







强化学习:
 通过式6迭代出最优解。其中,加号前面部分表示更新前值函数,后面部分表示更新后值函数,以α(学习效率)比值融合更新值函数。r(s,a,s')为当前状态采取动作a之后变成新的状态的奖励reward,γ为新状态值函数的衰减值。
通过式6迭代出最优解。其中,加号前面部分表示更新前值函数,后面部分表示更新后值函数,以α(学习效率)比值融合更新值函数。r(s,a,s')为当前状态采取动作a之后变成新的状态的奖励reward,γ为新状态值函数的衰减值。
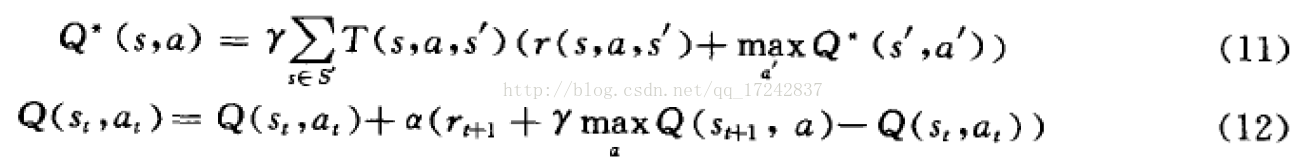 式11/12为Q-learning算法,在TD算法的基础上采用状态、动作对的表现形式。和TD算法都是模型无关的,因此收敛速度慢。
式11/12为Q-learning算法,在TD算法的基础上采用状态、动作对的表现形式。和TD算法都是模型无关的,因此收敛速度慢。
Dyna-Q也是model-based,但与sarsa不同的是,Dyna-Q建立更新单独的模型M,其具体的算法步骤为:
分类:
- 强化学习分为顺序学习(马尔可夫:当前状态向下一状态转移的概率和奖赏值只取决于当前状态选择的动作,与历史状态和历史动作无关)和非顺序学习,顺序学习可以用动态规划算法求取最优解。
- 强化学习还分为基于模型的和model-free:基于模型的算法不仅优化策略,还在训练过程中理解真实世界模型,具有更快的收敛速度。
- 强化学习侧重点不同分为经验强化型学习和最优搜索型学习。经验强化型学习算法充分利用已获得的经验知识,最优搜索型则尝试更多知识。因此经验强化型算法收敛更快,但是得到的往往不是最优解,而是局部最优解。
- 强化学习的内容有:
- 局部学习:更多系统无法感知系统,只能感知部分,根据贝叶斯定律更新概率(状态和动作不确定)
- 函数估计:采用参数化函数替代策略查找表
- 多agent 学习:每个agent通过与其他agent交互加快学习过程,每个agent拥有独立的学习机制。分为合作性多agent强化学习、竞争性多agent强化学习、半竞争型多agent强化学习。竞争型就像两个对手,他们的值函数互为相反的。需要机制判断是否采用竞争型强化学习。
- 规则抽取:将强化学习技术所得到的策略,通过规则抽取,转化成其他学习技术所能够处理的表示形式。从而可以利用其他技术进行更深层次的学习和推理;同时在环境发生改变是可以将抽取的规则用于强化学习中,提高新一次学习的收敛速度。
- 强化学习偏差:通过加入先验知识,加快强化学习收敛速度。
- 分层学习:减少强化学习的维数灾难(策略查找表增大到电脑无法处理)














 505
505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









