







JavaWeb学习笔记
网络基础
HTTP协议
HTTP请求
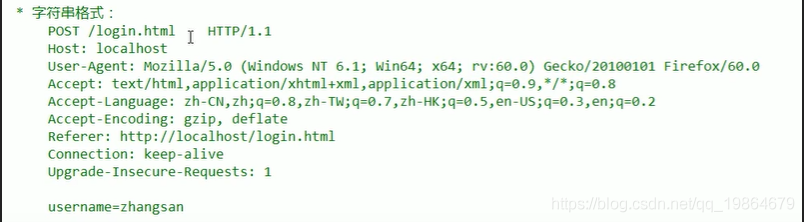
请求数据格式(请求行+请求头+空行+请求体(POST才有))
请求行
请求方式 请求URL 请求协议/版本
GET /logoin.html HTTP/1.1
请求方式:
HTTP一共7种请求方式,常用的两种:
GET:
1. 请求的参数在请求行中,在url后面
2. 请求的url长度有限制
3. 不太安全
POST:
1. 请求的参数在请求体
2. url长度没有限制
3. 相对安全
请求头:客户端告诉服务器一些信息
格式:
请求头名称:请求头值
常见请求头:
User-Agent:浏览器告诉服务器,我访问你使用的浏览器版本信息
Accept:告诉服务器,我可以接收并解析哪些响应的信息格式
Accept-Language:可以接收的语言环境
Accept-Encoding:可以接收的压缩格式
Referer:告诉服务器,请求从哪里来
作用:
防盗链:防止别人盗取该资源
统计工作:
Connection:连接方式
请求空行
空行,用来分割请求头和请求体
请求体(正文)
封装POST请求消息的请求参数
HTTP响应
响应数据格式(响应行+响应头+空行+响应体)
响应行
1. 组成:协议/版本 响应状态码 状态码描述
2. 相应状态码:服务器告诉客户端浏览器本次请求和响应的一个状态
3. 状态码都是3位数字:
1. 1xx:服务器接收客户端消息,但没有接收完成,等待一段时间后,发送1xx状态码。
2. 2xx:成功。代表:200。
3. 3xx:重定向。代表:302(重定向),304(访问缓存)。
4. 4xx:客户端错误,代表:404(请求路径没有对应的资源),405(请求方式服务器没有对应的方法)。
5. 5xx服务端错误,代表:500(服务器内部出现异常)
响应头:
1. 格式(头名称:值)
2. 常见的响应头:
1. Content-type:服务器告诉客户端本次响应体数据格式以及编码格式 。
2. Context-Length:响应字节长度
3. Content-disposition:服务器告诉客户端以什么格式打开响应体数据。
4. in-line:默认值,在当前页面内打开。
5. attachment:以附件形式打开响应体(文件下载)。
响应空行
空行,用来分割响应头和响应体
响应体:传输的数据
会话技术
1. 会话:一次会话中包含多次请求和响应
2. 一次会话:浏览器第一次给服务器资源发送请求,会话建立,知道有一方断开为止。
3. 功能:在一次会话范围内的多次请求间,共享数据
4. 方式:
1. 客户端会话技术:Cookie
2. 服务器端会话技术:Session
Cookie(客户端会话技术)
1. 概念:客户端会话技术,将数据保存到客户端,同一个会话内的请求头和响应头会带上Cookie。
2. 使用步骤:
new Cookie(String name,String value);
response.addCookie(Cookie cookie);
Cookie[] request.getCookies();
3.Cookie 在浏览器中的保存时间
1.默认情况下,当浏览器关闭后,Cookie数据被销毁。
2.持久化存储:
setMaxAge(int seconds):
1.正数:将Cookie数据写到硬盘里的文件中,持久化存储,cookie存活时间。
2.负数:默认值。
3.零:删 除cookie信息。
4.cookie的共享
1.如果一个tomcat服务器有多个web项目,不同web项目中的cookie能不能共享?
