







一、元素八大定位
from selenium import webdriver
'''元素定位,要尽量做到唯一定位'''
# 启动chrome
driver = webdriver.Chrome()
# 访问网站百度
driver.get("https://www.baidu.com")
# 1. 通过id的值查找元素对象
print('通过id的值查找元素对象',driver.find_element_by_id('kw'))
# 2. 通过class名字查找元素对象
print('通过class名字查找元素对象',driver.find_element_by_class_name('s_ipt'))
# 3. 通过name的值查找元素对象
print('通过name的值查找元素对象',driver.find_element_by_name('wd'))
# 4. 通过标签名字查找元素对象
print('通过标签名字查找元素对象',driver.find_elements_by_tag_name('input')[7])
# 5. 针对链接,通过元素内容全匹配查找
print('针对链接,通过元素内容全匹配查找',driver.find_element_by_link_text('更多'))
# 6. 针对链接,通过元素内容模糊查找。partial部分的意思
print('针对链接,通过元素内容模糊查找',driver.find_element_by_partial_link_text('更'))
# 7. xpath。不推荐用绝对路径定位元素,控制台Elments-右键元素-Copy-Copy XPath获取元素绝对路径!
print('通过xpath用绝对路径查找元素对象',driver.find_element_by_xpath('//*[@id="kw"]'))
print('通过xpath用相对路径查找元素对象',driver.find_element_by_xpath('//input[@id="kw"]'))
'''
01. 相对路径定位元素
//开头 + 标签名称 + []包裹属性,@声明是属性
//input[@id="kw"]
02. 也可以使用 and 和 or 判断
//input[@id="kw" and @name="wd"]
//input[@id="kw" or @name="wd"]
03. 通过层级关系精准定位,用/隔开,父/子。
//span[@id="s_kw_wrap"]/input[@id="kw"]
04. 通过text()="元素内容"定位
05. 通过contains(@属性,"部分值")来模拟匹配
'''
print('04通过text()查找元素对象',driver.find_element_by_xpath('//*[@id="s-top-left"]/a[text()="学术"]'))
print('05通过contains模拟匹配',driver.find_element_by_xpath('//input[contains(@class,"s_ipt")]'))
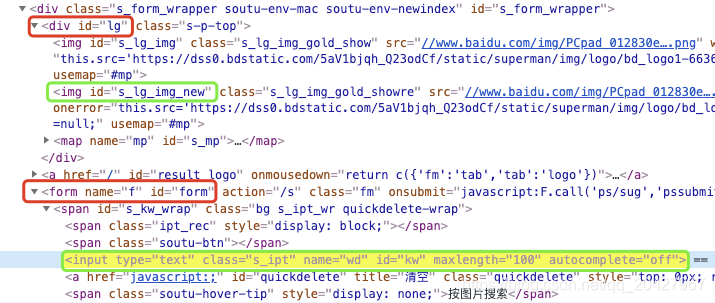
# 8. xpath的轴定位
'''
ancestor:祖先节点,包括父节点
parent:父节点
preceding-sibling:当前元素节点标签之前的所有兄弟节点
following-sibling:当前元素节点标签之后的所有兄弟节点
/轴名称::标签[@属性=属性值]
'''
//img[@id="s_lg_img"]/ancestor::div[@id="lg"]/following-sibling::form[@id="form"]//input[@type="text"]轴定位图
二、元素四个基本操作
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
# 获取元素文本内容
result = driver.find_element_by_xpath('//div[@id="s-top-left"]/a[@href="http://news.baidu.com"]').text
# 点击该元素
driver.find_element_by_xpath('//div[@id="s-top-left"]/a[@href="http://news.baidu.com"]').click()
# 输入输入框内容
driver.find_element_by_xpath('//div[@id="s-top-left"]/a[@href="http://news.baidu.com"]').send_keys(“内容”)
# 获取元素内该属性值
driver.find_element_by_xpath('//div[@id="s-top-left"]/a[@href="http://news.baidu.com"]').get_attribute("属性名称")
print(result)三、窗口四个基本操作
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
driver.find_element_by_id('kw').send_keys('如何把大羊薅秃')
driver.find_element_by_id('su').click()
time.sleep(2)
ele_one = driver.find_element_by_xpath('//a[text()="秃羊图片"]')
ele_two = driver.find_element_by_xpath('//a[text()="薅秃了什么意思"]')
# 滑动到页面底部
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
time.sleep(5)
# 将元素顶部与当前窗口顶部对齐
driver.execute_script("arguments[0].scrollIntoView();",ele_two)
time.sleep(5)
# 将元素底部与当前窗口底部对齐
driver.execute_script("arguments[0].scrollIntoView(false);",ele_one)
time.sleep(5)
# 滑动到页面顶部
driver.execute_script("window.scrollTo(document.body.scrollHeight,0);")
四、toast弹窗元素定位
通过暂停脚本,来定位

