







Stacking使得一切更容易:StackNet介绍-比赛大神Marios Michailidis (KazAnova)
你可能听说过一句话:三个臭皮匠赛过诸葛亮。是的,通过组合各种机器学习模型方法会得到更好的结果,这种方法被应用于机器学习中。如果你经常参加kaggle比赛,你也可能知道这种这种方法---stcking,这种方法已经成为了在kaggle比赛中名列前茅的选手常用的一种主要技术方法。
这个博文,Marios Michailidis (AKA Competitions Grandmaster KazAnova on Kaggle)[1]给了stacking很多详细地介绍,包括kaggle比赛中如何使用它去提升排名,神经网络的复苏如何导致stacking模型的产生,StackNet。Michailidis也在里面去分享了怎样使用StackNet-计算的、可伸缩的、分析的、meta-modeling框架—工具包的一部分,并解释为什么机器学习者在他们的工作中不应该总是回避复杂的解决方案。
Stacking和StackNet综述
问:你能简单地介绍一下Stacking的概念,并解释一下为什么它如此地重要?
答:Stacking (or Stacked Generalization)使用留出法(holdout)数据去结合各自各样的机器学习算法的过程。它首先提出来是Wolpert在1992年的时候[3]。它通常包括四个步骤。假设有三个数据集A, B, C。对于数据集A, B,我们知道其预测结果y,而C是未知的。具体操作如下:
1、我们在数据集A中训练各自各样的机器学习算法(回归或者分类),其中每个算法在A中要达到最好的效果。
2、我们使用每一种算法对数据集B, C做预测,得到新的数据集B1和C1(这些新的数据集由数据集B, C的预测得到的结果组合而成)。所以说,如果我们运行10个机器学习模型,将会在B1和C1中得到含有10列(维度)的数据集。
3、我们用第2步得到的数据集B1作为训练集去训练另外一种新的机器学习算法,通常被称作Meta learner或者Super learner。
4、我们使用第2步的数据集C1作为测试集去测试Meta learner的泛化能力。

对于拥有一个特别大的scale去实现stacking,一种更常读或者常用的方法,stacked ensembles[4].
Stacking如此的重要是因为在能够在各自各样的机器学习问题里面使得结果得到提高。我相信在过去4年的kaggle比赛里面获胜队伍有一部分都是用来stacking。
而且,随着计算机计算能力的提升和并行技术的完善使得很多方法可以一起运行。大多数算法依赖确切的参数或者假设其表现效果最好,因此每一种算法都有各自的优缺点。stacking是一种机制,它试图利用每种算法的优点,而不考虑(在某种程度上)或纠正它们的缺点。在大多数抽象的形式里面,stacking能够被认为一种纠正算法错误的机制。
问:Great,那么什么是StackNet呢?
答:StackNet是一种计算性的、可扩展的、分析性的meta-modeling框架,它在Java中实现,它类似于前后向的神经网络,并使用Wolpert的多层stacked gengeralization来提高机器学习预测问题的准确性。
