




☘前言☘
读完这篇博客,你可以学到什么?
- excel的读取和写入方式
- 获取接口的方式
- 多线程提高爬虫效率
- 云端服务器部署web服务实时更新

这篇博客里,我将在上一篇文章的基础上进一步来发掘网站接口api提高访问速度,进一步多线程发掘更快的速度,最后部署到web服务器来实现实时更新排行榜的访问。
没有读过上一篇文章没有基础的同学可以先看一下之前的文章【从零开始的python生活①】手撕爬虫扒一扒力扣的用户刷题数据
全文大约阅读时间: 20min
🧑🏻作者简介:一个从工业设计改行学嵌入式的年轻人
✨联系方式:2201891280(QQ)
主要内容
一、改进原因
上一篇的文章代码改进(主要是使用无头模式,不显示画面来提高速度):
ch_options = webdriver.ChromeOptions() # 为Chrome配置无头模式 ch_options.add_argument("--headless") ch_options.add_argument('--no-sandbox') ch_options.add_argument('--disable-gpu') ch_options.add_argument('--disable-dev-shm-usage') ch_options.add_argument('log-level=3') ch_options.add_experimental_option("excludeSwitches", ['enable-automation', 'enable-logging']) ch_options.add_experimental_option('useAutomationExtension', False) ch_options.add_argument("--disable-blink-features=AutomationControlled") driver = webdriver.Chrome(options=ch_options) driver.implicitly_wait(10)🚨1.时间效率
下图是我在树莓派4B上运行的时间截图。900s,这在服务器上是不可接受的
2.资源占用
这是我电脑运行时的资源占用,如果服务器运行的话直接炸裂。。。可能会导致我本身的web服务停止反应。


二、接口的获取
