







文章目录

1.概述
转载:https://www.modb.pro/db/174527
Kafka Consumer用来从Kafka集群拉取数据,通过consumer groups允许多个进程共同分担消费/处理数据的工作,这些进程可以运行在一台机器或者多台机器。
默认常见的消费原理如下
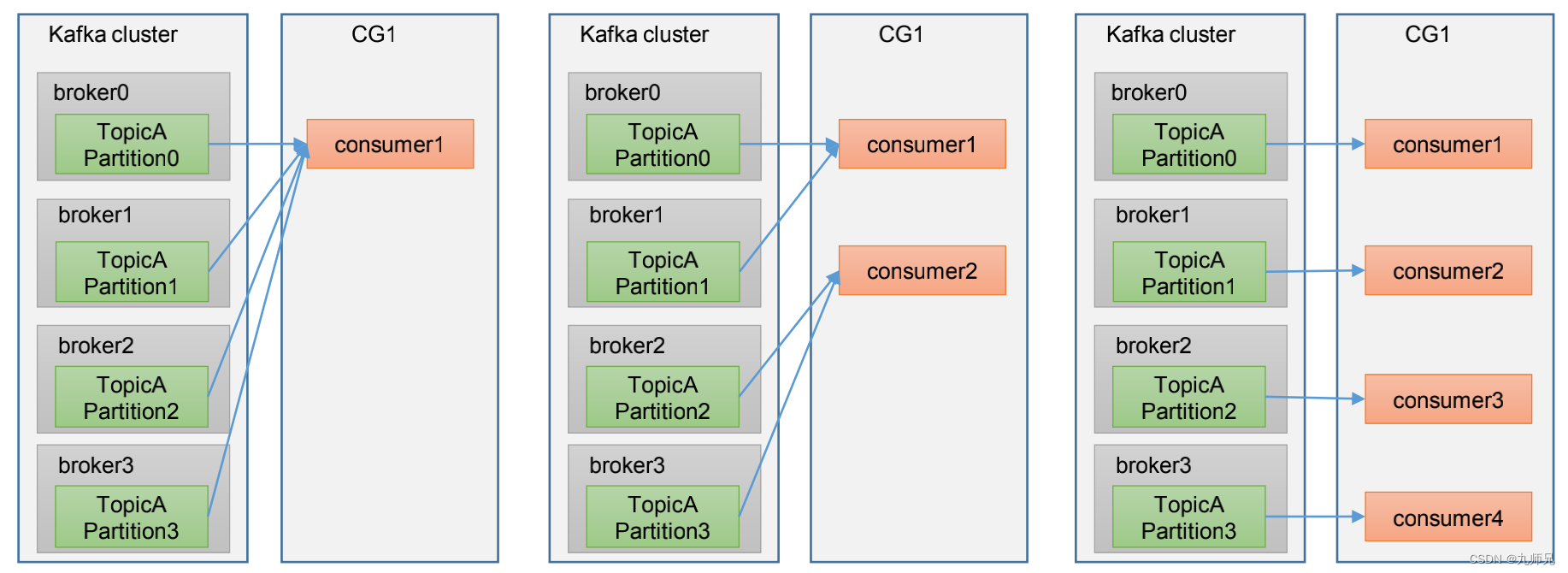
Consumer Group (CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的 groupid 相同。
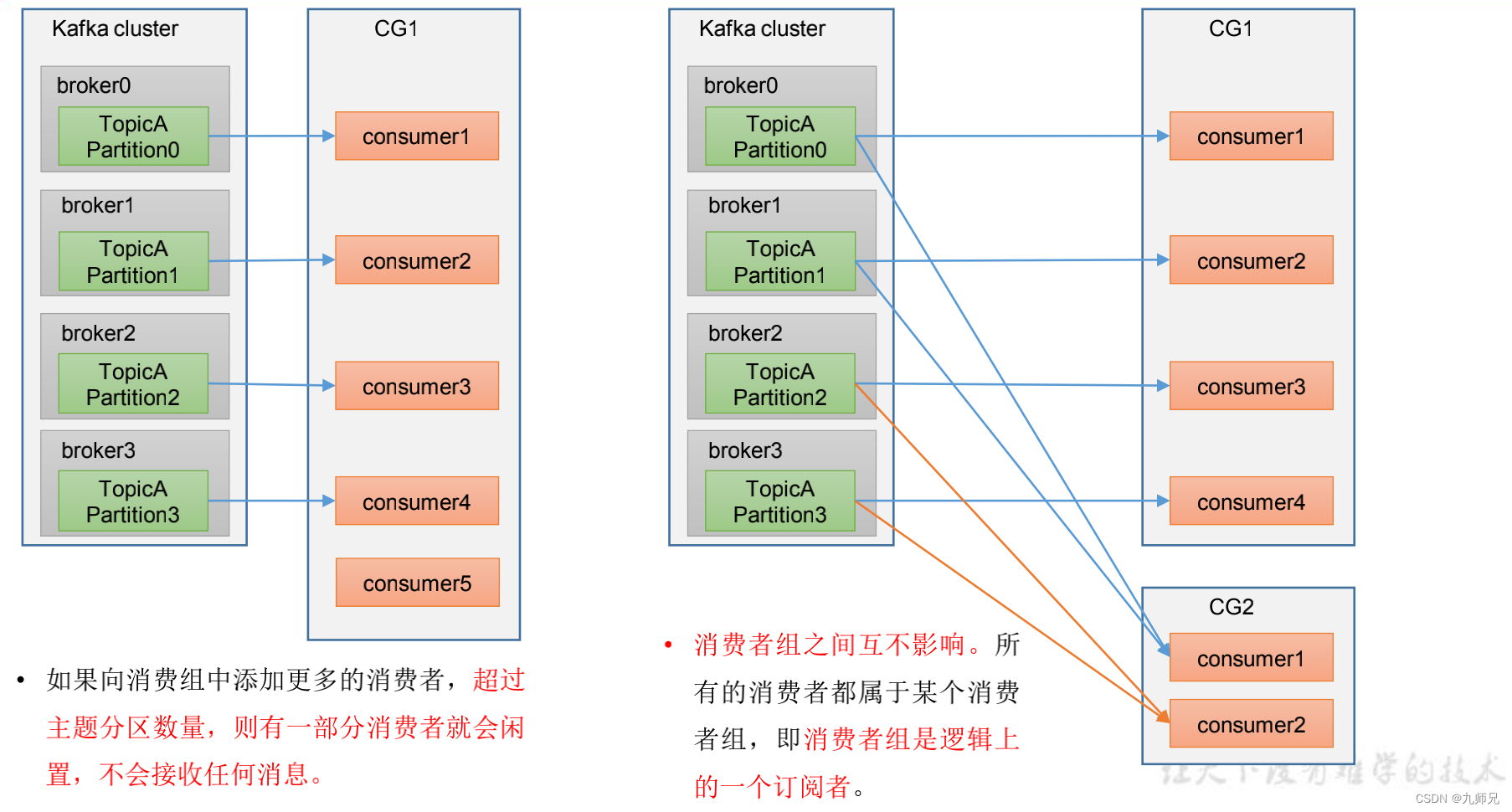
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
- 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
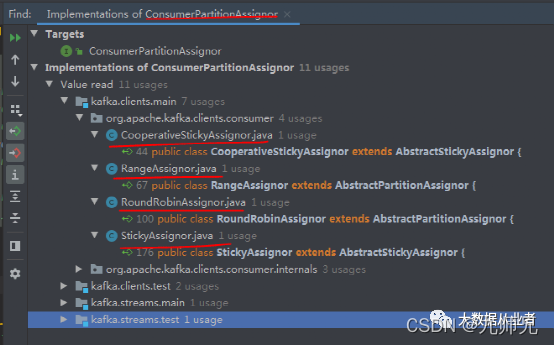
而ConsumerPartitionAssignor接口用来定制consumer的分区分配策略。通过consumer配置项partition.assignment.strtegy指定分区分配策略类。消费者分区分配策略类的实现方法共有四种。
2.RoundRobinAssignor详解
将所有可用partitions和consumers展开(字典排序),以轮询的方式将partitions依次分配给consumers。如果consuemrs订阅Topics都是相同的,那么partitions将会被均匀分配给每个consumer。最理想的状态是partitions数是consumers数的整数倍,这样每个consumer都有相同数量的partitions数。例如:两个consumers(C0、C1),两个topics(T0、T1),分区数均为3。如果Consumers订阅信息为:
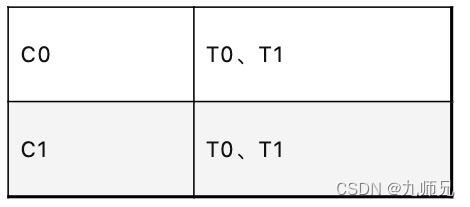
则Consumers分区分配方案为:
| C0 | T0P0、T0P2、T1P1 |
|---|---|
| C1 | T0P1、T1P0、T1P2 |
但是,如果consumers订阅Topics不相同,仍然按照轮询方式进行分配,将导致consumer之间分区分配不均衡。例如:三个consumers(C0、C1、C2),三个Topics(T0、T1、T2),T0分区数为1、T1分区数为2、T3分区数为3。如果Consumers订阅信息为:
C0 | T0 |
C1 | T0、T1 |
C2 | T0、T1、T2 |
则Consumers分区分配方案为:
C0 | T0P0 |
C1 | T1P0 |
C2 | T1P1、T2P0、T2P1、T2P2 |
3.RangeAssignor详解
