






“WebMagic 是一个简单灵活的 Java 爬虫框架,基于 WebMagic,你可以快速开发出一个高效、易维护的爬虫程序。
你可以直接去官网查看说明文档(http://webmagic.io/),也可以跟随本文,一步一步地实现一个简单的知乎答案图片下载爬虫程序。
”
1. 新建 Maven 项目
在 Intellij Idea 中新建一个基于 Maven 的 Module,如果你不清楚怎么新建项目,可以参考 如何新建基于 Maven 的 Module(http://t.cn/R9culOI) ,确保你新建好的项目能正确运行。
2. 添加依赖,编写代码
在你的 pom.xml 文件中,加入 WebMagic 的依赖,我使用的是最新版的:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.2</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.2</version>
</dependency>
新建一个 ZhihuPictureSpider.java 类,类的内容:
package com.zhaoyh.main;
import com.zhaoyh.utils.DownloadUtils;
import com.zhaoyh.utils.ValidatorUtils;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
/**
* Created by zhaoyh on 2017/07/31.
* 知乎图片下载
*/
public class ZhihuPictureSpider implements PageProcessor {
private String basePath = null;
private static String z_c0 = null;
private static Site site = Site.me().setRetryTimes(5).setSleepTime(5000).setTimeOut(5000)
.addCookie("Domain", "zhihu.com")
.addCookie("z_c0", z_c0)
.setUserAgent("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.89 Safari/537.36");
/**
* 开始处理
* @param page
*/
public void process(Page page) {
List<String> urlList = page.getHtml().xpath("//div[@class=RichContent-inner]//img/@data-original").all();
String questionTitle = page.getHtml().xpath("//h1[@class=QuestionHeader-title]/text()").toString();
System.out.println("问题题目:" + questionTitle);
List<String> picUrlList = new ArrayList<String>();
for (int i = 0; i < urlList.size(); i = i + 2) {
String url = urlList.get(i);
if (ValidatorUtils.isLegalUrl(url)) {
picUrlList.add(urlList.get(i));
}
}
System.out.println("图片个数:" + picUrlList.size());
try {
downLoadPics(picUrlList, questionTitle, this.basePath);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 下载图片
* @param imgUrls
* @param title
* @param filePath
* @return
* @throws Exception
*/
private static boolean downLoadPics(List<String> imgUrls, String title, String filePath) throws Exception {
boolean isSuccess = true;
//标题
String storagePath = filePath + File.separator + title;
File fileDir = new File(storagePath);
if (imgUrls.size() > 0 && !fileDir.exists()) {
fileDir.mkdirs();
}
int i = 1;
//循环下载图片
for (String imgUrl : imgUrls) {
System.out.println("开始下载下载 " + imgUrl + " " + i);
String ext = imgUrl.substring(imgUrl.lastIndexOf(".") + 1);
String fullPath = storagePath + File.separator + "pic_" + System.currentTimeMillis() + "_" + i + "." + ext;
DownloadUtils.downloadPictureFromUrl(imgUrl, fullPath);
i++;
}
return isSuccess;
}
/**
* 获取站点
* @return
*/
public Site getSite() {
return site;
}
public void setBasePath(String basePath) {
this.basePath = basePath;
}
public static void main(String[] args) {
//配置
String z_c0 = "XXXXXXX";
String basePath = "XXXXX";
String answerUrl = "XXXXX";
//初始化
ZhihuPictureSpider.z_c0 = z_c0;
ZhihuPictureSpider zhihuProcessor = new ZhihuPictureSpider();
zhihuProcessor.setBasePath(basePath);
//启动
Spider spider = Spider.create(zhihuProcessor);
spider.addUrl(answerUrl);
spider.thread(2);
spider.run();
}
}
3. 写入配置并启动
在 ZhihuPictureSpider.java 类的 main 方法,前三行是你需要配置的内容,其中
“String z_c0 = "XXXXXXX";
”
是你登陆状态下知乎的 Cookie,如果你不知道怎么查找这个 Cookie 的内容,可以打开你的知乎首页,然后点击 chrome 浏览器的如下图的位置: 然后找到你的该 Cookie 的 Value:
然后找到你的该 Cookie 的 Value:
其次配置好你的图片存储目录,填上你常用的目录即可。
“String basePath = "XXXXX";
”
最后是找到知乎你感兴趣的某个回答,或者某个链接,填入到:
“String answerUrl = "XXXXX";
”
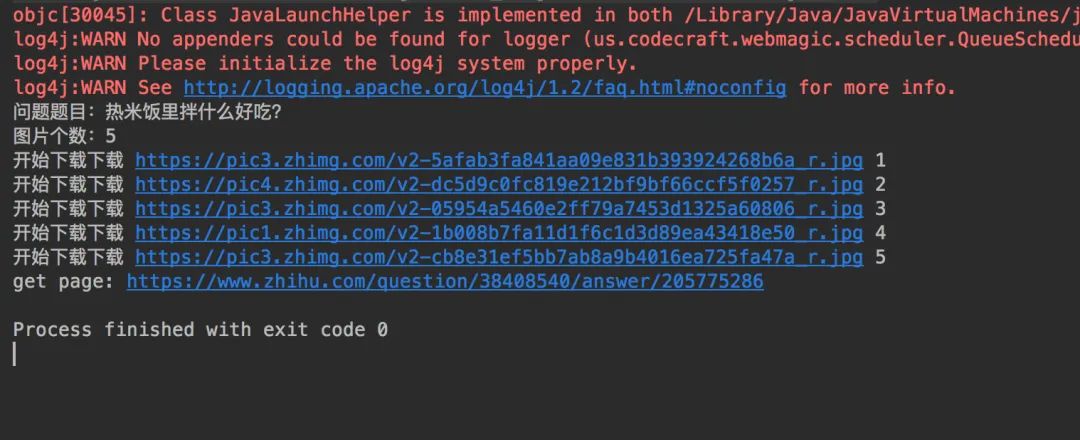
以上你就完成了第一个爬虫程序的所有配置步骤,右击点击 run 即可查看运行效果,下图是我本地的运行效果:
代码下载
“github地址:
https://github.com/chadwick521/SpiderProgram
”
作者:zhaoyh
来源链接:
http://zhaoyh.com.cn/2017/07/31/%E5%9F%BA%E4%BA%8EWebMagic%E7%9A%84%E7%88%AC%E8%99%AB%E5%AE%9E%E7%8E%B0-%E4%B8%80/#more















 1142
1142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









