







文章介绍了如何对随机森林模型进行参数调优
原文来自:http://www.analyticsvidhya.com/blog/2015/06/tuning-random-forest-model/
为什么要调整机器学习算法?
一个月以前,我在kaggle上参加了一个名为TFI的比赛。 我第一次提交的结果在50%。 我不懈努力在特征工程上花了超过2周的时间,勉强达到20%。 出乎我意料的事是,在调整机器学习算法参数之后,我能够达到前10%。
这是这就是机器学习算法参数调优的重要性。 随机森林是在工业界中使用的最简单的机器学习工具之一。 在我们以前的文章中,我们已经向您介绍了随机森林和和CART模型进行了对比 。 机器学习工具包正由于这些算法的表现而被人所熟知。。
随机森林是什么?
随机森林是一个集成工具,它使用观测数据的子集和变量的子集来建立一个决策树。 它建立多个这样的决策树,然后将他们合并在一起以获得更准确和稳定的预测。 这样做最直接的事实是,在这一组独立的预测结果中,用投票方式得到一个最高投票结果,这个比单独使用最好模型预测的结果要好。
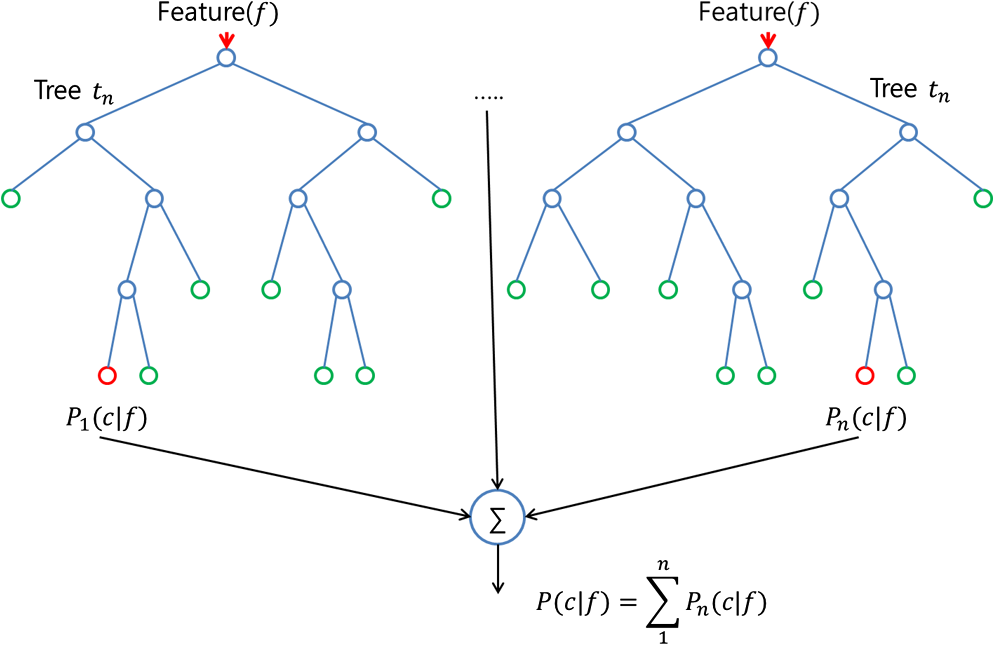 我们通常将随机森林作为一个黑盒子,输入数据然后给出了预测结果,无需担心模型是如何计算的。这个黑盒子本身有几个我们可以摆弄的杠杆。 每个杠杆都能在一定程度上影响模型的性能或资源 -- 时间平衡。 在这篇文章中,我们将更多地讨论我们可以调整的杠杆,同时建立一个随机林模型。
