









原文:
-
KDD’21 | 淘宝搜索中语义向量检索技术
https://zhuanlan.zhihu.com/p/409390150?utm_source=wechat_session&utm_medium=social&utm_oi=637963847940706304 -
作者微信公众号:
https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzU0MDA1MzI0Mw==&scene=124#wechat_redirect -
作者知乎专栏:
https://www.zhihu.com/column/mgxs-note
概览
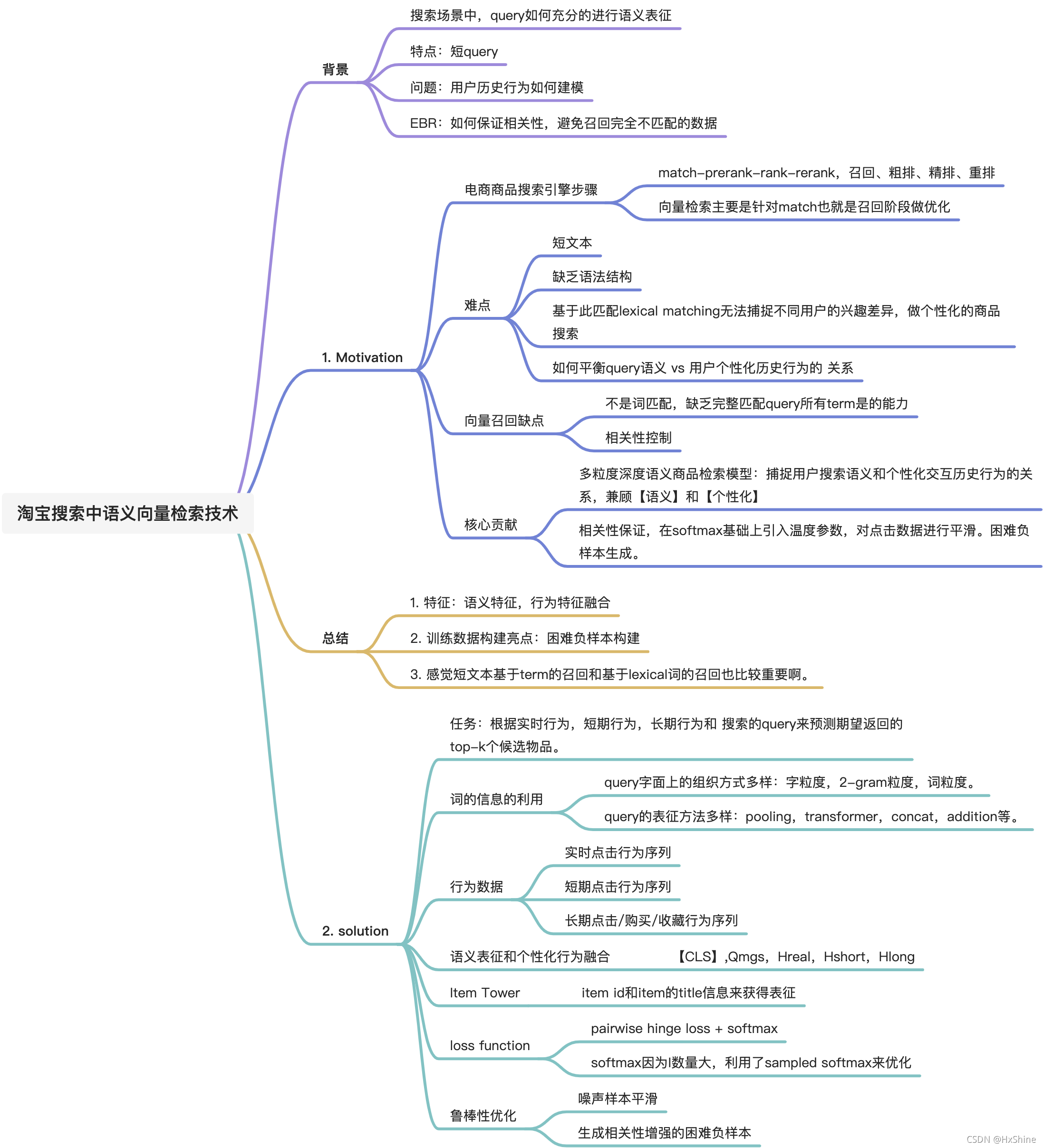
1. Motivation
基于词lexical matching的匹配召回缺乏对用户的历史行为进行建模,然后向量检索主要是对用户历史行为进行建模,平衡query语义 和 用户个性历史化行为 之间的关系,感觉看到这就感觉有点虚啊,大部分应该都是直接语义相关吧,个性化不知道带来的提升能到达什么量级,这是已经很卷了是吗?
2. Solution
-
