







环境说明:redis源码版本 5.0.3;我在阅读源码过程做了注释,git地址:https://gitee.com/xiaoangg/redis_annotation
参考书籍:《redis的设计与实现》
文章推荐:
redis源码阅读-一--sds简单动态字符串
redis源码阅读--二-链表
redis源码阅读--三-redis散列表的实现
redis源码浅析--四-redis跳跃表的实现
redis源码浅析--五-整数集合的实现
redis源码浅析--六-压缩列表
redis源码浅析--七-redisObject对象(下)(内存回收、共享)
redis源码浅析--八-数据库的实现
redis源码浅析--九-RDB持久化
redis源码浅析--十-AOF(append only file)持久化
redis源码浅析--十一.事件(上)文件事件
redis源码浅析--十一.事件(下)时间事件
redis源码浅析--十二.单机数据库的实现-客户端
redis源码浅析--十三.单机数据库的实现-服务端 - 时间事件
redis源码浅析--十三.单机数据库的实现-服务端 - redis服务器的初始化
redis源码浅析--十四.多机数据库的实现(一)--新老版本复制功能的区别与实现原理
redis源码浅析--十四.多机数据库的实现(二)--复制的实现SLAVEOF、PSYNY
redis源码浅析--十五.哨兵sentinel的设计与实现
redis源码浅析--十六.cluster集群的设计与实现
redis源码浅析--十七.发布与订阅的实现
redis源码浅析--十八.事务的实现
redis源码浅析--十九.排序的实现
redis源码浅析--二十.BIT MAP的实现
redis源码浅析--二十一.慢查询日志的实现
redis源码浅析--二十二.监视器的实现
前言
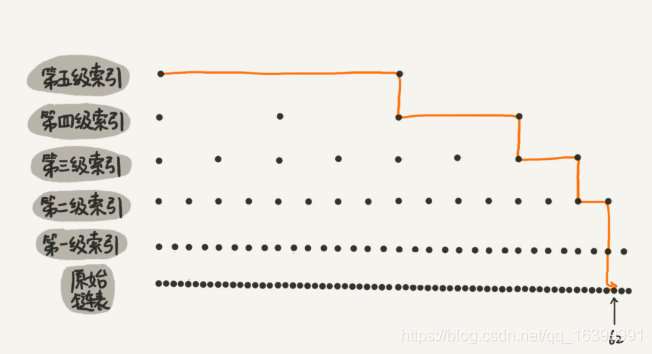
如上图在链表上加多级索引的结构,就是跳表;
在大部分情况下,跳跃表的效率和平衡树媲美,但跳跃表的实现比平衡树更简单,所以很多程序用跳跃表替代平衡树;
一 数据结构
redis跳表的实现主要有zskiplistNode和zskiplist两个结构定义。zskiplist记录跳表的整体信息,zskiplistNode则用于记录每个节点的信息;
zskiplistNode和zskiplist定义位于server.h中;
//跳表节点 双向链表
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
//指向上一个节点
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span; //从当前节点到forward指向下一个节点的跨度
} level[];
} zskiplistNode;
typedef struct zskiplist {
//header是哨兵
struct zskiplistNode *header, *tail;//header 指向表头 tail指向表尾部
unsigned long length; //表长度
int level; //跳表的索引层级
} zskiplist;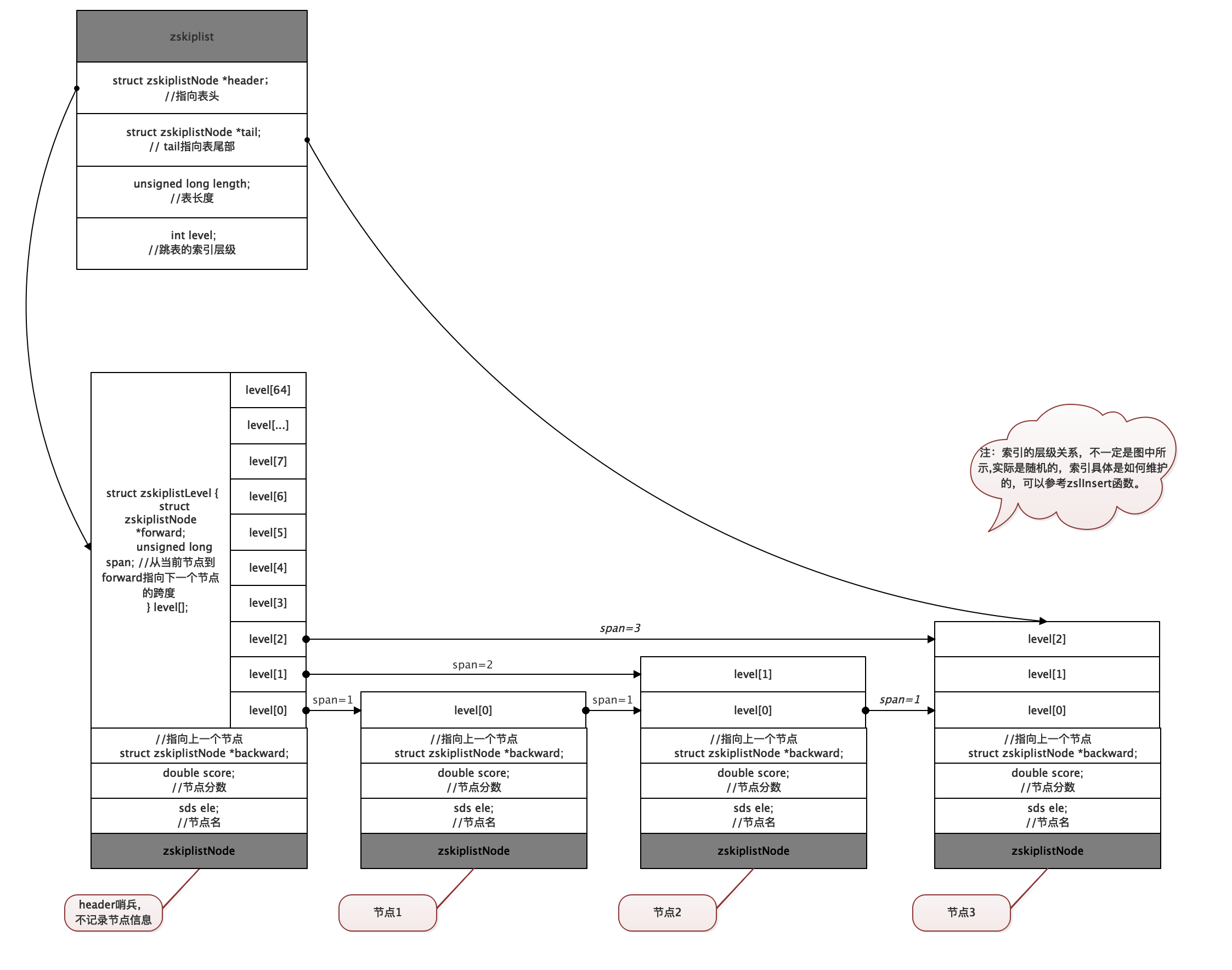
二.跳表的API
跳表api的声明位于server.h中,具体实现位置t_zset.c 中;
注:跳表相关的接口都是以zsl开头;
zskiplist *zslCreate(void); //创建一个跳表
