






百度百科的官方解释:宽度优先搜索算法(又称广度优先搜索)是最简便的图的搜索算法之一,这一算法也是很多重要的图的算法的原型。Dijkstra单源最短路径算法和Prim最小生成树算法都采用了和宽度优先搜索类似的思想。其别名又叫BFS,属于一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。换句话说,它并不考虑结果的可能位置,彻底地搜索整张图,直到找到结果为止。
这是一个很难硬说就能理解的知识点,但是理解了就会觉得很简单(事实上所有知识点都是这样),配图理解BFS。
假设有这么一个图,1是起点,5是终点。
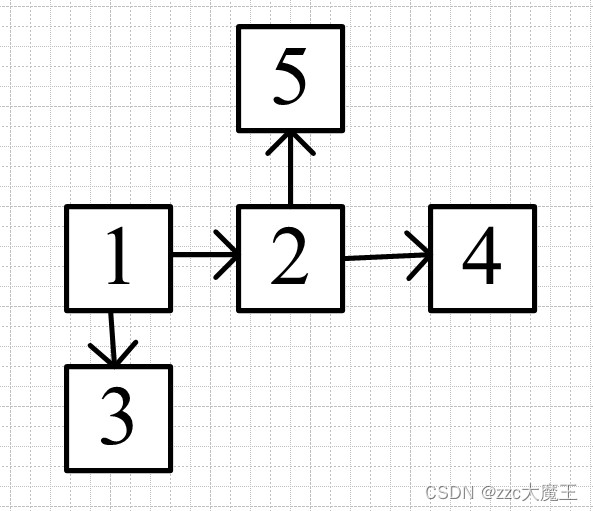
遍历时将1首先加入队列(队列就是模拟BFS用的,栈是模拟DFS用的,应用的是队列先进先出和栈先进后出的特性)
然后应用一个循环模板
while(队列不为空){
弹出队头
遍历队头接下来的节点
将满足的节点加入队列
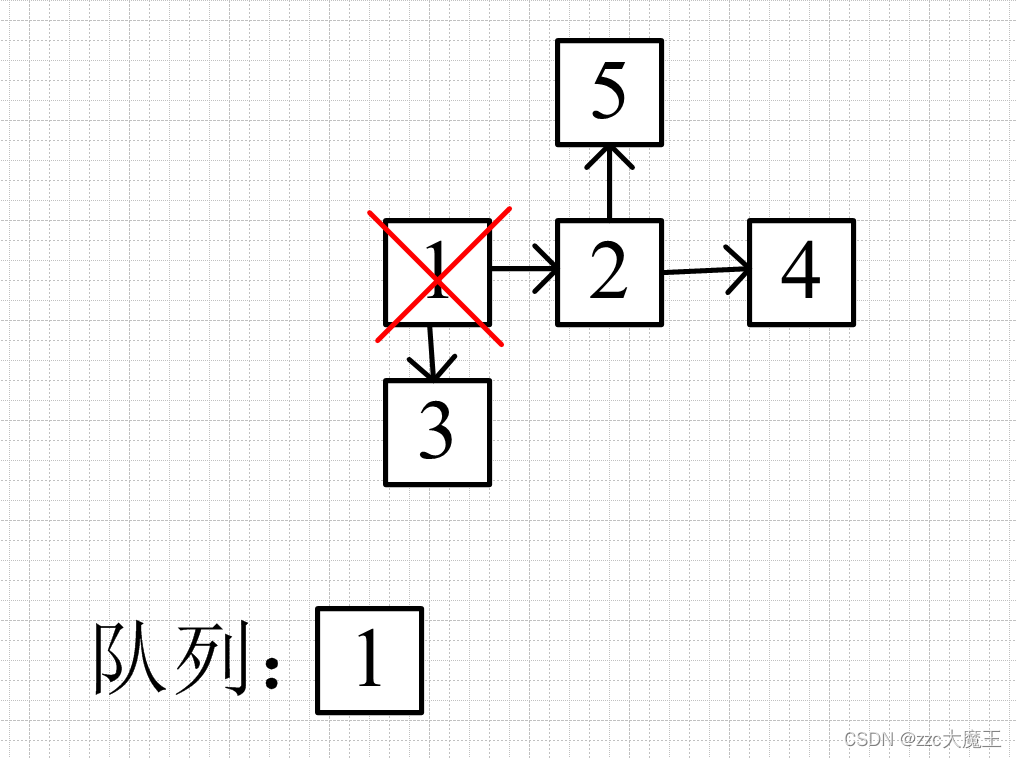
}模拟while过程,将1弹出队列,遍历1相连的节点,将满足条件的加入队列(这里不设条件)
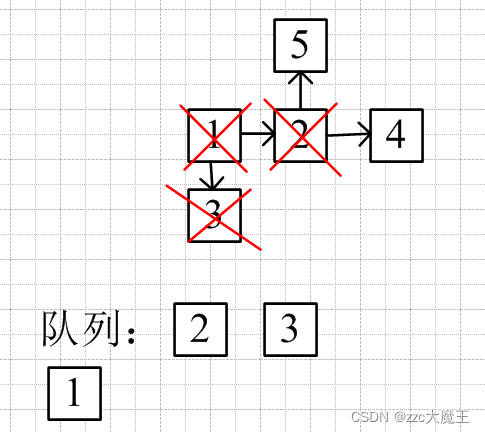
弹出队头节点3,遍历与3相连的节点,与3连接的节点进队列(这里没有与3相连的),一直是从2的左边进入(即队尾进入),所以无论如何下一次都是先遍历与2相连的节点
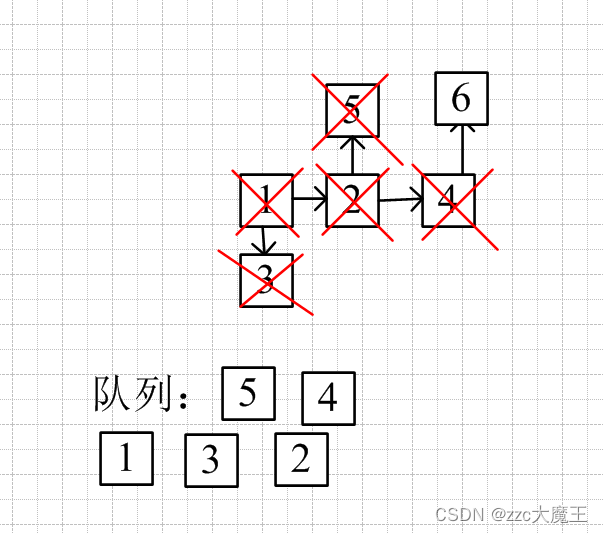
比如在节点4后有一个相连的6,弹出4,加入6

