学习于:简单粗暴 TensorFlow 2
1. Checkpoint 保存变量
tf.train.Checkpoint 可以保存 tf.keras.optimizer 、 tf.Variable 、 tf.keras.Layer 、 tf.keras.Model
path = "./checkp.ckpt"
mycheckpoint = tf.train.Checkpoint(mybestmodel=mymodel)
mycheckpoint.save(path)
restored_model = LinearModel()
mycheckpoint = tf.train.Checkpoint(mybestmodel=restored_model)
path = "./checkp.ckpt-1"
mycheckpoint.restore(path)
X_test = tf.constant([[5.1], [6.1]])
res = restored_model.predict(X_test)
print(res)
- 恢复最近的模型,自动选定目录下最新的存档(后缀数字最大的)
mycheckpoint.restore(tf.train.latest_checkpoint("./"))
mycheckpoint = tf.train.Checkpoint(mybestmodel=mymodel)
manager = tf.train.CheckpointManager(mycheckpoint, directory="./",
checkpoint_name='checkp.ckpt',
max_to_keep=2)
for loop:
manager.save()
manager.save(checkpoint_number=idx)
2. TensorBoard 训练过程可视化
summary_writer = tf.summary.create_file_writer(logdir=log_dir)tf.summary.scalar(name='loss', data=loss, step=idx)tf.summary.trace_on(profiler=True)
for loop:
with summary_writer.as_default():
tf.summary.scalar(name='loss', data=loss, step=idx)
with summary_writer.as_default():
tf.summary.trace_export(name='model_trace', step=0,
profiler_outdir=log_dir)
import tensorflow as tf
import numpy as np
class MNistLoader():
def __init__(self):
data = tf.keras.datasets.mnist
(self.train_data, self.train_label), (self.test_data, self.test_label) = data.load_data()
self.train_data = np.expand_dims(self.train_data.astype(np.float32) / 255.0, axis=-1)
self.test_data = np.expand_dims(self.test_data.astype(np.float32) / 255.0, axis=-1)
self.train_label = self.train_label.astype(np.int32)
self.test_label = self.test_label.astype(np.int32)
self.num_train_data, self.num_test_data = self.train_data.shape[0], self.test_data.shape[0]
def get_batch(self, batch_size):
idx = np.random.randint(0, self.num_train_data, batch_size)
return self.train_data[idx, :], self.train_label[idx]
class MLPmodel(tf.keras.Model):
def __init__(self):
super().__init__()
self.flatten = tf.keras.layers.Flatten()
self.dense1 = tf.keras.layers.Dense(units=100, activation='relu')
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, input):
x = self.flatten(input)
x = self.dense1(x)
x = self.dense2(x)
output = tf.nn.softmax(x)
return output
num_epochs = 5
batch_size = 50
learning_rate = 1e-4
log_dir = './log'
mymodel = MLPmodel()
data_loader = MNistLoader()
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
num_batches = int(data_loader.num_train_data // batch_size * num_epochs)
summary_writer = tf.summary.create_file_writer(logdir=log_dir)
tf.summary.trace_on(profiler=True)
for idx in range(num_batches):
X, y = data_loader.get_batch(batch_size)
with tf.GradientTape() as tape:
y_pred = mymodel(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=y, y_pred=y_pred)
loss = tf.reduce_mean(loss)
print("batch {}, loss {}".format(idx, loss.numpy()))
with summary_writer.as_default():
tf.summary.scalar(name='loss', data=loss, step=idx)
grads = tape.gradient(loss, mymodel.variables)
optimizer.apply_gradients(grads_and_vars=zip(grads, mymodel.variables))
with summary_writer.as_default():
tf.summary.trace_export(name='model_trace', step=0,
profiler_outdir=log_dir)
- 开始训练,命令行进入 可视化界面
tensorboard --logdir=./log

- 点击命令行中的链接,打开浏览器,查看训练曲线
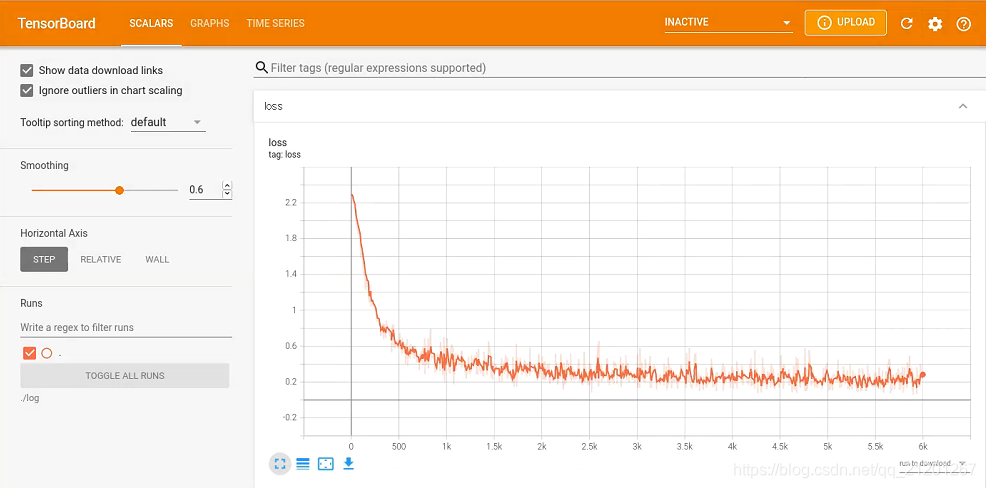
- 若重新训练,请删除 log 文件,或设置别的 log 路径,重新 cmd 开启 浏览器























 594
594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