1.默认情况下不能。
2.setPath(String path):设置cookie的获取范围,默认情况下,是当前项目的虚拟目录。
3.如果要共享,则可以设置获取范围为项目的根目录:"\"。
2.不同的tomcat服务器间cookie共享
setDomain(String path):如果设置一级域名,那么多个服务器之间cookie可以共享。
例如
setDomain(".baidu.com");
那么tieba.baidu.com和news.baidu.com中的cookie可以共享
5.Cookie的特点和作用
1.特点
cookie存储数据在客户端浏览器
浏览器对于单个cookie的大小有限制(大多数情况下是4KB),以及对同一个域名下的总cookie数量也有限制(大多数情况下是20个)。
2.作用
1.cookie一般用于存储少量不太敏感的数据。
2.在不登陆的情况下,完成服务器对客户端的身份识别(如对网站的一些个性设置)。
3.记录你上次访问该网站的访问时间。
Session(服务器端会话技术)
1. 概念:服务器会话技术,再一次会话的多次请求间共享数据,将数据保存在服务器的对象中(HttpSession)。
2. 快速入门:
1. 获取Session:HttpSession request.getSession();
2. 使用HttpSession对象:
1. Object getAttribute(String name)
2. void setAttribute(String name,Object value)
3. void removeAttribute(String name)
3. 原理:
1. Session的实现是依赖于Cookie的!!!
2. 第一次获取Session,没有Cookie,会在内存中创建一个新的Session对象,在响应头里面带上这个Session的id:
//响应头带上Session的id
set-cookie:JSESSIONID=Session对象的id
3. 当再次发起请求时,请求头的Cookie就会带上Session对象的id:
cookie:JSESSIONID=Session对象的id
4. 细节:
1. 当客户端关闭后,服务器不关闭,两次获取的session是否为同一个?
1. 默认情况下不是,因为cookie里面没有session的id了。
2. 期望客户端关闭后,session也能相同:
HttpSession session = request.getSession();
//创建Cookie
Cookie c = new Cookie("JSESSION",session.getId()));
c.setMaxAge(60*60);
response.addCookie(c);
2. 当客户端不关闭,服务器关闭后,两次获取的session是同一个吗?
不是同一个,但是要确保数据不丢失
1. session的钝化:
在服务器正常关闭之前,将session对象序列化到硬盘上
2. session的活化:
在服务器启动之后,将session文件转化为内存中的session对象即可。
3. 在idea里面部署的tomcat可以自动实现session的钝化,但是不能实现session的活化,如果我们手动部署tomcat服务器,将
项目打包成war放入tomcat的webapps里面,就能自动实现session的钝化和活化。
5. session什么时候被销毁:
1. 服务器关闭
2. session对象调用invalidate();
3. session默认失效时间:30分钟,可以在web.xml里面修改默认时间
6. session的特点
1. session用于存储一次会话(会话域)的多次请求的数据,存在服务器
2. session可以存储任意类型,任意大小的数据
7. Session和Cookie的不同点
1. session存储数据在服务端,Cookie在客户端
2. session没有数据大小限制,Cookie有
3. session数据安全,Cookie相对于不安全
Servlet、Filter和Listener
Servlet
Servlet执行原理(现在不这么用了,不过还是要理解)
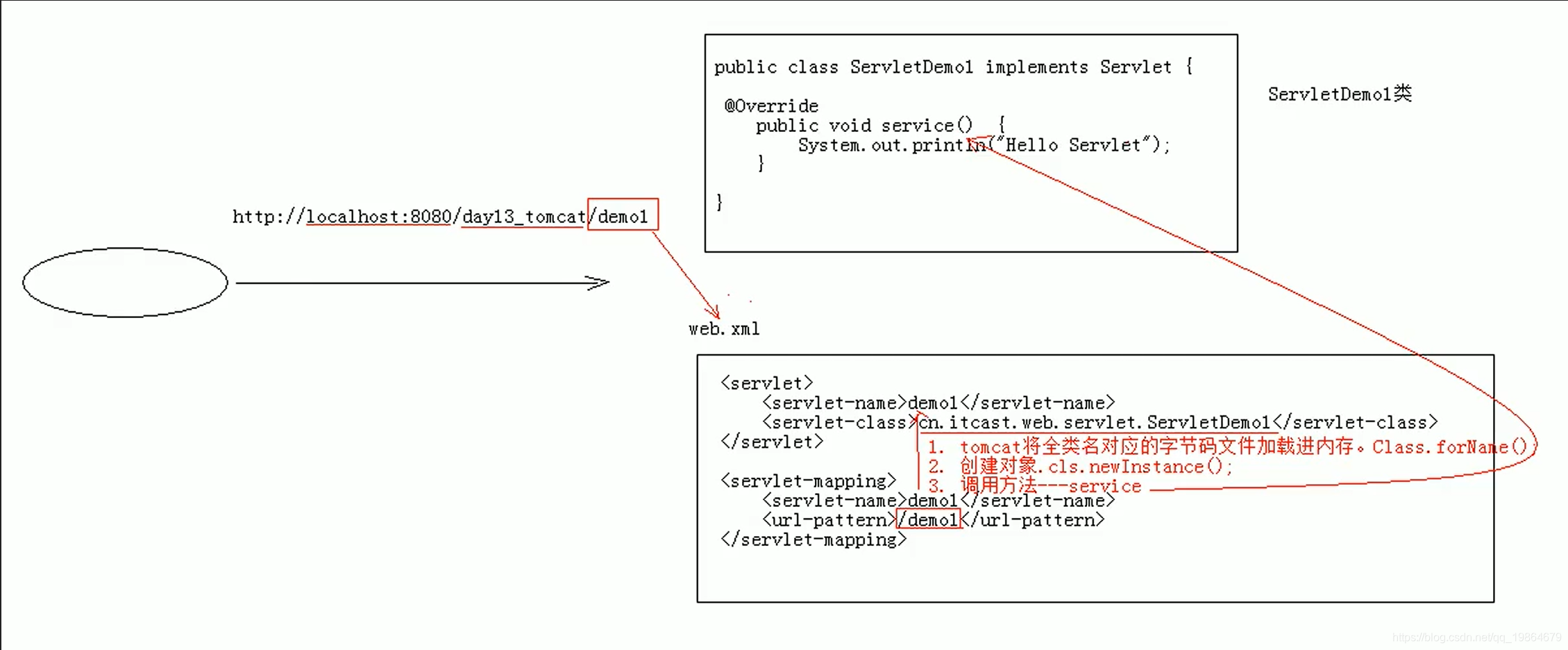
Servlet的体系结构和相关配置

Request对象的常用功能:
- 获取请求消息数据
-
获取请求行数据:
- 获取请求方式:String getMethod()
- 获取虚拟目录:String getContextPath()
- 获取Servlet路径:String getServletPath()
- 获取GET方式的请求参数:String getQueryString()
- 获取请求URI:
- String getResquestURI()
- String getResquestURL()
- 获取协议版本:getProtocol()
- 获取客户机的IP地址:String getRemoteAddr()
-
获取请求头数据
- String getHeader(String name):根据请求头的名称获取请求头的值
- Enumeration getHeaderName():获取所有的请求头名称
-
获取请求体数据
- 只有POST请求方式,才会有请求体,在请求体中封装了了POST请求体的请求参数
- 步骤:
- 获取流对象
- BufferedReader getReader():获取字符输入流,只能操作字符数据。
- ServletInputStream getInputStream():获取字节输入流,可以操作所有类型数据。
- 再从对象流中拿数据
- 获取流对象
-
其他功能:
- 获取请求参数通用方式:不论get还是post请求方式,都可以获取到参数
- String getParameter(String name):根据参数名 获取参数值
- String[] getParameterValues(String name):根据参数名称获取参数值的数组
- Enumeration getParameterNames():获取所有请求的参数名称
- Map<String,String[]> getParameterMap():获取所有参数的Map集合
- post参数中文乱码问题:request.setCharacterEncoding(“utf-8”);
- 转发(将请求交给别人处理):一种在服务器内部的资源跳转方式
- 步骤:
- 通过requset对象获取请求转发器对象:RequestDispatcher getRequestDispatcher(String path)
- 使用RequestDispatcher对象来进行转发:forward(resq,resp);
- 示例:
- 步骤:
- 获取请求参数通用方式:不论get还是post请求方式,都可以获取到参数
-
getRequestDispatcher("转发路径").forward(resq,resp);
2. 特点:
1. 浏览器地址栏不会发生变化
2. 只能转发到当前服务器内部的资源(包括WEB-INF目录下的)
3. 转发是一次请求,可以使用request域共享数据
3. 共享数据(本次请求的数据):
1. 域对象:一个有作用范围的对象,可以在范围内共享数据
2. request域:代表一次请求的范围,一般用于请求转发的多个资源中共享数据
3. 方法:
setAttribute(String name,Object obj):存储数据
Object getAttritude(String name):通过键获取值
removeAttritude(String name):通过键删除键值对
4. 获取ServletContext:
getServletContext()
Response对象常用用法:
设置响应行:
格式:HTTP/1.1 200 OK。
设置状态码:setStatus(int sc)。
设置响应头:
setHeader(String name,String value)
setContentType("text/html;charset=utf-8"),在获取流之前设置编码
设置响应体:
获取输出流:
字符输出流:PrintWriter getWriter()。
字节输出流:ServletOutputStream getOutputStream()。
使用输出流,将数据传送到浏览器。
举例
重定向(自己干不了,叫浏览器向其他人再发一次请求):
重定向:
//设置状态码为 302
response.setStatus(302);
//设置响应头 location
response.setHeader("location","重定向地址");
简单的重定向:
response.sendRedirect("重定向地址");
特点:
地址栏发生变化