我们通常将随机森林作为一个黑盒子,输入数据然后给出了预测结果,无需担心模型是如何计算的。这个黑盒子本身有几个我们可以摆弄的杠杆。 每个杠杆都能在一定程度上影响模型的性能或资源 -- 时间平衡。 在这篇文章中,我们将更多地讨论我们可以调整的杠杆,同时建立一个随机林模型。
调整随机森林的参数/杠杆
随机森林的参数即可以增加模型的预测能力,又可以使训练模型更加容易。 以下我们将更详细地谈论各个参数(请注意,这些参数,我使用的是Python常规的命名法):
1.使模型预测更好的特征
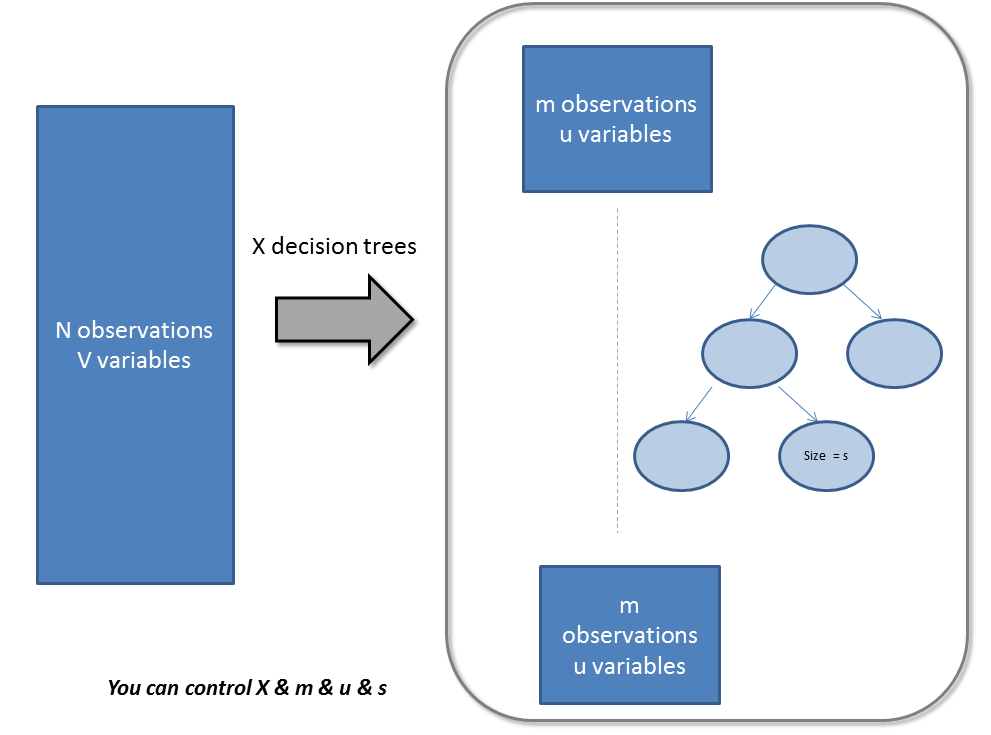
主要有3类特征可以被调整,以改善该模型的预测能力:
A. max_features:
随机森林允许单个决策树使用特征的最大数量。 Python为最大特征数提供了多个可选项。 下面是其中的几个:
-
Auto/None :简单地选取所有特征,每颗树都可以利用他们。这种情况下,每颗树都没有任何的限制。
-
sqrt :此选项是每颗子树可以利用总特征数的平方根个。 例如,如果变量(特征)的总数是100,所以每颗子树只能取其中的10个。“log2”是另一种相似类型的选项。
-
0.2:此选项允许每个随机森林的子树可以利用变量(特征)数的20%。如果想考察的特征x%的作用, 我们可以使用“0.X”的格式。
max_features如何影响性能和速度?
