







一个bug引发的对大端小端的深入思考
前言
最近工作中,有个同事遇到个问题百思不得其解,音频信号出声始终不正常,非常嘈杂,只能隐隐约约听到一些信息。
一起讨论分析后才发现,参考的代码框架处理网络输入的信号时,是按照大端序处理字节流的,而实际应用场景中输入的字节流是小端序的,此时按大端序取数据会出现只取到低位信息,高位信息损失,从而只能隐隐约约听到音频信号,主体能量幅值已消失。
示例代码
char buff[30];
int data[10];
char *p = buff;
int len = 10;
...
int i;
for (i = 0; i < len; i++)
{
data[i] = (int *)p & 0xFFFFFF00;
p += 3;
}
修改为以下代码,即可恢复正常:
data[i] = (int *)p & 0x00FFFFFF;
大小端定义
大端小端的概念核心
- 针对的是排布以字节为单位的字节序
- 与物理存储地址顺序增长密切相关
- 小端法(Big Endian):低位字节放在低位地址(小弟弟,小端低位字节低位地址)
- 大端法(Little Endian):低位字节放在高位地址
小端口诀: 高高低低 -> 高字节在高地址, 低字节在低地址
大端口诀: 高低低高 -> 高字节在低地址, 低字节在高地址
举例如下,比如数据:
int val = 0x12345678;
- 若内存地址从小到大里面内容为:
0x78, 0x56, 0x34, 0x12,则为小端机器- 若内存地址从小到大里面内容为:
0x12,0x34, 0x56, 0x78,则为大端机器
大端小端与LSB、MSB的关系理解
再比如 int x, 它的地址为0x100。 那么它占据了内存地址中的0x100, 0x101, 0x102, 0x103这四个字节(32位系统,所以int占用4个字节)。
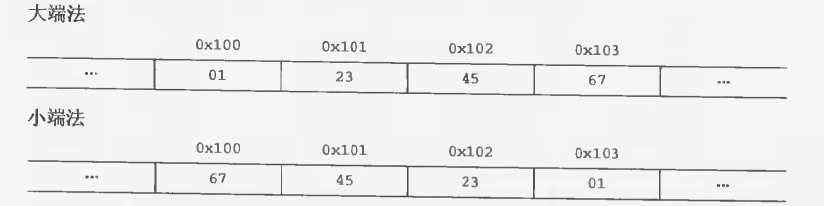
上面只是内存字节组织的一种情况: 多字节对象在内存中的组织有一般有两种约定。 考虑一个W位的整数。
它的各个比特位表达如下:[Xw-1, Xw-2, … , X1, X0],它的MSB (Most Significant Byte, 最高有效字节)为 [Xw-1, Xw-2, … Xw-8]; LSB (Least Significant Byte, 最低有效字节)为 [X7,X6,…, X0]。
其余的字节位于MSB, LSB之间。
LSB和MSB谁位于内存的最低地址,则能区分大小端。如果LSB在MSB前面,既LSB数据放在低地址, 则该机器是小端;反之,则是大端。
扩展:从比特位看LSB和MSB的区别
- LSB,Least Significant Bit,意为最低位有效
- LSB位于二进制数的最右侧,低位前导
- MSB,Most Significant Bit,意为最高位有效
- MSB位于二进制数的最左侧,高位前导
- 符号位的应用
- 若MSB=1,则表示数据为负值
- 若MSB=0,则表示数据为正
网络编程、系统编程涉及不同网络协议传输时,会面临大小端问题。
- 网络传输,服务器常用大端,利于人类理解,从左到右高到低
- 端侧处理,移动端常用小端,使用最广泛,易于计算机理解,依次由地址增长,表征低位到高位的填充
大小端鉴别
大端小端机器的鉴别方法
按地址顺序一个字节一个字节打印数值,观察排布情况,即可确认大小端机器。
void show_bytes(char *c, int len)
{
int i;
for (i = 0; i < len; i++) {
printf("0x%.2x, ", c[i]);
}
printf("\n");
}
int val = 0x12345678;
char *valp = (char *)&val;
show_bytes(valp, 4);
- 若输出为:
0x78, 0x56, 0x34, 0x12,则为小端机器 - 若输出为:
0x12,0x34, 0x56, 0x78,则为大端机器
概念测试
问题1:以下问题答案是多少?
ULONG ATM_UNI_GetParaULONGValByOID(UCHAR *Type )
{
*Type=0x12;
}
ULONG ATM_UNI_MAPIPTable_DeleteHandler (VOID* pMsgRcv, VOID** ppMsgSnd)
{
ULONG ulType=0x456789ab;
ulErrCode = ATM_UNI_GetParaULONGValByOID(&ulType );
printf(”%x”,ulType);
}
- 在小端字节序下打印输出的值是多少?
- 在大端字节序下打印输出的值是多少?
答案: 0x45678912 0x126789ab
解释:
小端,0x [ab] [89] [67] [45] -> [12] [89] [67] [45] printf小端还是从高位开始输出,也即从高地址开始读,得到0x45678912
大端:0x [45] [67] [89] [ab] -> [12] [67] [89] [ab] printf大端还是从高位开始输出,也即从低地址开始读,得到0x126789ab
备注:同一个数据,用大小端存储,不影响printf打印出来的值,值输出时会根据大小端的特点来保证数据解析正确。
问题2:类型转换,对于BigEndian字节序的主机,在执行完Bfunc函数后全局变量a的值是( )
_UL a = 0xffffffff;
_UC Afunc( )
{
return 0x12345678;
}
_UL Bfunc( )
{
a = (_UL)Afunc();
}
- A 0x12 B 0x78
- C 0x12345678 D 0xffffff78
答案:B
解释:
Afunc返回_UC,会发生截断,**无论是大端还是小端当发生截断的时候都只会把最低位的值赋值给新变量。**这里是从int截断为char,因此最终将最低位的0x78赋值给a。
如果只是直接赋值,截断的情况与大小端是没有关系的。
举一反三,如果是小端字节序时,输出依然为B。
问题3:如下代码的输出是多少?(这里和大小端有关系了)
void TestTruncation()
{
unsigned int val1 = 0x12345678;
unsigned char val2 = *(char *)&val1;
printf("val2 = %d\n", val2);
}
答案:
在大端环境下,value2的值应该是0x12,而小端环境下则是0x78。通过地址直接赋值的方式,就涉及到大小端内存的排布。
解释:
小端时,地址增长排布下数据为,
0x [78] [56 [34] [12], 执行 *(char *)&value1 时,则指向了78所在的内存地址,数据范围为1个字节,将0x78拷贝给了value2。大端时,地址增长排布下数据为,
0x [12] [34 [56] [78], 执行 *(char *)&value1 时,则指向了12所在的内存地址,数据范围为1个字节,将0x12拷贝给了value2。(注:printf输出或者解析值时,小端依然是先从高位地址取高位数据12,大端依然是先从低位地址取高位数据12)。
如果这几个问题能独立分析清楚,相信对大小端应该就有较深的理解了。
参考资料
- 书籍:深入理解计算机系统, p29














 266
266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