重定向可以访问其他站点(服务器)的资源
重定向是两次请求,不能使用request域共享数据
ServletContext对象(单例)
概念:代表整个WEB应用,可以和程序的容器(服务器)来通讯
获取:
通过request对象获取
request.getServletContext();
通过HttpServlet获取
this.getServletContext();
功能;
获取MIME类型
MIME类型:在互联网通讯过程中定义的一种文件数据类型
格式:大类型/小类型,例如:text/html,image/jpeg
域对象:共享数据(所有用户所有请求的数据)
setAttribute(String name,Object obj):存储数据
Object getAttritude(String name):通过键获取值
removeAttritude(String name):通过键删除键值对
获取文件的真实(服务器)路径
String getRealPath(String 绝对路径);
Filter
作用:
一般用于完成通用的操作。如登录验证、统一编码处理、铭感字符过滤’
快速入门:
步骤:
定义一个类,实现接口Filter
覆写方法
配置拦截路径(两种):
web.xml
注解 配置:@WebFilter( path )
放行:
filterChain.doFilter(resq,resp)
过滤器细节
web.xml配置
//导入过滤器
<filter>
<filter-name>过滤器名字</filter-name>
<filter-class>过滤器类包名</filter-class>
</filter>
//给过滤器配置拦截路径
<filter-mapping>
<filter-name>过滤器名字</filter-name>
<url-pattern>拦截路径</url-pattern>
</filter-mapping>
过滤器执行流程
执行过滤器
执行放行后的资源
回来执行过滤器放行代码下边的代码
过滤器生命周期方法
init:在服务器启动后,会创建Filter对象,然后调用init方法。只执行一次,用于加载资源。
doFilter:每一次请求被拦截时,会执行,执行多次。
destroy:在服务器正常关闭后,Filter对象被销毁,执行该方法。
过滤器配置详解
拦截路径配置:
具体资源路径:/index.jsp(只有访问index.jsp资源时,过滤器才会被执行)
拦截目录:/user/*
后缀名拦截“*.jsp
拦截所有资源:/*
拦截方式配置:
注解配置:
设置 dispatcherTypes 属性:
REQUEST:默认值,浏览器直接请求资源
FORWARD:转发访问资源
INCLUDE:包含访问资源
ERROR:错误跳转资源
ASYNC:异步访问资源
web.xml配置:
设置 <dispatcher></dispatcher> 标签即可
过滤器链(配置多个过滤器)
注解配置:
过滤器类名的字典序执行顺序
web.xml配置:
<file-mapping></file-mapping> 配置顺序执行
LIstener
概念
web的三大组件之一
事件监听器:
事件:一件事
事件源:事情发生的地方
监听器:一个对象
ServletContextListener :监听ServletContext对象的创建和销毁
方法:
void contextDestroyed(ServletContextEvent sce):
一般用于加载资源:
注册监听:将事件、事件源、监听器绑定在一起。
在web.xml里面指定初始化参数文件:
<!-- 指定初始化参数 -->
<context-param>
<param-name>键名</param-name>
<param-value>键值</param-value>
</context-param>
获取web.xml里面键名对应的值:
String servletContext.getInitParameter(String name);
void contextInitialized(ServletContextEvent sce):
步骤:
定义类-->继承-->覆写
配置:
web.xml配置:
注解配置:
@WebListener :














 199
199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