增加max_features一般能提高模型的性能,因为在每个节点上,我们有更多的选择可以考虑。 然而,这未必完全是对的,因为它降低了单个树的多样性,而这正是随机森林独特的优点。 但是,可以肯定,你通过增加max_features会降低算法的速度。 因此,你需要适当的平衡和选择最佳max_features。
B. n_estimators:
在利用最大投票数或平均值来预测之前,你想要建立子树的数量。 较多的子树可以让模型有更好的性能,但同时让你的代码变慢。 你应该选择尽可能高的值,只要你的处理器能够承受的住,因为这使你的预测更好更稳定。
C. min_sample_leaf:
如果您以前编写过一个决策树,你能体会到最小样本叶片大小的重要性。 叶是决策树的末端节点。 较小的叶子使模型更容易捕捉训练数据中的噪声。 一般来说,我更偏向于将最小叶子节点数目设置为大于50。在你自己的情况中,你应该尽量尝试多种叶子大小种类,以找到最优的那个。
2.使得模型训练更容易的特征
有几个属性对模型的训练速度有直接影响。 对于模型速度,下面是一些你可以调整的关键参数:
A. n_jobs:
这个参数告诉引擎有多少处理器是它可以使用。 “-1”意味着没有限制,而“1”值意味着它只能使用一个处理器。 下面是一个用Python做的简单实验用来检查这个指标:
%timeit
model = RandomForestRegressor(n_estimator = 100, oob_score = TRUE,n_jobs = 1,random_state =1)
model.fit(X,y)
Output ———- 1 loop best of 3 : 1.7 sec per loop
%timeit
model = RandomForestRegressor(n_estimator = 100,oob_score = TRUE,n_jobs = -1,random_state =1)
model.fit(X,y)
Output ———- 1 loop best of 3 : 1.1 sec per loop
“%timeit”是一个非常好的功能,他能够运行函数多次并给出了最快循环的运行时间。 这出来非常方便,同时将一个特殊的函数从原型扩展到最终数据集中。
B. random_state:
此参数让结果容易复现。 一个确定的随机值将会产生相同的结果,在参数和训练数据不变的情况下。 我曾亲自尝试过将不同的随机状态的最优参数模型集成,有时候这种方法比单独的随机状态更好。
C. oob_score:
这是一个随机森林交叉验证方法。 它和留一验证方法非常相似,但这快很多。 这种方法只是简单的标记在每颗子树中用的观察数据。 然后对每一个观察样本找出一个最大投票得分,是由那些没有使用该观察样本进行训练的子树投票得到。
下面函数中使用了所有这些参数的一个例子:
model = RandomForestRegressor(n_estimator = 100, oob_score = TRUE, n_jobs = -1,random_state =50,
max_features = "auto", min_samples_leaf = 50)
model.fit(x, y)
通过案例研究学习
我们以在以前的文章中经常提到泰坦尼克号为例。 让我们再次尝试同样的问题。 这种情况下的目标是,了解调整随机森林参数而不是找到最好的特征。 试试下面的代码来构建一个基本模型:
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import roc_auc_score
import pandas as pd
x = pd.read_csv("train.csv")
y = x.pop("Survived")
model = RandomForestRegressor(n_estimator = 100 , oob_score = TRUE, random_state = 42)
model.fit(x(numeric_variable,y)
print "AUC - ROC : ", roc_auc_score(y,model.oob_prediction)
AUC - ROC:0.7386
这是一个非常简单没有参数设定的模型。 现在让我们做一些参数调整。 正如我们以前讨论过,我们有6个关键参数来调整。 我们有一些Python内置的的网格搜索算法,它可以自动调整所有参数。在这里让我们自己动手来实现,以更好了解该机制。 下面的代码将帮助您用不同的叶子大小来调整模型。
练习:试试运行下面的代码,并在评论栏中找到最佳叶片大小。
sample_leaf_options = [1,5,10,50,100,200,500]
for leaf_size in sample_leaf_options :
model = RandomForestRegressor(n_estimator = 200, oob_score = TRUE, n_jobs = -1,random_state =50,
max_features = "auto", min_samples_leaf = leaf_size)
model.fit(x(numeric_variable,y)
print "AUC - ROC : ", roc_auc_score(y,model.oob_prediction)
备注
就像是随机森林,支持向量机,神经网络等机器学习工具都具有高性能。 他们有很高的性能,但用户一般并不了解他们实际上是如何工作的。 不知道该模型的统计信息不是什么问题,但是不知道如何调整模型来拟合训练数据,这将会限制用户使用该算法来充分发挥其潜力。 在一些后续的文章中,我们将讨论其他机器学习算法,像支持向量机,GBM和neaural networks。














 2170
2170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









