 服务器配置
servers = {
"product_catalog": {
"url": "http://localhost:2024",
"graph_id": "product_catalog_agent",
"name": "Product Catalog Agent"
},
"customer_support": {
"url": "http://localhost:2025",
"graph_id": "customer_support_agent",
"name": "Customer Support Agent"
}
}
assistant_ids = {}
# 创建 assistants
for key, config in servers.items():
print(f"\n📝 创建 {config['name']}...")
print(f"服务: {config['url']}")
print(f"Graph ID: {config['graph_id']}")
assistant = create_assistant(
config['url'],
config['graph_id'],
config['name']
)
if assistant:
assistant_id = assistant['assistant_id']
assistant_ids[key] = {
"assistant_id": assistant_id,
"url": config['url'],
"a2a_endpoint": f"{config['url']}/a2a/{assistant_id}",
"agent_card": f"{config['url']}/.well-known/agent-card.json?assistant_id={assistant_id}"
}
print(f"Assistant ID: {assistant_id}")
print(f"A2A 端点: {assistant_ids[key]['a2a_endpoint']}")
else:
print(f" ❌ 失败")
return
# 保存配置
config_file = Path(__file__).parent / "assistant_config.json"
with open(config_file, 'w') as f:
json.dump(assistant_ids, f, indent=2)
if __name__ == "__main__":
main()
assistant_config.json
{
"product_catalog": {
"assistant_id": "459d773b-d85f-420e-bd28-c83ec8d00999",
"url": "http://localhost:2024",
"a2a_endpoint": "http://localhost:2024/a2a/459d773b-d85f-420e-bd28-c83ec8d00999",
"agent_card": "http://localhost:2024/.well-known/agent-card.json?assistant_id=459d773b-d85f-420e-bd28-c83ec8d00999"
},
"customer_support": {
"assistant_id": "447d850c-1b7b-4a6f-a87b-c2284c44488e",
"url": "http://localhost:2025",
"a2a_endpoint": "http://localhost:2025/a2a/447d850c-1b7b-4a6f-a87b-c2284c44488e",
"agent_card": "http://localhost:2025/.well-known/agent-card.json?assistant_id=447d850c-1b7b-4a6f-a87b-c2284c44488e"
}
}
服务启动方式
- 启用两个 langgraph dev 用于模拟 Product 和 Customer
langgraph dev --port 2024
langgraph dev --port 2025 - 运行 setup_assistants.py 脚本创建两个
assistant_id并存储
执行测试
#!/usr/bin/env python3
"""
LangGraph A2A - Agent间通信测试脚本(使用配置文件)
这个脚本从 assistant_config.json 读取正确的 assistant UUIDs
"""
import asyncio
import aiohttp
import json
import uuid
from pathlib import Path
from typing import Dict, Any
def load_assistant_config() -> Dict[str, Any]:
"""加载 assistant 配置"""
config_file = Path(__file__).parent / "assistant_config.json"
if not config_file.exists():
print("❌ 配置文件不存在,请先运行: python setup_assistants.py")
exit(1)
with open(config_file, 'r') as f:
return json.load(f)
async def send_a2a_message(
session: aiohttp.ClientSession,
url: str,
message: str,
thread_id: str = None
) -> Dict[str, Any]:
"""通过A2A协议发送消息"""
if thread_id is None:
thread_id = str(uuid.uuid4())
payload = {
"jsonrpc": "2.0",
"id": str(uuid.uuid4()),
"method": "message/send",
"params": {
"message": {
"role": "user",
"parts": [{"kind": "text", "text": message}]
},
"messageId": str(uuid.uuid4()),
"thread": {"threadId": thread_id}
}
}
headers = {"Accept": "application/json", "Content-Type": "application/json"}
async with session.post(url, json=payload, headers=headers, timeout=aiohttp.ClientTimeout(total=60)) as response:
response.raise_for_status()
return await response.json()
def extract_response_text(result: Dict[str, Any]) -> str:
"""从A2A响应中提取文本内容"""
# 检查是否有错误
if "error" in result:
return f"错误: {result['error'].get('message', '未知错误')}"
# 提取 artifacts
artifacts = result.get("result", {}).get("artifacts", [])
if artifacts and artifacts[0].get("parts"):
return artifacts[0]["parts"][0].get("text", "无文本内容")
return "无法解析响应"
async def test_customer_support_with_a2a(config: Dict[str, Any]):
"""测试: 通过 Customer Support Agent 进行 A2A 通信
正确的流程:
用户 → Customer Support Agent → (A2A) → Product Catalog Agent → Customer Support → 用户
"""
customer_support_url = config["customer_support"]["a2a_endpoint"]
async with aiohttp.ClientSession() as session:
test_queries = [
"我想了解一下 iPhone 15 Pro 的情况",
"MacBook Pro 14 有货吗?价格多少?"
]
for i, query in enumerate(test_queries, 1):
print(f"👤 用户: {query}")
result = await send_a2a_message(session, customer_support_url, query)
response_text = extract_response_text(result)
print(f"🎧 客服: {response_text}")
async def main():
"""主测试函数"""
config = load_assistant_config()
await test_customer_support_with_a2a(config)
if __name__ == "__main__":
asyncio.run(main())
运行结果如下:
👤 用户: 我想了解一下 iPhone 15 Pro 的情况
🎧 客服: 您好!我很乐意为您介绍 **iPhone 15 Pro** 的情况!😊
根据我们产品目录系统的最新信息:
📱 **iPhone 15 Pro 产品详情:**
- **价格:** $999
- **存储容量:** 128GB
- **颜色:** 钛金色
- **库存状态:** ⚠️ **库存紧张**(目前仅剩 8 台)
⚡ **温馨提示:**
由于这款产品库存较少,如果您有购买意向,建议尽快下单以免错过哦!
📋 **其他选择:**
如果您需要了解:
- 其他存储容量版本(256GB/512GB/1TB)
- 其他颜色选项
- 或者想了解 iPhone 15 Pro Max 等其他机型
请随时告诉我,我会立即为您查询!有任何问题都欢迎咨询~ 😊
=========================================
👤 用户: MacBook Pro 14 有货吗?价格多少?
🎧 客服: 您好!很高兴为您服务!😊
是的,**MacBook Pro 14" 目前有货**!
**产品详情:**
- 💰 **价格:** $1,999
- ✅ **库存状态:** 有货(库存充足,目前有22台)
- 💻 **配置信息:**
- M3 Pro 芯片
- 18GB 内存
- 512GB 固态硬盘
这款产品目前库存充足,如果您有购买意向,现在是个不错的时机!
请问您还需要了解其他信息吗?比如:
- 其他配置选项
- 配送方式
- 保修服务
- 或者其他产品信息
我随时为您服务!🌟
参考文献:
5-Day AI Agents Intensive Course with Google
Prototype to Production
Day 5a - Agent2Agent Communication


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









