







学习率衰减
考虑学习率不变的情况,梯度下降难以在最后达到收敛,如果采用学习率衰减方式呢?在刚开始能承受大步伐的梯度下降,随着梯度下降的进行,学习率衰减有利于最后收敛到一个趋近于最低点。
在1epoch内(1 pass through data):
α
=
α
0
1
+
d
e
c
a
y
_
r
a
t
e
∗
e
p
o
c
h
_
n
u
m
\alpha=\frac{\alpha_0}{1+decay\_rate*epoch_\_num}
α=1+decay_rate∗epoch_numα0
其他学习率衰减的方法:
α
=
0.9
5
e
p
o
c
h
_
n
u
m
∗
α
0
\alpha=0.95^{epoch\_num}*\alpha_0
α=0.95epoch_num∗α0
α = k e p o c h _ n u m ∗ α 0 \alpha=\frac{k}{\sqrt{epoch\_num}}*\alpha_0 α=epoch_numk∗α0
α = k t ∗ α 0 \alpha=\frac{k}{\sqrt{t}}*\alpha_0 α=tk∗α0
也有用离散值作为学习率的。
局部最优问题
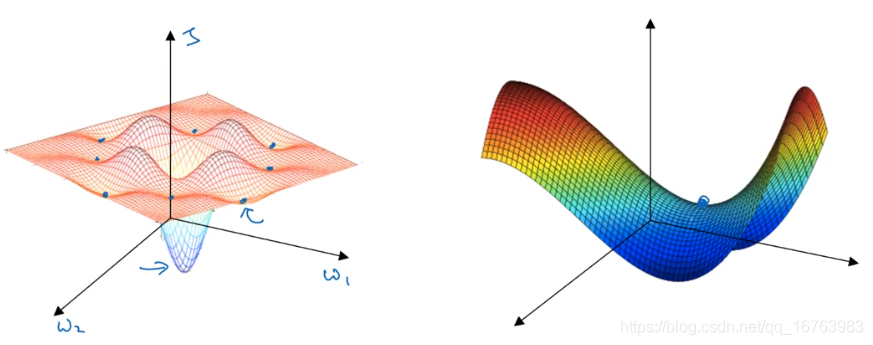
在神经网络中,我们通常遇到的情况是右图中的鞍点,而不是左图中的局部最优。
想象你坐在马鞍上,那么你坐下的那一个点就是导数为0的点,
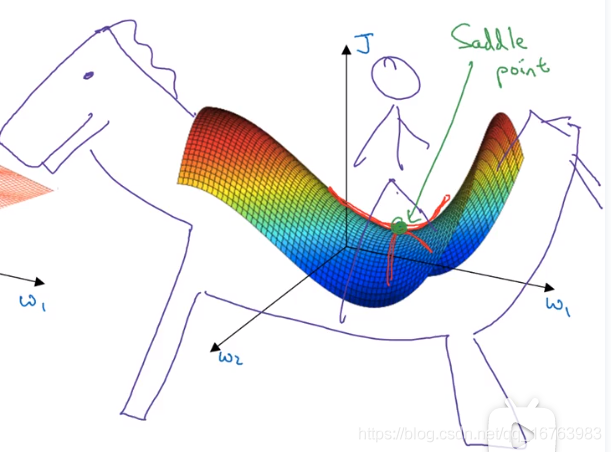
有关平稳段的问题
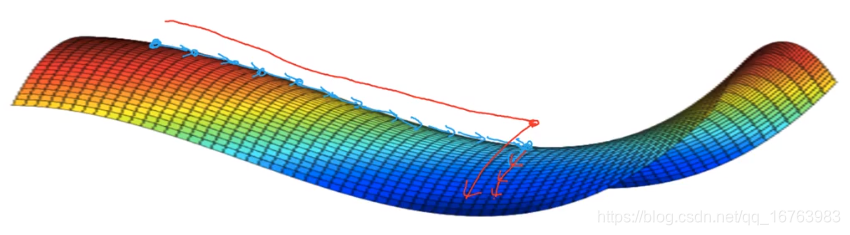
- 平缓段让学习变得很慢(这是Momentum Adam RMSprop优化算法可以加速这个过程,尽早走出平稳段)
- 不太可能困在不好的局部最优(前提:有大量的参数,J也是在高维空间)















 1470
1470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











