







ELK学习系列文章第一章:elasticsearch基础概念与安装、运行
一、背景介绍
今天是2016年12月10号,接触微服务大概一年多的时间,并且我们团队已经在去年使用微服务架构搭建我们数字化企业云平台,同时在这块也投入了很多时间去学习和研究,有一些经验和学习心得,可以和大家一起分享与学习,提到微服务我们可能会想到许多热门的知识点,比如docker、k8s、restful、Spring Boot、持续交付、分布式事务、服务拆分、日志收集分析与监控等等,提到日志收集分析与监控有两种比较常用的方案:(1)Flume+Kafka+Storm+HDFS(2)ELK(Elasticsearch+Logstash+Kibana)。接下来我会给大家分享是ELK系列相关知识,同时欢迎大家留言共同讨论,指出不足之处。
二、基础概念
2.1 Elasticsearch是什么
Elasticsearch是一个高扩展的、开放源代码的全文搜索与分析引擎。它允许你实时与快速地存储、搜索和分析大量的数据。它通常被用来作为底层引擎/技术。 Elasticsearch也是使用Java编写并使用Lucene来建立索引并实现搜索功能,但是它的目的是通过简单连贯的RESTful API让全文搜索变得简单并隐藏Lucene的复杂性,同时可以供其他开发语言进行调用。不过,Elasticsearch不仅仅是Lucene和全文搜索引擎,它还提供:
(1)分布式的实时文件存储,每个字段都被索引并可被搜索
(2)实时分析的分布式搜索引擎
(3)可以扩展到上百台服务器,处理PB级结构化或非结构化数据
随着知识的积累,你可以根据不同的问题领域定制Elasticsearch的高级特性,这一切都是可配置的,并且配置非常灵活。
2.2 使用场景
(1)电商领域:运行一个在线的网上商店,在那里你可以让你的客户搜索你销售的产品。在这种情况下,你可以使用Elasticsearch来存储您的整个产品目录和库存和为他们提供搜索和自动完成的建议。
(2)日志收集与分析:你想收集日志和交易数据,要分析和挖掘这些数据,寻找趋势,统计,总结,或异常。在这种情况下,你可以使用LogStash(Elasticsearch / LogStash / Kibana的一部分)的收集、汇总、格式化的数据,然后导入数据到Elasticsearch。一旦数据在Elasticsearch,你可以搜索和聚合你感兴趣的任何信息,并且使用Kibana进行展现。
(3)分析/商业智能:你有分析/商业智能的需求,并希望快速调查、分析、可视化,并提出了大量的数据的特设的问题(数以百万计或十亿的记录)。在这种情况下,你可以使用Elasticsearch来存储你的数据,然后用Kibana(的Elasticsearch / LogStash / Kibana堆栈的一部分)建立自定义的仪表板,展现你关心的重要数据。
2.3 重要概念
Elasticsearch有几个核心概念。从一开始理解这些概念会对整个学习过程有莫大的帮助,如下所示:
(1) 接近实时(NRT)Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒);
(2) 集群(cluster):一个集群就是由一个或多个节点组织在一起,它们共同持有你整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。在产品环境中显式地设定这个名字是一个好习惯,但是使用默认值来进行测试/开发也是不错的。