1.找到查询信息
首先访问自己的主页并按f12进入开发者工具
按ctrl+f查找自己的刷题数目
可以成功找到对应的关键字为acTotal并且对应的请求就是看标头。
2.确定传入参数
2.1确定头部信息
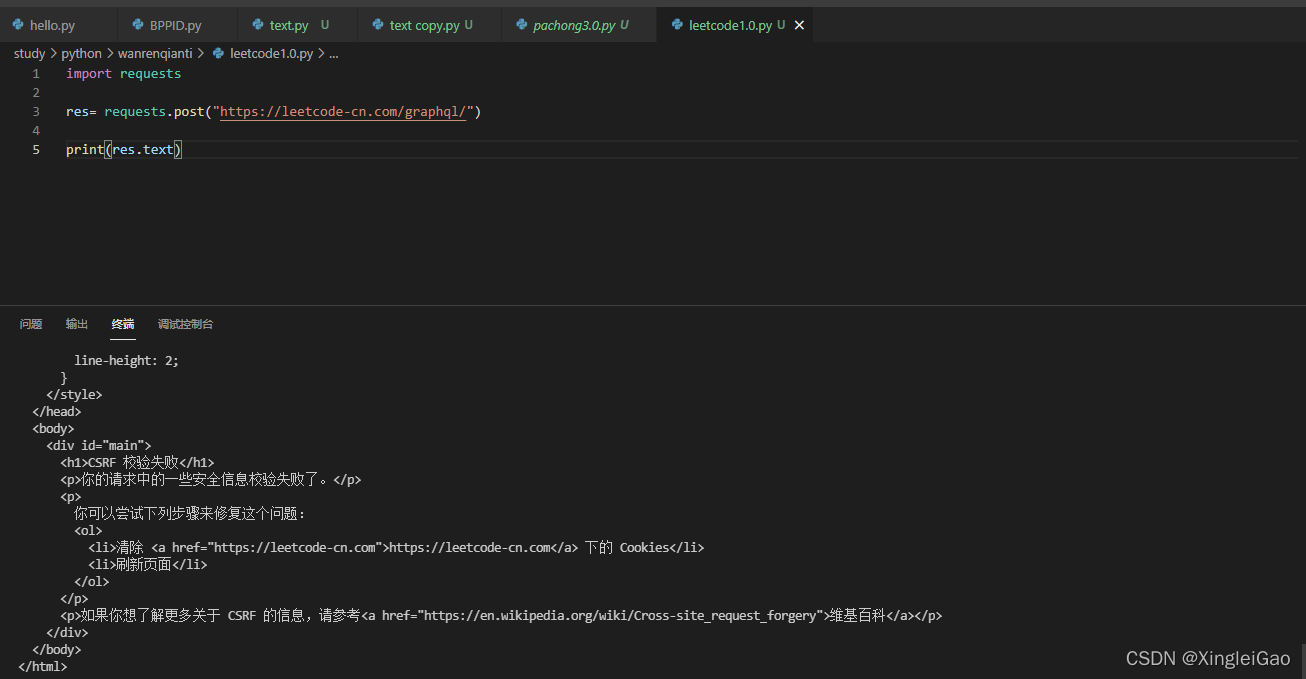
可以发现标头的地址就是https://leetcode-cn.com/graphql/,那我们虎一点直接post一下看看反馈。
上图告诉我们我没没有给他CSRF校验。
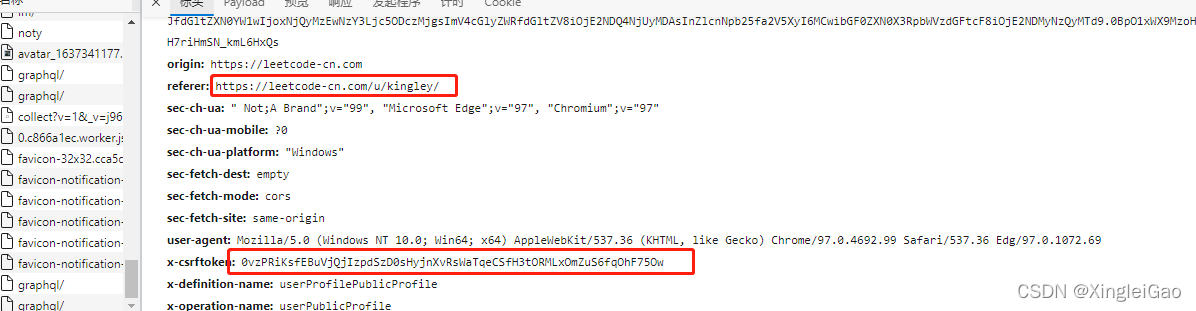
我们正常的请求参数是在这里,其实就是在头部。一般这种网站还需要申请网站信息,所以我们可以将对应的头部信息传给它。
现在我们就成功给到了标头,提示我们传参错误,我们压根没传参,233
2.2确定传输参数
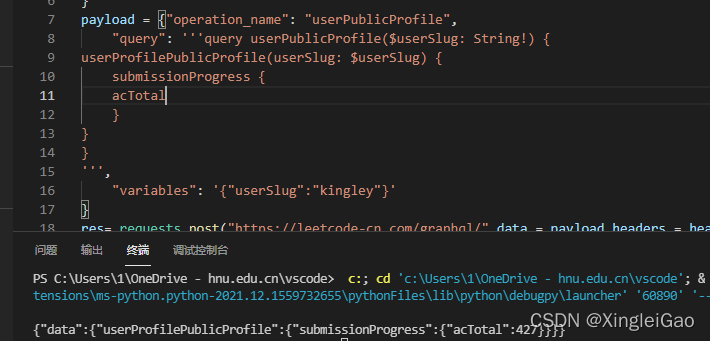
查看payload可以发现主要的传输数据 我们把它拷贝出来作为数据传给对应的网址:
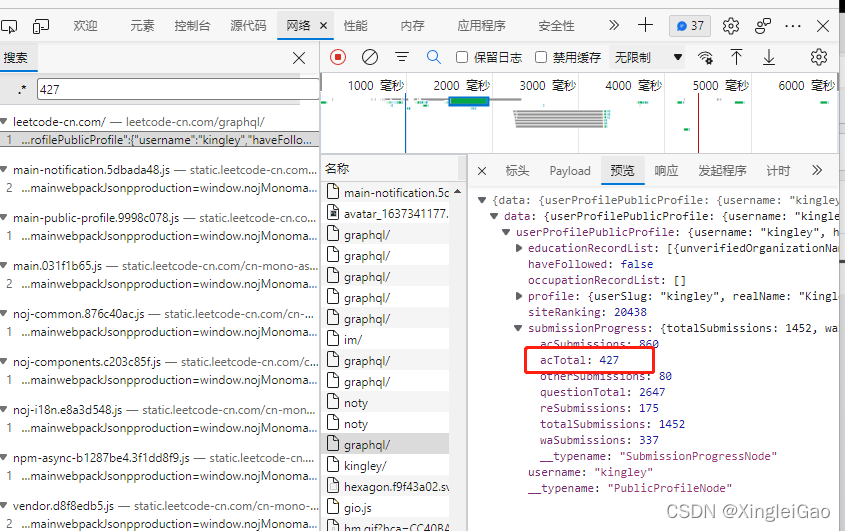