与RoundRobinAssignor不同,RangeAssignor作用域为每个Topic。对于每一个Topic,将该Topic的所有可用partitions和订阅该Topic的所有consumers展开(字典排序),然后将partitions数量除以consumers数量,算数除的结果分别分配给订阅该Topic的consumers,算数除的余数分配给前一个或者前几个consumers。
所以,如果该Topic的partitions数量与订阅该Topic的consumers数量不是整数倍关系,将造成前一个或者前几个consumer分配到较多的partitions,达不到consumer之间分区分配均衡的效果(不管是面向所有Topics还是单个Topic)。例如:两个consumers(C0、C1),两个Topics(T0、T1),分区数均为3。如果Consumers订阅信息为:
C0 | T0 |
C1 | T1 |
则Consumers分区分配方案为:
C0 | T0P0、T0P1、T1P0、T1p1 |
C1 | T0P2、T1P2 |
4.StickyAssignor详解
前两种分配策略(RoundRobinAssignor、RangeAssignor)都存在分区分配不均衡的情况,而StickyAssignor有两个目标:
- 首先,
尽可能保证分区分配均衡(即分配给consumers的分区数最大相差为1); - 其次,
当发生分区重分配时,尽可能多的保留现有的分配结果。当然,第一个目标的优先级高于第二个目标。
乍一看,这个描述跟RoundRobinAssignor相同,其实并非如此。例如:三个consumers(C0、C1、C2),四个Topics(T0、T1、T2、T3)。
如果Consumers订阅信息为:
C0 | T0、T1、T2、T3 |
C1 | T0、T1、T2、T3 |
C2 | T0、T1、T2、T3 |
则RoundRobinAssignor和StickyAssignor分区分配方案均为:
C0 | T0P0、T1P1、T3P0 |
C1 | T0P1、T2P0、T3P1 |
C2 | T1P0、T2P1 |
现在,假设C1被移除,将触发分区重分配。此时,RoundRobinAssignor和StickyAssignor的分区分配方案将有所差异。
RoundRobinAssignor分区分配方案将变为:
C0 | T0P0、T1P0、T2P0、T3P0 |
C2 | T0P1、T1P1、T2P1、T3P1 |
保留之前的分区分配方案的3个分区不变。
StickyAssignor分区分配方案将变为:
C0 | T0P0、T1P1、T3P0、T2P0 |
C2 | T1P0、T2P1、T0P1、T3P1 |
保留之前的分区分配方案的5个分区不变。由此可见,StickyAssignor尽量保存之前的分区分配方案,分区重分配变动更小。
以上为所有consumers均订阅所有topics的场景,接着介绍consumers订阅topics不相同的场景。例如:三个consumers(C0、C1、C2),三个Topics(T0、T1、T2),分区数分别为1、2、3。如果consumers订阅信息为:
C0 | T0 |
C1 | T0、T1 |
C2 | T0、T1、T2 |
RoundRobinAssignor分区分配方案为:
C0 | T0P0 |
C1 | T1P0 |
C2 | T1P1、T2P0、T2P1、T2P2 |
StickyAssignor分区分配方案为:
C0 | T0P0 |
C1 | T1P0、T1P1 |
C2 | T2P0、T2P1、T2P2 |
由此可见,分区均衡性来说,RoundRobinAssignor不如StickyAssignor均衡。
现在,假设C0被移除,将触发分区重分配。此时,RoundRobinAssignor和StickyAssignor的分区分配方案将有所差异。
RoundRobinAssignor分区分配方案将变为:
C1 | T0P0、T1P1 |
C2 | T1P0、T2P0、T2P1、T2P2 |
保留之前的分区分配方案的4个分区不变。
StickyAssignor分区分配方案将变为:
C1 | T1P0、T1P1、T0P0 |
C2 | T2P0、T2P1、T2P2 |
保留之前的分区分配方案的5个分区不变。
由此可见,StickyAssignor尽量保存之前的分区分配方案,分区重分配变动更小。
StickyAssignor粘性分配策略,主要作用是保证客户端,比如consumer消费者在重平衡后能够维持原本的分配方案,可惜的是这个分配策略依旧是在eager协议的框架之下,重平衡仍然需要每个consumer都先放弃当前持有的资源(分区)。
5.CooperativeStickyAssignor详解
原文:https://www.confluent.io/blog/cooperative-rebalancing-in-kafka-streams-consumer-ksqldb/
上述三种分区分配策略均是基于eager协议,Kafka2.4.0开始引入CooperativeStickyAssignor策略。CooperativeStickyAssignor与之前的StickyAssignor虽然都是维持原来的分区分配方案。
最大的区别是:StickyAssignor仍然是基于eager协议,分区重分配时候,都需要consumers先放弃当前持有的分区,重新加入consumer group;而CooperativeStickyAssignor基于cooperative协议,该协议将原来的一次全局分区重平衡,改成多次小规模分区重平衡。
例如:一个Topic(T0,三个分区),两个consumers(consumer1、consumer2)均订阅Topic(T0)。如果consumers订阅信息为:
consumer1 | T0P0、T0P2 |
consumer2 | T0P1 |
此时,新的consumer3加入消费者组,那么基于eager协议的分区重分配策略流程:

-
consumer1、 consumer2正常发送心跳信息到Group Coordinator。
