









环境:win 10 + java 1.8.0_281 + Scala 2.11.11 + Hadoop 2.7.7 + Spark2.4.7
0. 常规解压安装,并添加环境变量

1. 下载并覆盖 bin 文件夹
下载 hadooponwindows-master.zip
下载地址:https://pan.baidu.com/s/1o7YTlJO
将下载好的 hadooponwindows-master.zip 解压,将解压后的 bin目录下的所有文件直接覆盖Hadoop的 bin目录
2. 使VERSION文件的clusterID一致
原因是clusterID不一致
删除tmp下的内容
从/home/hdp/hadoop/name/current/VERSION 获得clusterID
修改到
/home/hdp/hadoop/data/current/VERSION
修改保持一致,然后重启服务
3. 贴下单机配置
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/hadoop-2.7.7/data/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/D:/hadoop-2.7.7/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/D:/hadoop-2.7.7/data/datanode</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.job.user.name</name>
<value>%USERNAME%</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.apps.stagingDir</name>
<value>/user/%USERNAME%/staging</value>
</property>
<property>
<name>mapreduce.jobtracker.address</name>
<value>local</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- nodemanager要求的内存最低为1024 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>
D:\hadoop-2.7.7\etc\hadoop\hadoop-env.cmd
更改1行
set JAVA_HOME=D:\Java\jdk1.8.0_281
末尾追加4行
set HADOOP_PREFIX=%HADOOP_HOME%
set HADOOP_CONF_DIR=%HADOOP_PREFIX%\etc\hadoop
set YARN_CONF_DIR=%HADOOP_CONF_DIR%
set PATH=%PATH%;%HADOOP_PREFIX%\bin
4. 测试 Hadoop
- 格式化,启动
hadoop namenode -format
start-dfs.cmd
start-yarn.cmd
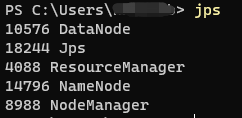
- jps 查看进程
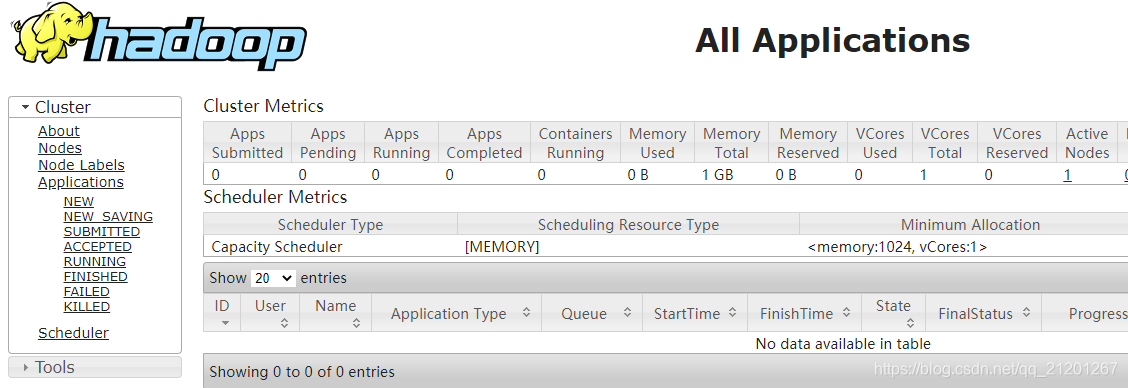
- 网页能打开

- 创建 hdfs 文件夹,并查看
hadoop fs -mkdir hdfs://localhost:9000/user/
hdfs dfs -ls /
5. 安装Spark
参考:https://blog.csdn.net/weixin_45092662/article/details/107490615
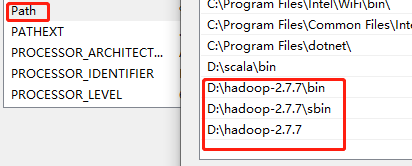
- 添加 环境变量 + Path
PS C:\Users\xxx> spark-shell.cmd
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://windows10.microdone.cn:4040
Spark context available as 'sc' (master = local[*], app id = local-1619526523582).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.7
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_281)
Type in expressions to have them evaluated.
Type :help for more information.















 5740
5740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