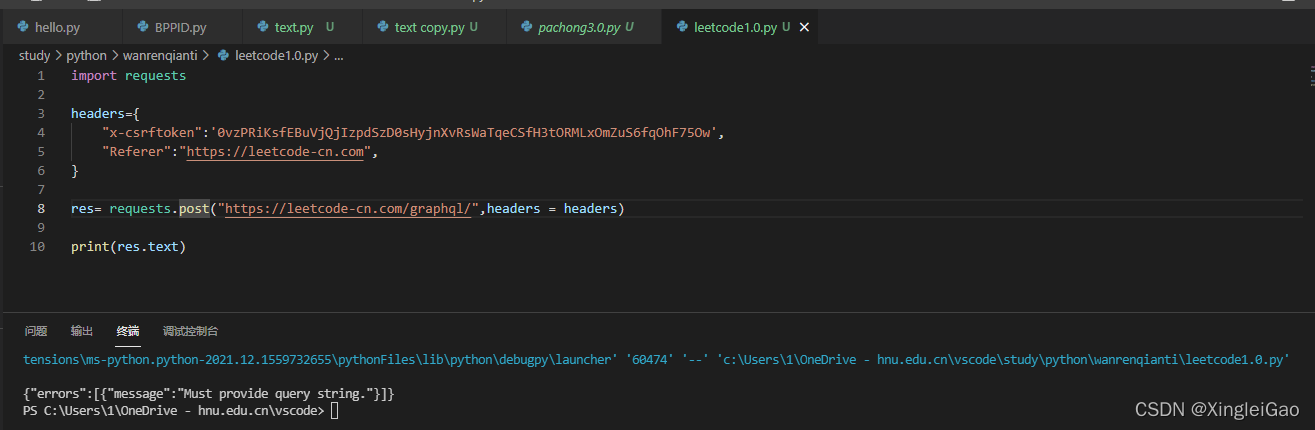
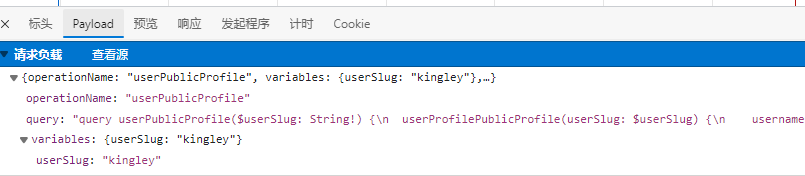
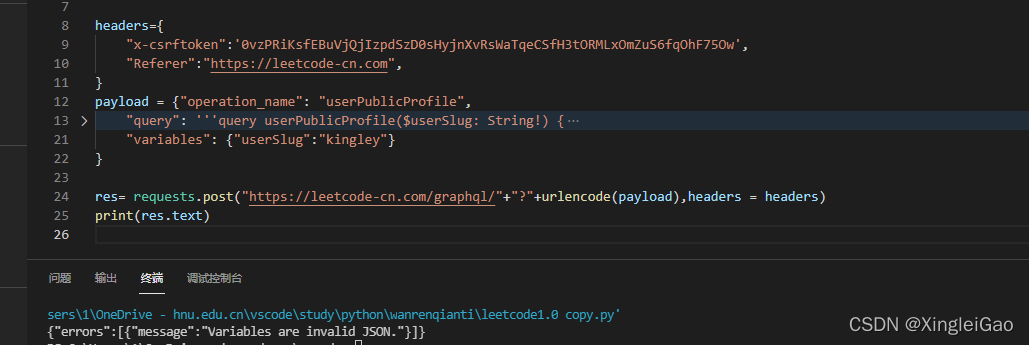
错误信息告诉我
variables不符合要求,啊这???其实是需要把variables的值变成字符串:
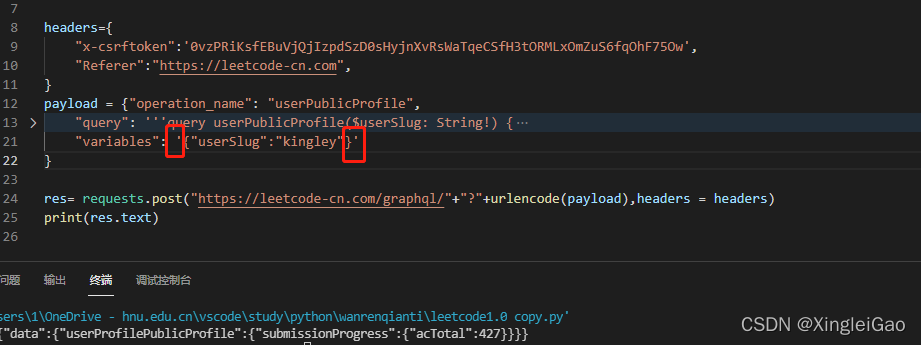
嗯,这就拿到了我们需要的数据,但是这也太复杂了,可以发现查询结果全靠
query字段。我们对它进行一些精简:
在不破坏层级的条件下精简到了极致,返回信息只有我们想要的数据了
我们再修改一下返回数据的值就完美了。
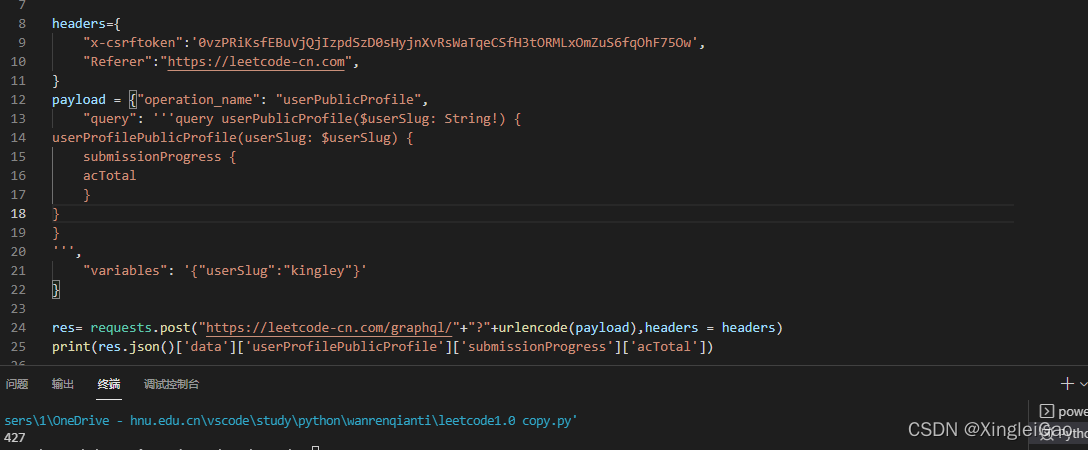
为了方便,我们把根据名字查询信息封装成函数并做验证
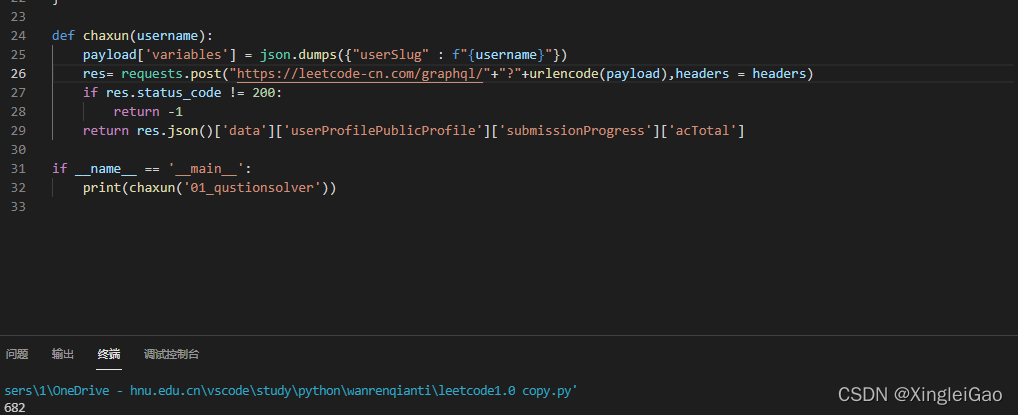
三、数据的读入与查询写回
1.数据读入查询
其实上一次已经完成了相关数据的读入,但是这一次我们只需要用户的名称。所以我们有一点改变。我们读入数据,如果不符合要求直接输出
0