五、强制等待
利用time模块的sleep方法来实现页面加载等待时间,强制等待。
这种方法不管你浏览器是否加载完成,都得给我等待3秒,3秒一到,继续执行下面的代码,不建议用这种等待方法,严重影响代码的执行速度
六、隐式等待
设置一个等待时间,如果在这个等待时间内,网页加载完成,则执行下一步;否则一直等待时间截止,然后再执行下一步。这样也就会有个弊端,程序会一直等待整个页面加载完成,直到超时,但有时候我需要的那个元素早就加载完成了,只是页面上有个别其他元素加载特别慢,我仍要等待页面全部加载完成才能执行下一步。
# 隐式等待30秒 browser.implicitly_wait(30)
七、显示等待
可以通过Python源码查看具体应用及语法结构等;
driver - 浏览器驱动
timeout - 超时前的秒数
poll_frequency - 时间隔间的秒数,默认0.5s
ignored_exceptions - 调用期间忽略的异常类的可迭代结构。默认情况下,它仅包含NoSuchElementException
列子:
# 超时时间为10秒,每0.5秒(默认)检查1次,直到id="someId"的元素出现
element = WebDriverWait(driver, 10).until(lambda x: x.find_element_by_id("someId"))
# 超时时间为30秒,每1秒检查1次,判断id = “someId” 元素是否消失,如果消失是返回Ture,否返回False
is_disappeared = WebDriverWait(driver, 30, 1, (ElementNotVisibleException)).until_not(lambda x: x.find_element_by_id("
from selenium import webdriver
'''元素定位,要尽量做到唯一定位'''
# 启动chrome
driver = webdriver.Chrome()
# 访问网站百度
driver.get("https://www.baidu.com")
# 1. 通过id的值查找元素对象
print('通过id的值查找元素对象',driver.find_element_by_id('kw'))
# 2. 通过class名字查找元素对象
print('通过class名字查找元素对象',driver.find_element_by_class_name('s_ipt'))
# 3. 通过name的值查找元素对象
print('通过name的值查找元素对象',driver.find_element_by_name('wd'))
# 4. 通过标签名字查找元素对象
print('通过标签名字查找元素对象',driver.find_elements_by_tag_name('input')[7])
# 5. 针对链接,通过元素内容全匹配查找
print('针对链接,通过元素内容全匹配查找',driver.find_element_by_link_text('更多'))
# 6. 针对链接,通过元素内容模糊查找。partial部分的意思
print('针对链接,通过元素内容模糊查找',driver.find_element_by_partial_link_text('更'))
# 7. xpath。不推荐用绝对路径定位元素,控制台Elments-右键元素-Copy-Copy XPath获取元素绝对路径!
print('通过xpath用绝对路径查找元素对象',driver.find_element_by_xpath('//*[@id="kw"]'))
print('通过xpath用相对路径查找元素对象',driver.find_element_by_xpath('//input[@id="kw"]'))
'''
01. 相对路径定位元素
//开头 + 标签名称 + []包裹属性,@声明是属性
//input[@id="kw"]
02. 也可以使用 and 和 or 判断
//input[@id="kw" and @name="wd"]
//input[@id="kw" or @name="wd"]
03. 通过层级关系精准定位,用/隔开,父/子。
//span[@id="s_kw_wrap"]/input[@id="kw"]
04. 通过text()="元素内容"定位
05. 通过contains(@属性,"部分值")来模拟匹配
'''
print('04通过text()查找元素对象',driver.find_element_by_xpath('//*[@id="s-top-left"]/a[text()="学术"]'))
print('05通过contains模拟匹配',driver.find_element_by_xpath('//input[contains(@class,"s_ipt")]'))
# 8. xpath的轴定位
'''
ancestor:祖先节点,包括父节点
parent:父节点
preceding-sibling:当前元素节点标签之前的所有兄弟节点
following-sibling:当前元素节点标签之后的所有兄弟节点
/轴名称::标签[@属性=属性值]
'''
//img[@id="s_lg_img"]/ancestor::div[@id="lg"]/following-sibling::form[@id="form"]//input[@type="text"]
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
driver.find_element_by_id('kw').send_keys('如何把大羊薅秃')
driver.find_element_by_id('su').click()
time.sleep(2)
ele_one = driver.find_element_by_xpath('//a[text()="秃羊图片"]')
ele_two = driver.find_element_by_xpath('//a[text()="薅秃了什么意思"]')
# 滑动到页面底部
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
time.sleep(5)
# 将元素顶部与当前窗口顶部对齐
driver.execute_script("arguments[0].scrollIntoView();",ele_two)
time.sleep(5)
# 将元素底部与当前窗口底部对齐
driver.execute_script("arguments[0].scrollIntoView(false);",ele_one)
time.sleep(5)
、
# 滑动到页面顶部
driver.execute_script("window.scrollTo(document.body.scrollHeight,0);")
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
# 获取元素文本内容
result = driver.find_element_by_xpath('//div[@id="s-top-left"]/a[@href="http://news.baidu.com"]').text
# 点击该元素
driver.find_element_by_xpath('//div[@id="s-top-left"]/a[@href="http://news.baidu.com"]').click()
# 输入输入框内容
driver.find_element_by_xpath('//div[@id="s-top-left"]/a[@href="http://news.baidu.com"]').send_keys(“内容”)
# 获取元素内该属性值
driver.find_element_by_xpath('//div[@id="s-top-left"]/a[@href="http://news.baidu.com"]').get_attribute("属性名称")
print(result)















 1259
1259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