(3) 节点(node):一个节点是你集群中的一个服务器,作为集群的一部分,它存储你的数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
(4) 索引(index):一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。索引类似于关系型数据库中Database的概念。在一个集群中,如果你想,可以定义任意多的索引。
(5) 类型(type):在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。类型类似于关系型数据库中Table的概念。
(6) 文档(document):一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(JavaScript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。 在一个index/type里面,只要你想,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。文档类似于关系型数据库中Record的概念。实际上一个文档除了用户定义的数据外,还包括_index、_type和_id字段。
(7) 分片和复制(shards & replicas):为了解决水平扩展问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片;为了解决单节点故障问题,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片。当你创建一个索引的时候,你可以指定你想要的分片和复制的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
三、安装与运行
Elasticsearch即可以在windows下运行,也可以在Linux下运行,由于在windows下比较简单(点击bin\elasticsearch.bat),此处不做说明,Linux的安装如下:
(1) 下载安装包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.1.1.tar.gz
(2) 解压压缩文件
tar -zxvf elasticsearch-5.1.1.tar.gz(3) 使用默认配置启动
bin/elasticsearch若成功运行,其的界面如下所示:
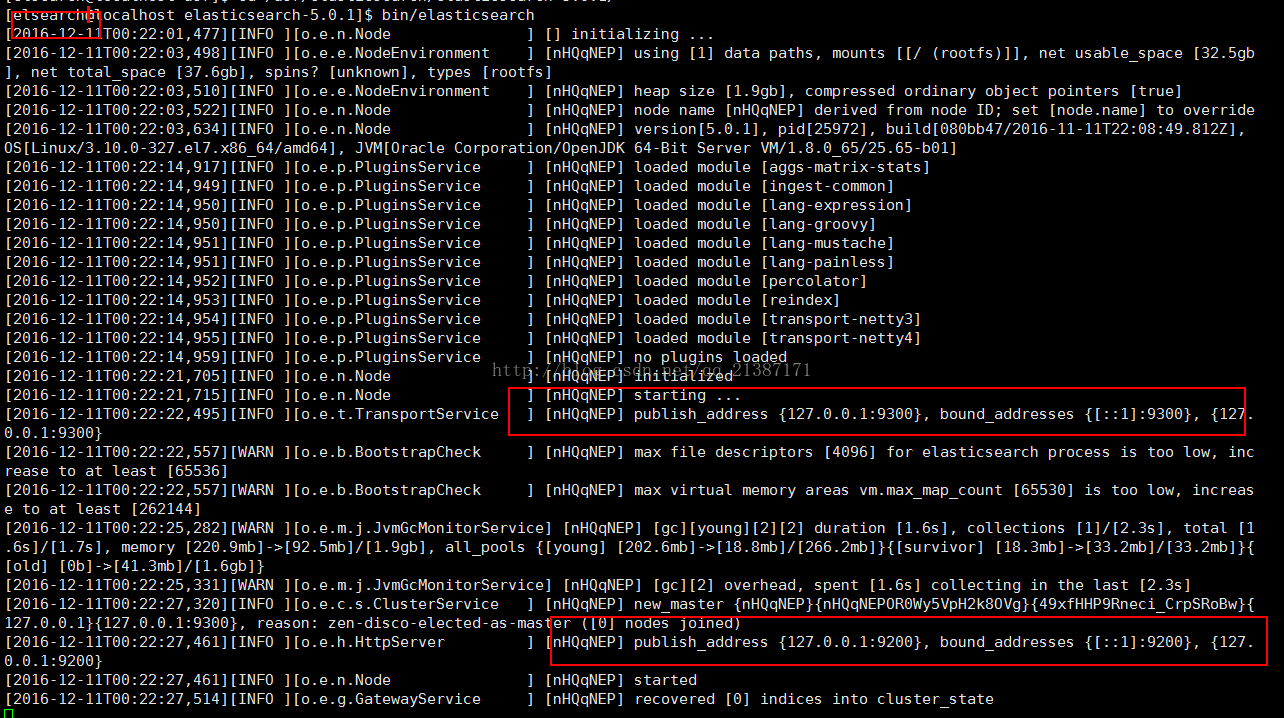
(4) 验证
打开另一个客户端,输入:curl 'http://localhost:9200’,如果显示下面的信息,则表示安装成功。
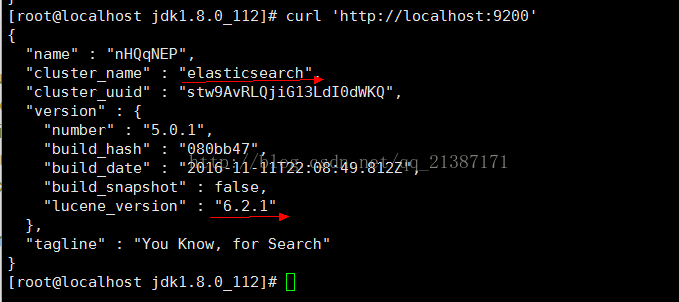
四、总结
本章介绍elasticsearch的定义、使用场景以及一些重要的概念,同时在linux环境上运行了elasticsearch的实例。由于在安装和运行elasticsearch时,踩过一些坑,所以下一章节讲述安装运行常见的错误以及解决方法,同时会进行配置信息的介绍。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