void zslFree(zskiplist *zsl); //释放跳表
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele);//向跳表中插入一个节点
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node); //删除一个节点
zskiplistNode *zslFirstInRange(zskiplist *zsl, zrangespec *range); //获取指定范围内的第一个元素
zskiplistNode *zslLastInRange(zskiplist *zsl, zrangespec *range); //获取指定范围内的最后一个元素
unsigned long zslGetRank(zskiplist *zsl, double score, sds o); //获取一个元素的排名浅析zslInsert函数
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
//update数组保存了要插入的新节点在插入之后各个level的位置
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
//定位到每个层级的要插入节点的位置(记录在update中)
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position *///rank存储到达插入位置 跨度
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x; //update存储 新插入的节点 在 每个层级索引的位置(指针)
//rank存储每个层级索引,在链表中的位置(是第几个元素)
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
level = zslRandomLevel(); //随机更新level层级内的跳表索引(level至少是1)
if (level > zsl->level) { //新的索引层级大于原有层级时 初始化新的层级索引(大于原有索引层级的部分)
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele);//创建一个跳表节点 包含“分数”,“节点名”和“level层索引”
for (i = 0; i < level; i++) { //开始循环更新索引
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]); //更新【新节点】的跨度 (理解rank数组作用+画图 这段代码更易理解)
update[i]->level[i].span = (rank[0] - rank[i]) + 1; //更新 【前置节点】的跨度
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {//更高层级的索引 span跨度+1
update[i]->level[i].span++;
}
//backward指向上一个节点
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}














 208
208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









