







saveAsTextFile很慢,一个文件saveASText要15分钟以上,解决思路:
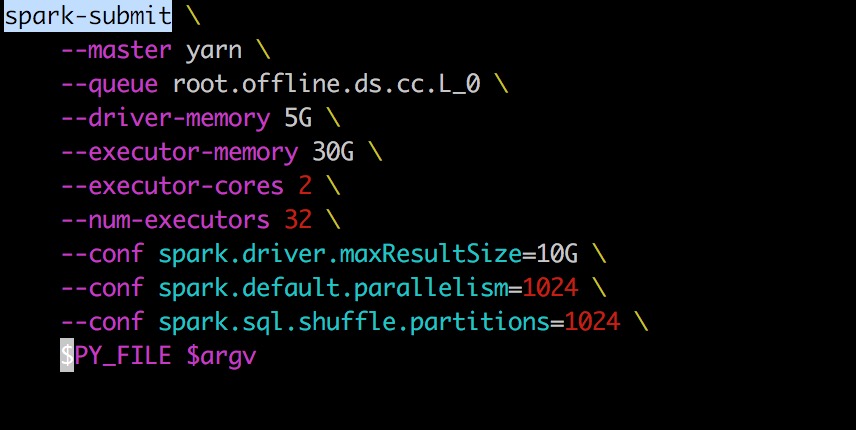
1、配置文件:查看spark-submit的参数
如截图,查看一下这些配置是否设置的过小
2、代码(python)
df.rdd.map(lambda x: (random.randint(1, 10240), x)).partitionBy(128).map(lambda (r, x): "%s" % (x), True).saveAsTextFile("/data")注意(random.randint(1, 10240)和partitionBy(128)这两部分。
通过这两种方法可以极大的提高saveAsTextFile的速度,以前需要15分钟,现在2分钟就可以存储结束














 642
642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