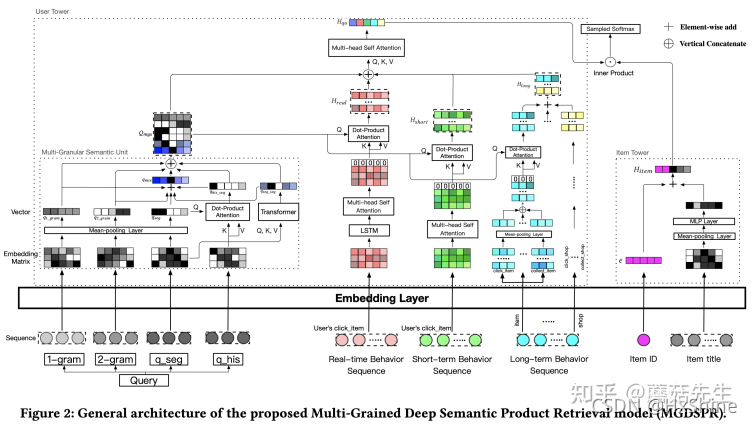
任务:根据实时行为,短期行为,长期行为和 搜索的query来预测期望返回的top-k个候选物品。
网络结构图:其中query也利用了历史的搜索query数据,并结合了多粒度的词的信息。 -
词的信息的利用:
- query字面上的组织方式多样:字粒度,2-gram粒度,词粒度。
- query的表征方法多样:pooling,transformer,concat,addition等。
-
网络结构
-
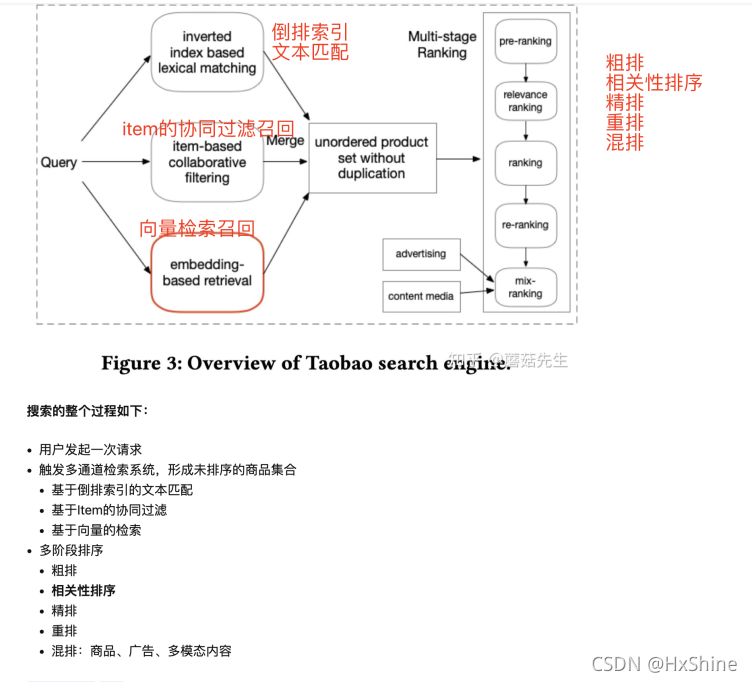
商品总体召回框架
3. Evaluation
-
Recall@K
-
Pgood,top-k中有多少个结果和query强相关。
-
Numprank,有多少进入了后面的排序环节,证明相关性比较高。

-
GMV

4. 总结
- 特征:语义特征,行为特征融合
- 训练数据构建亮点:困难负样本构建
- 感觉短文本基于term的召回和基于lexical词的召回也比较重要啊。














 4806
4806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