-
随着consumer3加入,Group Coordinator收到对应的Join Group请求,Group Coordinator确认有新成员需要加入消费者组。
-
Group Coordinator 通知consumer1和consumer2,需要rebalance了。
-
consumer1和consumer2放弃(revoke)当前各自持有的已有分区,重新发送Join Group请求到Group Coordinator。
-
Group Coordinator依据指定的分区分配策略的处理逻辑,生成新的分区分配方案,然后通过Sync Group请求,将新的分区分配方案发送给consumer1、consumer2、consumer3。
-
所有consumers按照新的分区分配,重新开始消费数据。
而基于cooperative协议的分区分配策略的流程:
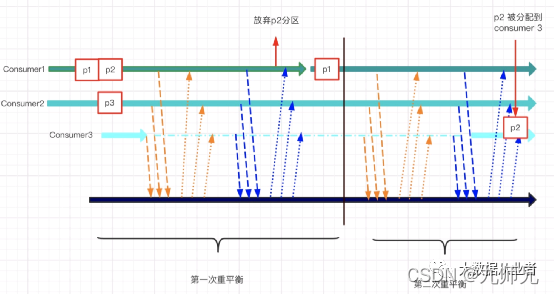
-
consumer1、 consumer2正常发送心跳信息到Group Coordinator。
-
随着consumer3加入,Group Coordinator收到对应的Join Group请求,Group Coordinator确认有新成员需要加入消费者组。
-
Group Coordinator 通知consumer1和consumer2,需要rebalance了。
-
consumer1、consumer2通过Join Group请求将已经持有的分区发送给Group Coordinator。注意:并没有放弃(revoke)已有分区。
-
Group Coordinator取消consumer1对分区p2的消费,然后发送sync group请求给consumer1、consumer2。
-
consumer1、consumer2接收到分区分配方案,重新开始消费。至此,一次Rebalance完成。
-
当前p2也没有被消费,再次触发下一轮rebalance,将p2分配给consumer3消费。
6. kafka2.4 static membership功能
https://cwiki.apache.org/confluence/display/KAFKA/Incremental+Cooperative+Rebalancing%3A+Support+and+Policies
https://www.confluent.io/blog/incremental-cooperative-rebalancing-in-kafka/
https://www.confluent.io/blog/cooperative-rebalancing-in-kafka-streams-consumer-ksqldb/














 3362
3362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









