







向量化通常是消除代码中显式 f o r for for循环语句的艺术。
一、为什么向量化?
看下面这个例子,如果要计算: z = w T + b . z=w^T+b. z=wT+b.
- 在非向量化的模式下:
z = 0
for i in range(n_x):
z += w[i]*x[i]
z += b
- 在向量化的模式下:
z = np.dot(w,x)+b
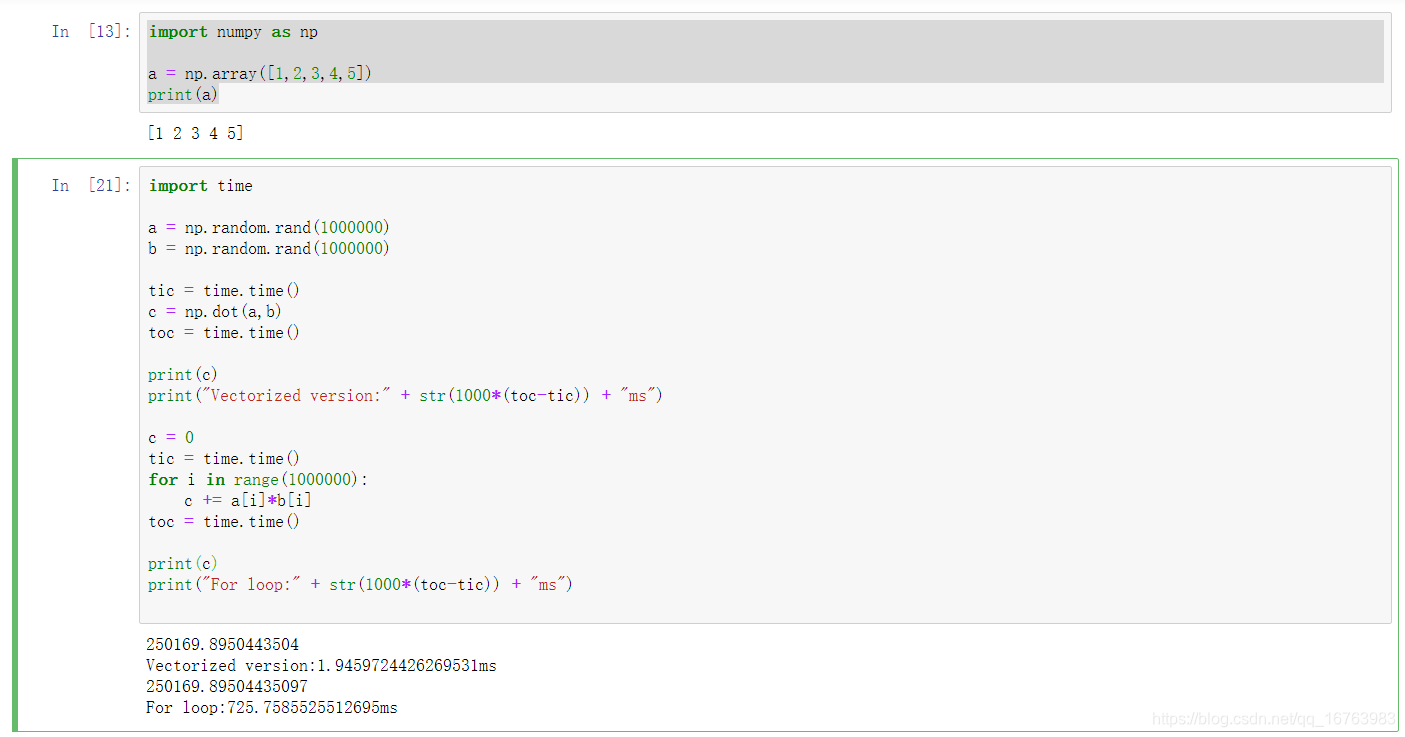
为直观感受向量化和非向量化的运算速度差别,我们在jutypter notebook中进行测试。
import time
a = np.random.rand(1000000)
b = np.random.rand(1000000)
tic = time.time()
c = np.dot(a,b)
toc = time.time()
print(c)
print("Vectorized version:" + str(1000*(toc-tic)) + "ms")
c = 0
tic = time.time()
for i in range(1000000):
c += a[i]*b[i]
toc = time.time()
print(c)
print("For loop:" + str(1000*(toc-tic)) + "ms")
250169.8950443504
Vectorized version:1.9459724426269531ms
250169.89504435097
For loop:725.7585525512695ms
二、GPU and CPU
可扩展的深度学习是在GPU(图像处理单元)上的,但是我们做案例用到的jupyter notebook是在CPU上的。他们都有并行化的指令,叫做SIMD指令,即单指令流多指令流。如果用到内置函数如np.dot(),这样python的numpy能够充分利用并行化,更快计算。这一点对CPU GPU同等成立,只是GPU更擅长SIMD的计算(当然CPU其实也不差)
三、向量化例子