符合要求的我们需要从其中找到用户名,分析链接发现/u/{用户名}/,所以我们可以用正则表达式提取出对应的用户名
此时已经可以输出对应的数据了
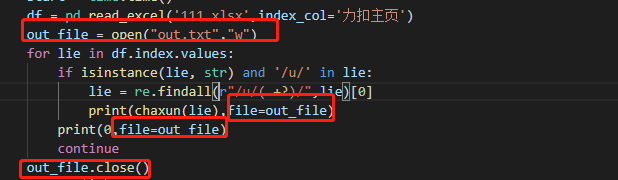
2.数据的写回
一开始为了复制回腾讯文档我直接使用了txt作为输出,很简单:
可以发现在这种情况下,cpu负载极低,速度也有极大的提升,但是我们知道requests是访问网络资源,限制时间的主要问题在于网络等待,所以我们更希望用多线程并发请求来达到提高程序速度的要求。

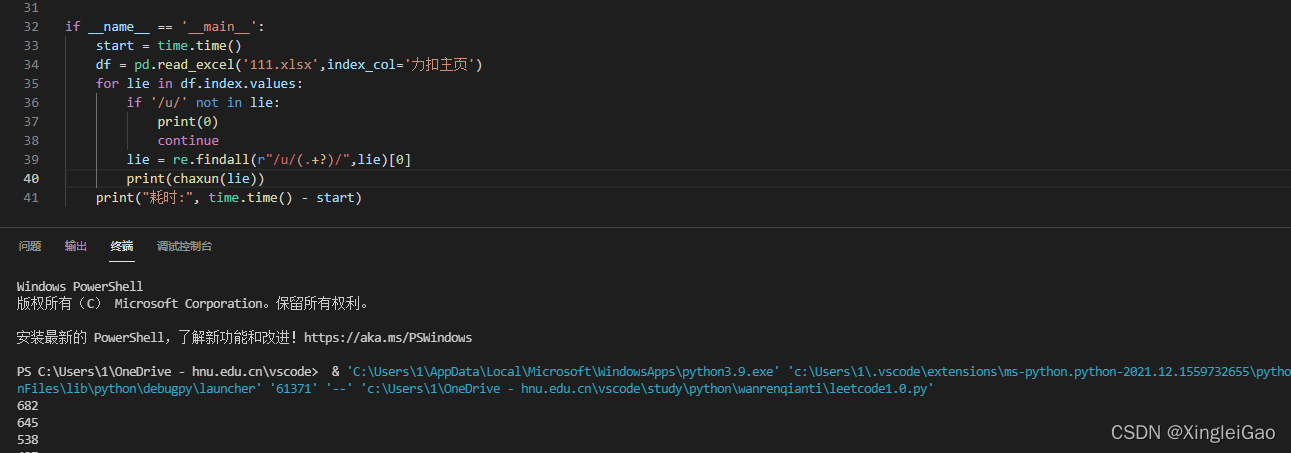

四、多线程请求信息
此处感谢明佬的指导,省了不少麻烦事@小小明-代码实体
首先介绍一下ThreadPoolExecutor线程库:
导入:from concurrent.futures import ThreadPoolExecutor创建线程库:
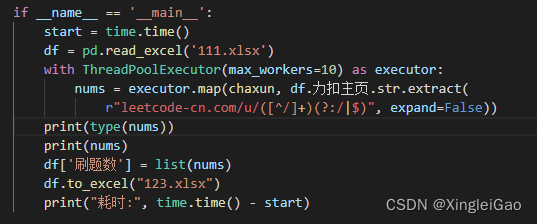
with ThreadPoolExecutor(max_workers=10) as executor:按照次序返回结果,并接收:
