







本文参考《Python数据分析与挖掘实战》一书。
对于数据挖掘的缺失值的处理,应该是在数据预处理阶段应该首先完成的事,缺失值的处理一般情况下有三种方式:1.删掉缺失值数据。2不对其进行处理 3.利用插补法对数据进行补充
第一种方式是极为不可取的,如果你的样本数够多,删掉数据较少,这种情况下还是可取的,但是,如果你的数据本身就比较少,而且还删除数据,这样会导致大量的资源浪费,将丢弃了大量隐藏在这些记录中的信息.
利用插值法对数据进行补充,是极为推荐的一个方式.
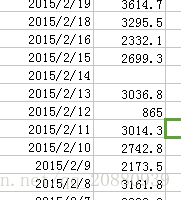
上图是我们处理数据的一个部分截图,可以看出在2015/2/14日这一天,我们的数据是缺失的,为此利用插值法对其进行补充,处理后的数据:
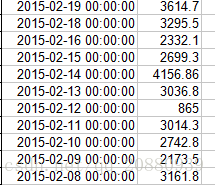
可见处理后的数据变成了4156.86.。
另外要说一点是,本程序还设置了对异常数据的过滤值的操作,我们将异常值进行过滤,然后也可以对其进行插补.
关于这个异常值的那一段代码的异常值是怎么判断出来的? 这里面可以有很多的判断方式,比较直观的方式是画箱型图,这样就可以很容易的制定出这样的过滤标准.(我以前的博客对这个问题有详细的描述,附代码)
#利用拉格朗日插值法填充数据
import pandas as pd
from scipy.interpolate import lagrange
inputfile='E:/catering_sale.xls'
outputfile='E:/sale.xls'
data=pd.read_excel(inputfile)
data[u'销量'][(data[u'销量']<400)|(data[u'销量']>5000)]=None
#自定义列向量插值函数
#s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s,n,k=5):
#取数
y=s[list(range(n-k,n))+list(range(n+1,n+1+k))]
#剔除空值
y=y[y.notnull()]
#返回拉格朗日函数结果
return lagrange(y.index,list(y))(n)
#逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if(data[i].isnull())[j]:
data[i][j]=ployinterp_column(data[i],j)
data.to_excel(outputfile)














 7569
7569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