u
=
A
v
u=Av
u=Av
u = np.dot(A,v)
v
=
[
v
1
.
.
.
v
n
]
,
u
=
[
e
v
1
.
.
.
e
v
n
]
v=\left[ \begin{matrix} v_1\\...\\v_n \end{matrix} \right],u=\left[ \begin{matrix} e^{v_1}\\...\\e^{v_n} \end{matrix} \right]
v=⎣⎡v1...vn⎦⎤,u=⎣⎡ev1...evn⎦⎤
非向量化:
u = np.zeros((n,1))
for i in range(n):
u[i] = math.exp(v[i])
向量化:
import numpy as np
u = np.exp(v)
说到numpy库的数学计算函数,有如下函数是经常用到的:
np.log(v) #以e为底的对数
np.abs(v) # 绝对值
np.maxmum(v,0) # 最大值,与0相比
v**2 # 指数 v平方
在逻辑回归求导的代码中,就可以引入向量化计算,优化
n
x
n_x
nx维特征的循环体。

四、向量化逻辑回归算法
向量化是非常让人兴奋的技术,可以在后续的神经网络中完全避免了显式for循环,大大提高运算速度。
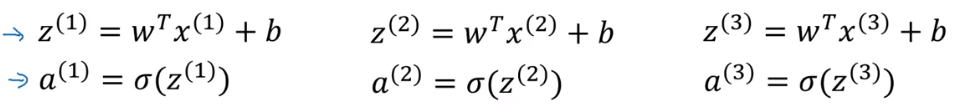
在多个样本中计算时(如上图),如果非向量化运算,我们需要重复运算
m
m
m次这个过程。
X
=
[
.
.
.
.
.
.
.
.
.
.
.
.
x
(
1
)
x
(
2
)
.
.
.
x
(
m
)
.
.
.
.
.
.
.
.
.
.
.
.
]
.
X=\left[ \begin{matrix} ...&...&...&...\\x^{(1)}&x^{(2)}&...&x^{(m)}\\...&...&...&... \end{matrix} \right].
X=⎣⎡...x(1)......x(2)...............x(m)...⎦⎤.
X.shape = (n_x,m).
Z
=
[
z
(
1
)
z
(
2
)
.
.
.
z
(
m
)
]
=
w
T
X
+
[
b
b
.
.
.
b
]
=
[
w
T
x
(
1
)
+
b
w
T
x
(
2
)
+
b
.
.
.
w
T
x
(
3
)
+
b
]
.
Z=\left[ \begin{matrix} z^{(1)}&z^{(2)}&...&z^{(m)}\end{matrix} \right]=w^TX+\left[ \begin{matrix} b&b&...&b \end{matrix}\right]=\left[ \begin{matrix} w^Tx^{(1)}+b&w^Tx^{(2)}+b&...&w^Tx^{(3)}+b \end{matrix}\right].
Z=[z(1)z(2)...z(m)]=wTX+[bb...b]=[wTx(1)+bwTx(2)+b...wTx(3)+b].
如上计算式用向量代码表示:
z=np.dot(w.T,X)+b
在Python中会自动把常量b扩展成1xm的行向量,这在Python中称作广播(broadcasting)
那么
a
a
a怎么计算呢?
A
=
[
a
(
1
)
a
(
2
)
.
.
.
a
(
m
)
]
=
σ
(
z
)
.
A=\left[ \begin{matrix} a^{(1)}&a^{(2)}&...&a^{(m)}\end{matrix} \right]=\sigma(z).
A=[a(1)a(2)...a(m)]=σ(z).
小结:以上呈现的是正向传播一步迭代的向量化实现方法,这个方法使我们避开计算速度缓慢的for循环,而一次性处理 m m m个训练样本,从而得到一系列样本中的 z , a z,a z,a值,即高效计算激活函数。
五、向量化逻辑回归的梯度输出
前面分析了正向传播计算预测值的向量化,现在来分析反向传播求导过程的向量化。
在前面学习中,我们已经求得了:
d
z
=
a
−
y
,
d
w
=
x
d
z
,
d
b
=
d
z
.
dz=a-y,dw=xdz,db=dz.
dz=a−y,dw=xdz,db=dz. 那么这个结果我们可以直接使用上。
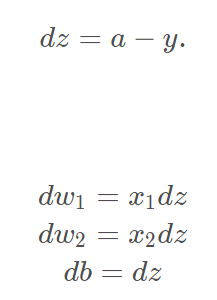

