 YARN上部署Spark任务
YARN上部署Spark任务





 本文介绍如何在YARN集群中高效配置Spark任务,包括调整内存分配、最小内存限制及内存规整化单位等参数。通过实验确定的内存开销比例,确保资源利用最大化的同时减少浪费。
本文介绍如何在YARN集群中高效配置Spark任务,包括调整内存分配、最小内存限制及内存规整化单位等参数。通过实验确定的内存开销比例,确保资源利用最大化的同时减少浪费。
spark-defaults.conf
spark.master=yarn
# spark_deploy_mode=cluster
spark.driver.memory=1G
spark.executor.memory=1G
spark.testing.reservedMemory=0
# 去除1.5*300M 最小提交内存限制,环境资源紧张时可以设为0
yarn-site.xml
<property>
<name>yarn.scheduler.increment-allocation-mb</name>
<value>128</value>
<description>内存规整化单位,默认是1024,这意味着,如果一个Container请求资源是1.5GB,则将被调度器规整化为ceiling(1.5 GB / 1GB) * 1G=2GB</description>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>128</value>
<description>容器可以请求的最小物理内存量(以 MiB 为单位)</description>
</property>
package org.apache.spark.deploy.yarn
object YarnSparkHadoopUtil {
// Additional memory overhead
// 10% was arrived at experimentally. In the interest of minimizing memory waste while covering
// the common cases. Memory overhead tends to grow with container size.
val MEMORY_OVERHEAD_FACTOR = 0.10
val MEMORY_OVERHEAD_MIN = 384L
// 资源紧张可将384调为128或256,重新编译
spark.yarn.executor.memoryOverhead:max(executorMemory*0.1,384m)
spark.yarn.driver.memoryOverhead:max(driverMemory*0.1,384m)
driver、executor执行的时候,用的内存可能会超过executor-memoy,所以会为executor额外预留一部分内存,memoryOverhead代表了这部分内存,计算方法如下代码
package org.apache.spark.deploy.yarn
private[spark] class Client(
private val isClusterMode = sparkConf.get("spark.submit.deployMode", "client") == "cluster"
// AM related configurations
private val amMemory = if (isClusterMode) {
sparkConf.get(DRIVER_MEMORY).toInt
} else {
sparkConf.get(AM_MEMORY).toInt
}
private val amMemoryOverhead = {
val amMemoryOverheadEntry = if (isClusterMode) DRIVER_MEMORY_OVERHEAD else AM_MEMORY_OVERHEAD
sparkConf.get(amMemoryOverheadEntry).getOrElse(
math.max((MEMORY_OVERHEAD_FACTOR * amMemory).toLong, MEMORY_OVERHEAD_MIN)).toInt
}
// Executor related configurations
private val executorMemory = sparkConf.get(EXECUTOR_MEMORY)
private val executorMemoryOverhead = sparkConf.get(EXECUTOR_MEMORY_OVERHEAD).getOrElse(
math.max((MEMORY_OVERHEAD_FACTOR * executorMemory).toLong, MEMORY_OVERHEAD_MIN)).toInt
提交任务脚本
#!/bin/bash
source /etc/profile
driverMem=128M
#增加driverCores 内存不变
driverCores=1
#增加numExecutor 内存*并行度
numExecutor=1
#增加executorCores 内存不变
executorCores=1
executorMem=128M
nohup spark-submit --master yarn --driver-memory $driverMem --driver-cores $driverCores --num-executors $numExecutor --executor-cores $executorCores --executor-memory $executorMem --class className jarName.jar >> logName.log 2>&1 &
# 19/11/22 16:55:37 INFO yarn.Client: Will allocate AM container, with 512 MB memory including 384 MB overhead
实际占用资源为
driver overhead max(128M*0.1,384m)=384m
AM container = driver + overhead =128M + 384m = 512m
executor overhead max(128M*0.1,384m)=384m
nodemanager = executor + overhead = 128M + 384m = 512m
all = 512m + 512m = 1024m
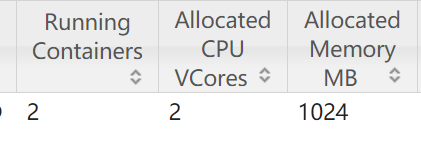
总结:
在yarn 最小分配128m,内存增量128m
cluster方式提交,设置 reservedMemory为0
不修改源码284限制,不指定 overhead 大小
提交spark任务最少需要2 cpu 1024M 内存

















 797
797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