但下一次的队头就是5了,而不是加入的6
这就是bfs,所有起点同步进行(类似同心圆向外扩散)
这里就会出现一个问题:如果每一个入队列的节点遍历之后都能带来接下来四个满足条件的节点,那么每一次遍历,队列就会扩大四倍,有一个比较简单的方法是引用双向广搜
双向广搜:将起点和终点同时加入队列,两边同时遍历,当两个节点的下一步有相交的节点,就是最短路径或者最短时间。
优化的部分可以看此图

红色部分是单向搜索比双向搜索多出来的部分,优化空间很大,同时也优化了时间
代码模板可变性很高,下面的看个乐就行了(毕竟bfs还是用处挺广泛的)
如果用queue模板的话记住front才是队头,如果遍历是用back就错了,因为pop弹出的front
#include "iostream"
#include "queue"
using namespace std;
struct Node{
int x;
int y;
}startNode,endNode;
int main(){
queue<Node>bfs;
bfs.push(startNode);
while(!bfs.empty()){
Node tempNode=bfs.front();
int x=tempNode.x;
int y=tempNode.y;
bfs.pop();
Node nextNode;
if(check(x+1,y)){//check是当这个条件成立时的随意一个函数,如果是迷宫
nextNode.x=x+1;//只要x+1,y这个位置不是墙壁就加入队列
nextNode.y=y;
bfs.push(nextNode);
}
if(check(x-1,y)){
nextNode.x=x-1;
nextNode.y=y;
bfs.push(nextNode);
}
if(check(x,y-1)){
nextNode.x=x;
nextNode.y=y-1;
bfs.push(nextNode);
}
if(check(x,y+1)){
nextNode.x=x;
nextNode.y=y+1;
bfs.push(nextNode);
}
}
}













 1109
1109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