简而言之,
d
b
,
d
w
db ,dw
db,dw这两个参数的求解可以通过简单的向量运算实现。
db = 1/m*np.sum(dz)
dw = 1/m*X*dz
现在我们来再审视一遍整个逻辑回归的正向传播(求预测值)和反向传播(求导求参数更新)过程,是怎样除去两个for循环的。

高度向量化的逻辑回归代码如下:
for iter in range(step_num):
z = np.dot(w.T,X)+b
A = f(z)
dz = A-Y
dw = (1/m)*np.dot(X,dz.T)
db = (1/m)*np.sum(dz)
w := w-lr*dw
b := b-lr*db
六、numpy向量说明
提一些numpy相关的说明以减少可能出现的bug.
首先引入numpy,生成5个随机高斯变量存储在数组a中。
import numpy as np
a = np.random.randn(5)
print(a)
[-0.56189854 -1.15398922 -1.22490327 0.00217112 0.44074155]
分析一下这个它的结构
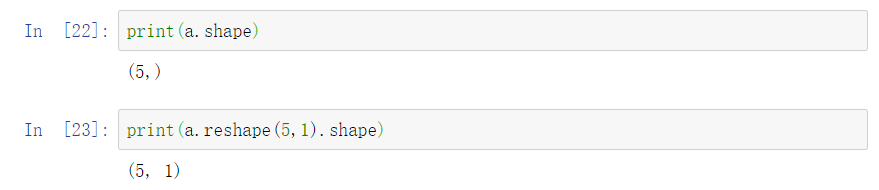
print(a.shape)
(5,)
所以,这个a是秩为1的数组!既不是行向量也不是列向量!
为了测试不是行/列向量,用转置和内积做实验分析。
print(a.T)
print(np.dot(a.T, a))
print(np.dot(a, a.T))
[-0.56189854 -1.15398922 -1.22490327 0.00217112 0.44074155]
3.3420669323770062
3.3420669323770062
数据表明:上述a仅仅是一个秩为1的数组,而非向量!不要在编程过程中使用该数组!
那么我们应该怎么样生成随机数才能方便处理呢?答案是直接生成行/列向量。
a = np.random.randn(5, 1)
print(a)
[[ 0.60495052]
[-2.12322553]
[-0.86336334]
[-0.17266097]
[ 0.31836149]]
同样的测试方法,输出转置和内积看看向量运算的结果。
print(a.shape)
print(a.T)
print("\n")
print(np.dot(a,a.T))
(5, 1)
[[ 0.60495052 -2.12322553 -0.86336334 -0.17266097 0.31836149]]
[[ 0.36596513 -1.28444638 -0.5222921 -0.10445134 0.19259295]
[-1.28444638 4.50808664 1.83311509 0.36659819 -0.67595324]
[-0.5222921 1.83311509 0.74539626 0.14906916 -0.27486164]
[-0.10445134 0.36659819 0.14906916 0.02981181 -0.0549686 ]
[ 0.19259295 -0.67595324 -0.27486164 -0.0549686 0.10135404]]
验证成功!
常常会用到assert()这样一个声明,用于断言一个向量/矩阵的维度,如果正确即不报错。assert执行很快,可以看作代码的文档,不用担心使用assert
assert(a.shape == (5, 1))
最后,如果我们得到的是一个秩为1的数组,也可以通过reshape()函数修正,reshape执行速度同样很快,不要害怕使用,如下图。















 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