nums = executor.map(chaxun, df.力扣主页.str.extract( r"leetcode-cn.com/u/([^/]+)(?:/|$)", expand=False))其中第二个参数就是传入的参数列表,并且
.map可以按照输入顺序进行输出。
我们只要将返回的nums转化为list就可以按之前的顺序得到结果。
整体函数:
耗时:>得到的结果

五、web前端的书写
此处万分感谢明佬的辛勤劳动:@小小明-代码实体
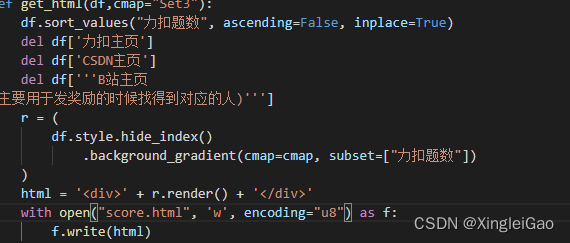
pandas默认是可以直接生成html的文件的,我们稍加修饰就好了1.默认的生成结果:
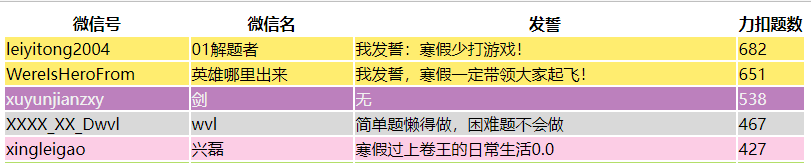
2.改变为整行的颜色显示
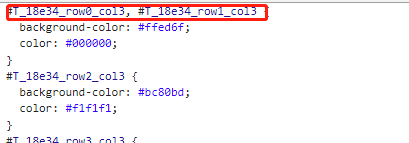
查看生成的样式表,我们需要把对应的值改掉
#T_18e34_row0_col3变成.row0
利用正则表达式进行替换(这里我真的没看懂,还是求救的明佬,明佬yyds!!!)
