






- 当相关系数为0时,X和Y两变量无关系。
- 当X的值增大(减小),Y值增大(减小),两个变量为正相关,相关系数在0.00与1.00之间。
- 当X的值增大(减小),Y值减小(增大),两个变量为负相关,相关系数在-1.00与0.00之间。
OK,接下来,咱们来重点了解下皮尔逊相关系数。在统计学中,皮尔逊积矩相关系数(英语:Pearson product-moment correlation coefficient,又称作 PPMCC或PCCs, 用r表示)用于度量两个变量X和Y之间的相关(线性相关),其值介于-1与1之间。通常情况下通过以下取值范围判断变量的相关强度:
相关系数 0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关在自然科学领域中,该系数广泛用于度量两个变量之间的相关程度。它是由卡尔·皮尔逊从弗朗西斯·高尔顿在19世纪80年代提出的一个相似却又稍有不同的想法演变而来的。这个相关系数也称作“皮尔森相关系数r”。
(1)皮尔逊系数的定义 :两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商:
以上方程定义了总体相关系数, 一般表示成希腊字母ρ(rho)。基于样本对协方差和方差进行估计,可以得到样本标准差, 一般表示成r:
一种等价表达式的是表示成标准分的均值。基于(Xi, Yi)的样本点,样本皮尔逊系数是
其中、
及
,分别是标准分、样本平均值和样本标准差。
或许上面的讲解令你头脑混乱不堪,没关系,我换一种方式讲解,如下:假设有两个变量X、Y,那么两变量间的皮尔逊相关系数可通过以下公式计算:
- 公式一:
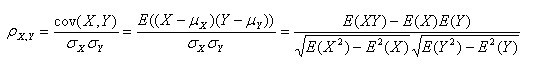
注:勿忘了上面说过,“皮尔逊相关系数定义为两个变量之间的协方差和标准差的商”,其中标准差的计算公式为: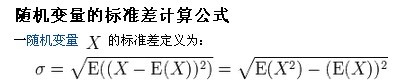
- 公式二:
- 公式三:
- 公式四:
以上列出的四个公式等价,其中E是数学期望,cov表示协方差,N表示变量取值的个数。
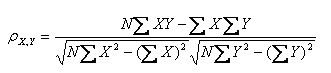
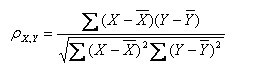
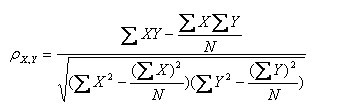
(2)皮尔逊相关系数的适用范围
当两个变量的标准差都不为零时,相关系数才有定义,皮尔逊相关系数适用于:
- 两个变量之间是线性关系,都是连续数据。
- 两个变量的总体是正态分布,或接近正态的单峰分布。
- 两个变量的观测值是成对的,每对观测值之间相互独立。
(3)如何理解皮尔逊相关系数
rubyist:皮尔逊相关系数理解有两个角度
其一, 按照高中数学水平来理解, 它很简单, 可以看做将两组数据首先做Z分数处理之后, 然后两组数据的乘积和除以样本数,Z分数一般代表正态分布中, 数据偏离中心点的距离.等于变量减掉平均数再除以标准差.(就是高考的标准分类似的处理)
样本标准差则等于变量减掉平均数的平方和,再除以样本数,最后再开方,也就是说,方差开方即为标准差,样本标准差计算公式为:
所以, 根据这个最朴素的理解,我们可以将公式依次精简为:
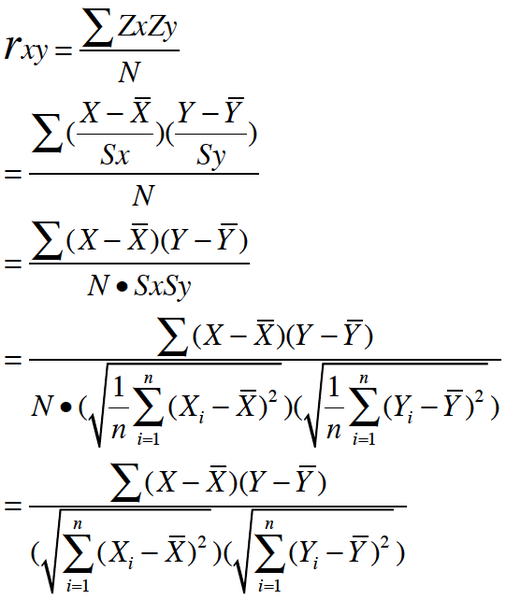
其二, 按照大学的线性数学水平来理解, 它比较复杂一点,可以看做是两组数据的向量夹角的余弦。下面是关于此皮尔逊系数的几何学的解释,先来看一幅图,如下所示:
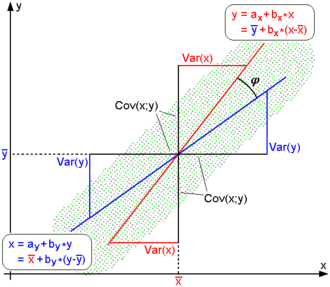
回归直线: y=gx(x) [红色] 和 x=gy(y) [蓝色]
如上图,对于没有中心化的数据, 相关系数与两条可能的回归线y=gx(x) 和 x=gy(y) 夹角的余弦值一致。
对于没有中心化的数据 (也就是说, 数据移动一个样本平均值以使其均值为0), 相关系数也可以被视作由两个随机变量 向量 夹角 的 余弦值(见下方)。
举个例子,例如,有5个国家的国民生产总值分别为 10, 20, 30, 50 和 80 亿美元。 假设这5个国家 (顺序相同) 的贫困百分比分别为 11%, 12%, 13%, 15%, and 18% 。 令 x 和 y 分别为包含上述5个数据的向量: x = (1, 2, 3, 5, 8) 和 y = (0.11, 0.12, 0.13, 0.15, 0.18)。
利用通常的方法计算两个向量之间的夹角 (参见 数量积), 未中心化 的相关系数是:
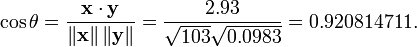
我们发现以上的数据特意选定为完全相关: y = 0.10 + 0.01 x。 于是,皮尔逊相关系数应该等于1。将数据中心化 (通过E(x) = 3.8移动 x 和通过 E(y) = 0.138 移动 y ) 得到 x = (−2.8, −1.8, −0.8, 1.2, 4.2) 和 y = (−0.028, −0.018, −0.008, 0.012, 0.042), 从中
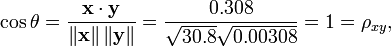
(4)皮尔逊相关的约束条件
从以上解释, 也可以理解皮尔逊相关的约束条件:
- 1 两个变量间有线性关系
- 2 变量是连续变量
- 3 变量均符合正态分布,且二元分布也符合正态分布
- 4 两变量独立
在实践统计中,一般只输出两个系数,一个是相关系数,也就是计算出来的相关系数大小,在-1到1之间;另一个是独立样本检验系数,用来检验样本一致性。
K值的选择
除了上述1.2节如何定义邻居的问题之外,还有一个选择多少个邻居,即K值定义为多大的问题。不要小看了这个K值选择问题,因为它对K近邻算法的结果会产生重大影响。如李航博士的一书「统计学习方法」上所说:
- 如果选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
- 如果选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
- K=N,则完全不足取,因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的累,模型过于简单,忽略了训练实例中大量有用信息。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









