







这道题因为编写的BFS代码超时,我花了挺长时间在于思考,如何解决重复计算,如何编写一个DFS,把惯用的暴力搜索思维改成记忆搜索的一个过程,直至写完这篇博客,我感觉脑子还是有点小乱的,不过代码的流程还是非常清晰的。
题目简介:
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,在字符串中增加空格来构建一个句子,使得句子中所有的单词都在词典中。返回所有这些可能的句子。
说明:
分隔时可以重复使用字典中的单词。
你可以假设字典中没有重复的单词。
示例 1:
输入:
s = “catsanddog”
wordDict = [“cat”, “cats”, “and”, “sand”, “dog”]
输出:
[
“cats and dog”,
“cat sand dog”
]
示例 2:
输入:
s = “pineapplepenapple”
wordDict = [“apple”, “pen”, “applepen”, “pine”, “pineapple”]
输出:
[
“pine apple pen apple”,
“pineapple pen apple”,
“pine applepen apple”
]
解释: 注意你可以重复使用字典中的单词。
示例 3:
输入:
s = “catsandog”
wordDict = [“cats”, “dog”, “sand”, “and”, “cat”]
输出:
[]
题解:
这道题我的最初思路是通过BFS,心里面想这么简单还标困难???让我直接遍历完事,然后便写了一个BFS版本,然后就发生了下面的情况:
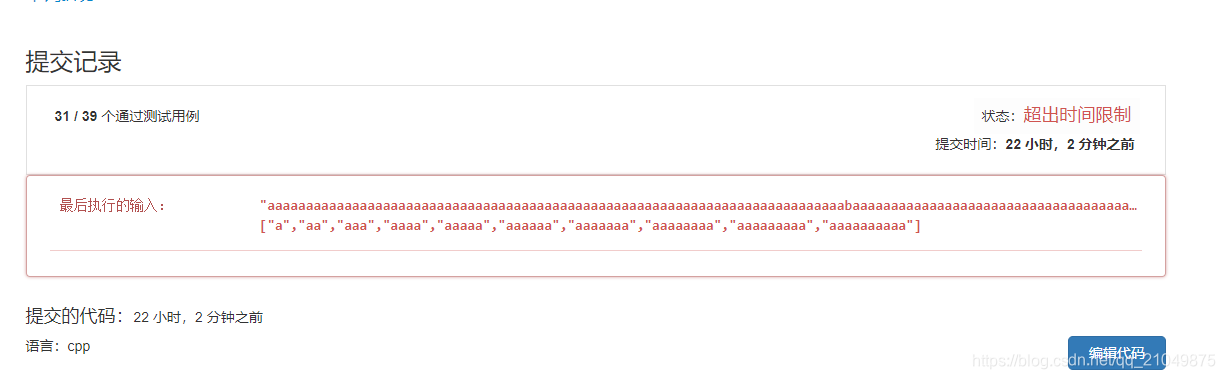
BFS超时代码:
class Solution {
public:
vector<string> wordBreak(string s, vector<string>& wordDict) {
if (wordDict.empty() || s.length() == 0)
return vector<string>();
vector<string>res;
op(s, string(), wordDict, res);
return res;
}
void op(string s, string tmp, vector<string>&word, vector<string>&res) {
if (s.length() == 0) {
res.push_back(tmp);
return;
}
string old;
for (auto i : word) {
old = tmp;
int pos = s.find(i);
if (pos == -1||pos!=0) {
continue;
}
string tmps = s.substr(i.length());
if (tmps.length() == 0) {
tmp += i;
}
else {
tmp += i + " ";
}
op(tmps, tmp, word, res);
tmp = old;
}
}
};
看到这个测试用例,就意识到了一件事情,如果重复的字符较多的字符串与字典,那么会出现重复遍历字符串,就会出现超时,或者爆栈,而解决这个问题的方法就是记录已经遍历过的字符串以及其组成的相应字符,如例题中我们需要存储的字典应该是: {sanddog:sand dog,anddog:and dog,....},字典的key为字符串的前缀,value则为组成的字符串。
所以,我将代码改为了DFS的方式,修改为DFS的时候脑子有点转不过来,大概写多了BFS习惯了,
BFS的代码比较容易理解,而下面DFS相对BFS较为复杂一些理解,代码大概意思是这样:
我们要把s拆分为words里的单词,那么我们就要拆分s-1的字符串,即:
S为原字符串,N为字符串长度,words为字典。
S[0,N]=S[words[i].length,N]+words[i] 0<i<=words.size
其中words[i]必须位于S[0,words[i].length],即位于原字符串头部,而我们计算S[words[i].length,N]时,则将其当作新字符串处理,则N=S.length-words[i].length,即新的字符串也就是原字符串的字串为:
S[0,S.length-words[i].length]
于是我们就可以编写代码了,当出现重复字符,如“aaaaa”与{“a”,“aa”,“aaa”},会产生重复计算的过程,如“a a a”与“aa a”分别是由i=0与i=1,即由words[0]、words[1]这两个单词拆分到某个阶段而成,此时两者都还剩"aa"要拆分,于是造成了重复计算,所以我们可以利用一个map去存储这些结果,避免重复存储。
DFS方案解决问题代码:
class Solution {
public:
unordered_map<string, vector<string>>_set;
vector<string> wordBreak(string s, vector<string>& wordDict) {
if (wordDict.empty() || s.length() == 0)
return vector<string>();
auto rt = op(s, wordDict);
return rt;
}
vector<string> op(string s, vector<string>&word) {
vector<string>rt;
if (_set.find(s) != _set.end())
return _set[s];
//这里不能直接return rt,如果s是一个重复字符串,而s的子串也在words中,那么就拆分不到子串了
if (find(word.begin(), word.end(), s) != word.end()) {
rt = { s };
}
for (auto i : word) {
int pos = s.find(i);
if (pos == -1 || pos != 0)
continue;
string dfs = s.substr(i.length());
auto fuck = op(dfs, word);
for (auto j : fuck) {
rt.push_back(i + " " + j);
}
}
_set[s] = rt;
return rt;
}
};
结果:














 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