3.完善样式表
最后再加入自己想要定制的显示方式然后返回对应的html信息就好了。

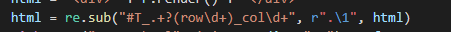
六、其他补充
1.CSRF的获取
requests可以直接获取一个cookie,我们可以从cookies中提取出来
def int_csrf(): global headers sess= requests.session() sess.head("https://leetcode-cn.com/graphql/") headers['x-csrftoken'] = sess.cookies["csrftoken"]
2.web服务器直接写入静态页面地址
可以直接写入对应网页的根目录直接访问,效果可以看手机版万人千题刷题榜单
3.电脑端的呈现页面
电脑和手机的分辨率不同,所以导致显示效果不同,就单独做了一些PC端的页面,使用内嵌的方式来进行数据的浏览。其实就是用ifame做嵌套,做了缩放。
<style> .iframe-body-sty{position: relative;overflow: hidden;height:700px;width: 500px;background-color:#FFF;} .iframe-body-sty>#iframe-shrink{position: absolute;transform:scale(0.43);left: -620px;top: -550px;height:1900px;max-width:1600px;width: 1600px;} </style> <div class="iframe-body-sty"> <iframe id="iframe-shrink" src="https://www.xingleigao.top/score.html"></iframe> </div>最终效果可以看:PC端万人千题刷题榜单
4.数据的定时更新
利用sh进行对应的操作
cd /home/leetcode date >> log.txt python3 leetcode.py >> log.txt 2>&1利用cron进行定时任务
crontab -e


七、写在最后
这次的整个优化流程还算是比较顺利,其中也学到了很多东西,算是从一个啥也不懂的小白写出来的。如有问题还请大家批评指正。奉上完整代码:
"""
兴磊的代码
CSDN主页:https://blog.csdn.net/qq_17593855
"""
__author__ = '兴磊'
__time__ = '2022/1/27'
import pandas as pd
import re
import time
from urllib.parse import urlencode
import requests
import json
from concurrent.futures import ThreadPoolExecutor
headers={
"x-csrftoken":'',
"Referer":"https://leetcode-cn.com",
}
utf = '''
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<script>
var _hmt = _hmt || [];
(function() {
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js?f114c8d036eda9fc450e6cbc06a31ebc";
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();
</script>
'''
payload = {"operation_name": "userPublicProfile",
"query": '''query userPublicProfile($userSlug: String!) {
userProfilePublicProfile(userSlug: $userSlug) {
submissionProgress {
acTotal
}
}
}
''',
"variables": '{"userSlug":"kingley"}'
}
def int_csrf():
global headers
sess= requests.session()
sess.head("https://leetcode-cn.com/graphql/")
headers['x-csrftoken'] = sess.cookies["csrftoken"]
def chaxun(username):
payload['variables'] = json.dumps({"userSlug" : f"{username}"})
res= requests.post("https://leetcode-cn.com/graphql/"+"?"+urlencode(payload),headers = headers)
if res.status_code != 200:
return -1
return res.json()['data']['userProfilePublicProfile']['submissionProgress']['acTotal']
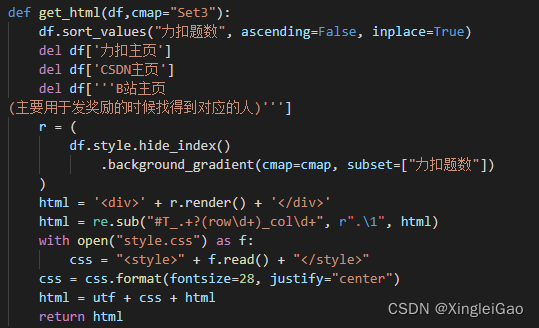
def get_html(df,cmap="Set3"):
df.sort_values("力扣题数", ascending=False, inplace=True)
del df['力扣主页']
del df['CSDN主页']
del df['''B站主页
(主要用于发奖励的时候找得到对应的人)''']
r = (
df.style.hide_index()
.background_gradient(cmap=cmap, subset=["力扣题数"])
)
#print(r.render())
html = '<div>' + r.render() + '</div>'
html = re.sub("#T_.+?(row\d+)_col\d+", r".\1", html)
with open("style.css") as f:
css = "<style>" + f.read() + "</style>"
css = css.format(fontsize=28, justify="center")
html = utf + css + html
return html
if __name__ == '__main__':
int_csrf()
df = pd.read_excel('111.xlsx')
#读取一整列的数据
start = time.time()
with ThreadPoolExecutor(max_workers=10) as executor:
nums = executor.map(chaxun, df.力扣主页.str.extract(
r"leetcode-cn.com/u/([^/]+)(?:/|$)", expand=False))
df['力扣题数']=list(nums)
with open("/www/xxxx/score.html", 'w', encoding="u8") as f:
f.write(get_html(df))
print("耗时:", time.time() - start)
最后,非常感谢明佬!!yyds































 到【灌水乐园】发言
到【灌水乐园】发言