StackNet是KazAnova在UCL[5]的博士学位的一部分,由dunnhumby[6]赞助。可以从GitHub[7]上下载:
StackNet大概可以分为如下几个基本性能:
1、Computational拥有很强的计算能力
2、Scalable多个模型能够被并行运行,多线程将会使得结果更快
3、Analytical很大程度上基于数据分析(或数据科学)的原理,特别是当涉及到数据预处理、交叉验证、通过各种度量来度量性能的时候。
4、Meta-modelling引入meta learners的概念。换句话说,它将一些算法的预测输出作为其他算法的输入特征。
5、Wolpert’s stacked generalization因为meta-learners是用在hold-out 数据集中的预测结果组合技术来创建。
6、Feedforward neural network and multiple levels Stacking并不限于stacking部分这个四个阶段,而是它能够在预测中重复多次创造更多的数据集,比如B2,C2直到Bn,Cn。
7、Java最先将StackNet实现的程序语言是java
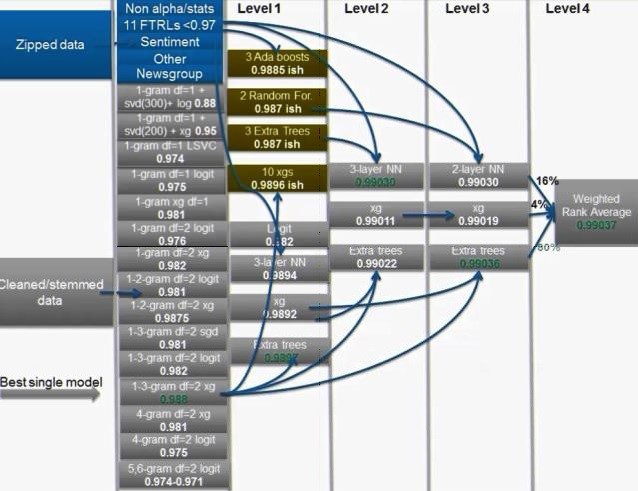
StackNet过去在机器学习挑战中获得了比较好的结果。一种经典的应用可以参见the winning solution of the Truly Native Kaggle challenge[8]。在这次比赛中, StackNet有4个meta(neuron)模型层去取得佳绩。最终的结构如下所示:
典型的神经网络通常用反向传播去训练;然而,stacked generalization-如前所述-需要前向训练技术将数据分成两部分(A和B)-A部分用作训练,B部分用作预测。
之所以将数据分开是为了防止过拟合。然而,将数据分成两部分就意味着,在第二部分的每一个新层中,都需要进一步的二分法,换句话说需要更多的数据集(D, F…, Z)。这就增加了过度拟合的偏差,因为每个算法都需要在越来越少的数据上进行训练和验证。
为了克服这个过拟合的偏差增加问题,我们采用k折交叉验证,这里k是一个超参数。这个过程意味着我们分割数据K次并运行模型来输出每个K部分的预测,然后将K个部分重新组合到原始的顺序,这样输出预测就可以在模型的后期使用。具体过程如下如所示:
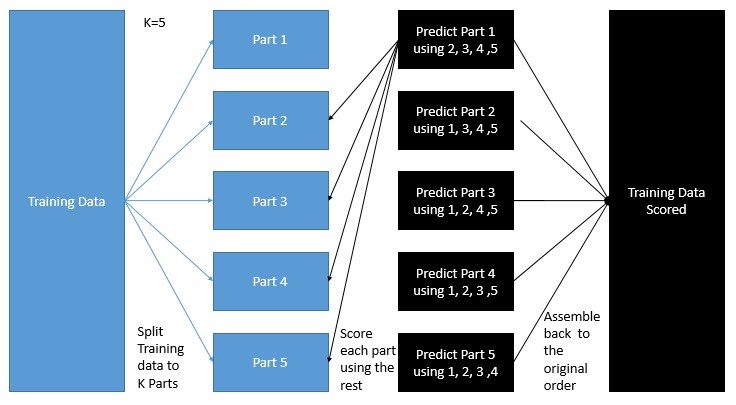
我们可以选择在整个训练数据上训练另一种算法(K-fold之后),而不是同时预测每个K模型的测试数据。这里,没有理由限制模型使用少于100%的训练数据进行学习的能力,因为输出评分已经是无偏的。
问:我还是搞不懂—为什么在不同的层次上建立这么多模型会有帮助呢?除了它们看起来“丑陋”。我更喜欢建立一个好模型。
答:因为没有哪个模型是完美的。这些模型每次绝大多数都会产生误差,再加上每个模型都有各自的优缺点,它们更倾向于将数据变型不同形状。利用每个模型的唯一性是构建具有预测性的模型的关键所在。
我经常用下面例子来尽可能简单地解释多层stacking:
假设这里有三个学生LR, SVM, KNN,他们在一个物理问题上争论他们对正确答案有不同的看法:

他们决定没有办法说服彼此,于是乎他们决定取他们的平均估计值,也就是14。这里,他们使用了一种最简单的集合形式—即平均模型。
他们的老师DL小姐,一位数学老师,见证了学生们的争论,并决定帮助他们。她问:问题是什么?但学生们拒绝告诉她(因为他们知道提供所有的信息对他们没有好处,而且他们认为她可能会觉得自己在为这样一件小事争论有些傻)。但是他们告诉她这是一个与物理问题有关的答案。
在这种情况下,教师不能知道初始数据,正如她不知道具体的原始问题是什么。但是她非常了解学生们的长处和短处,所以她认为她可以帮助学生们解决这个问题。她使用学生在过去所做的历史信息,即对于问题各自的答案,以及她知道SVM热爱物理,而且她的父亲在一个物理研究所优秀青年科学家。所以她认为最合适的答案是更可能是17。
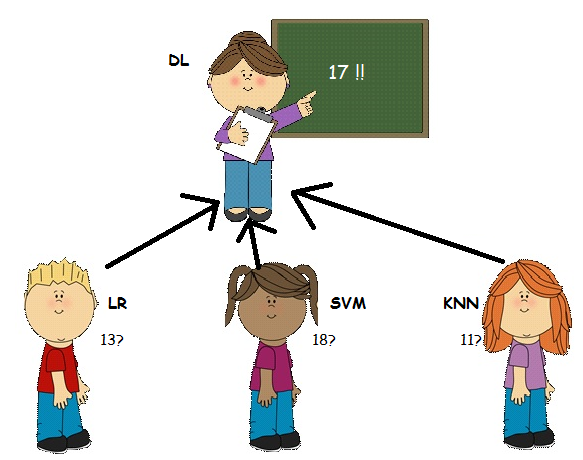
在这种情况下,教师(DL)是meta learner。她将其他模型(学生)的输出结果作为输入数据。然后她将这些输入的结果与历史信息(学生们在过去的学习情况)结合起来,以获得更好的评估(并帮助解决学生们之间的冲突)。
然而, RF先生作为一名物理老师有一个稍微不同的观点。他一直在那里,但他一直等到这一刻才开始行动。RF先生最近一直在教授LR物理的私人课程以提高他的成绩(这是DL女士不知道的),他认为LR对最终估计的贡献应该更大。因此他声称正确的答案可能是16。
在这种情况下,RF先生也是meta learner,他使用不同的历史数据,而且他还知道比DL女士关于这个物理问题更多的信息(或不同的历史信息)。
最后只有当GBM校长做出决定时,这个争议才能得到解决。虽然GBM不知道孩子们说了什么(物理问题和各自的物理观点答案),但是他很了解他的老师,他更喜欢相信他的物理老师(RF),他得出的结论可能为16.2。
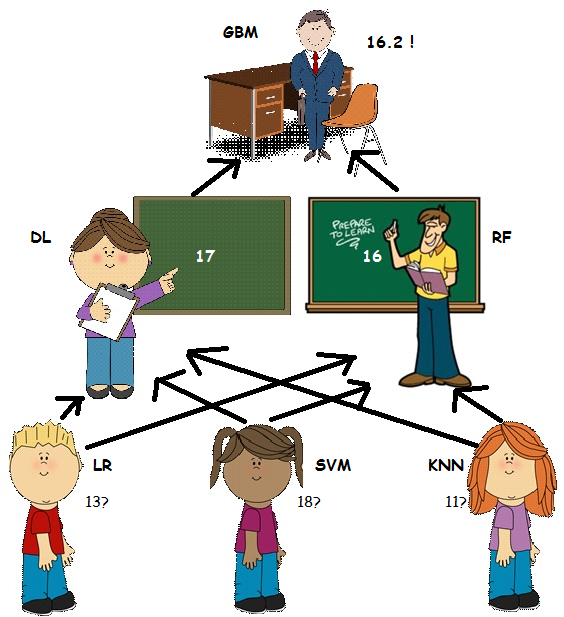
在这种情况下,校长是一个leve 2 meta learner 或者meta learner of meta leaners,通过处理他的老师的历史信息,他可能仍然能够提供比简单的平均结果更好的估计。
参考文献
[1] https://www.kaggle.com/kazanova
[2] https://www.kaggle.com/general/34802
[3] http://www.machine-learning.martinsewell.com/ensembles/stacking/Wolpert1992.pdf
[4]https://h2o-release.s3.amazonaws.com/h2o/rel-ueno/2/docs-website/h2o-docs/data- science/stacked-ensembles.html
[5] http://www.cs.ucl.ac.uk/home/
[6] https://www.dunnhumby.com/
[7] https://github.com/kaz-Anova/StackNet
[8] http://blog.kaggle.com/2015/12/03/dato-winners-interview-1st-place-mad-professors/














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









