






- 计算机视觉识别概述
计算机视觉识别(computer vision):用计算机来模拟人的视觉机理获取和处理信息的能力。就是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,用电脑处理成为更适合人眼观察或传送给仪器检测的图像。这里给出了几个比较严谨的定义:1.“对图像中的客观对象构建明确而有意义的描述”(Ballard&Brown,1982)2.“从一个或多个数字图像中计算三维世界的特性”(Trucco&Verri,1998)3.“基于感知图像做出对客观对象和场景有用的决策”(Sockman&Shapiro,2001)。
计算机视觉识别实际上是一个跨领域的交叉学科,包括计算机科学(图形、算法、理论、系统、体系结构),数学(信息检索、机器学习),工程学(机器人、语音、自然语言处理、图像处理),物理学(光学 ),生物学(神经科学)和心理学(认知科学)等等。计算机视觉研究相关的理论和技术,试图建立能够从图像或者多维数据中获取‘信息’的人工智能系统。计算机视觉的挑战是要为计算机和机器人开发具有与人类水平相当的视觉能力。 - 计算机视觉识别主要流程
计算机视觉的目标是从摄像机得到的二维图像中提取三维信息,从而重建三维世界模型。在这个过程中,获得场景中某一物体的深度,即场景中物体各点相对于摄像机的距离,无疑成为了计算机视觉的研究重点。获得深度图的方法可分为被动测距和主动测距。被动测距是指视觉系统接受来自场景发射或反射的光能量,形成有关场景的二维图像,然后在这些二维图像的基础上恢复场景的深度信息。具体实现方法可以使用两个或多个相隔一定距离的照相机同时获取场景图像,也可使用一台照相机在不同空间位置上分别获取两幅或两幅以上的图像。主动测距与被动测距的主要区别在于视觉系统是否是通过增收自身发射的能量来测距,雷达测距系统、激光测距系统则属于主动测距。主动测距的系统投资巨大,成本太高,而被动测距方法简单,并且容易实施,从而得到了广泛的应用。利用被动测距的计算机视觉主要分为四个步骤,如图所示。
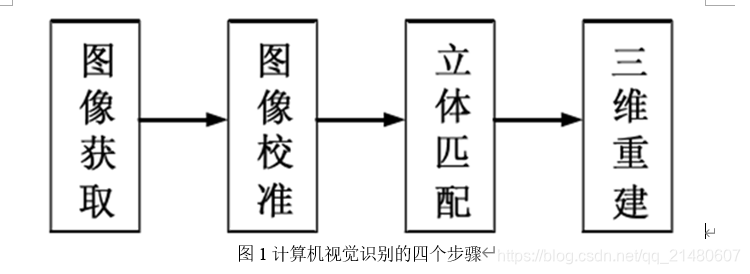
- 图像获取。
一般情况下,人类通过双眼来获得图像,双眼可近似为平行排列,在观察同一场景时,左眼获得左边的场景信息多一些,在左视网膜中的图像偏右;而右眼获得右边场景信息多一些,在右视网膜中的图像偏左。同一场景点在左视网膜上和右视网膜上的图像点位置差异即为视差,也是感知物体深度的重要信息。
计算机视觉的获取图像的原理与人眼相似,是通过不同位置上的相机来获得不同的图像,左摄像机拍摄的图像称为左图像,右摄像机拍摄的图像称为右图像。左图像得到左边的场景信息多一些,右图像得到右边场景的信息多一些, - 图像校准。
在图像获取过程中,有许多因素会导致图像失真,如成像系统的象差、畸变、带宽有限等造成的图像失真;由于成像器件拍摄姿态和扫描非线性引起的图像几何失真;由于运动模糊、辐射失真、引入噪声等造成的图像失真。 - 立体匹配。
在两幅或多幅不同位置下拍摄的且对应同一场景的图像中,建立匹配基元之间关系的过程称为立体匹配。例如,在双目立体匹配中,匹配基元选择像素,然后获得对应于同一个场景的两个图像中两个匹配像素的位置差别,即视差。并将视差按比例转换到0-255 之间,以灰度图的形式显示出来,即为视差图。 - 三维重建
根据立体匹配得到的像素的视差,如果已知照相机的内外参数,则根据摄像机几何关系得到得到场景中物体的深度信息,进而得到场景中物体的三维坐标。 - 计算机识别传统组成
计算机视觉系统的开发问题归纳为3个要素:
(1)数学理论
考虑数学计算层面的目标及可以引入的合理约束条件。
(2)描述和算法
重点解决计算机视觉中的输入输出的数据格式问题,并设计合理的算法实现其系统功能。
(3)硬件的合理使用
使用符合算法要求的硬件并考虑该硬件对所需要的算法和描述的反作用。
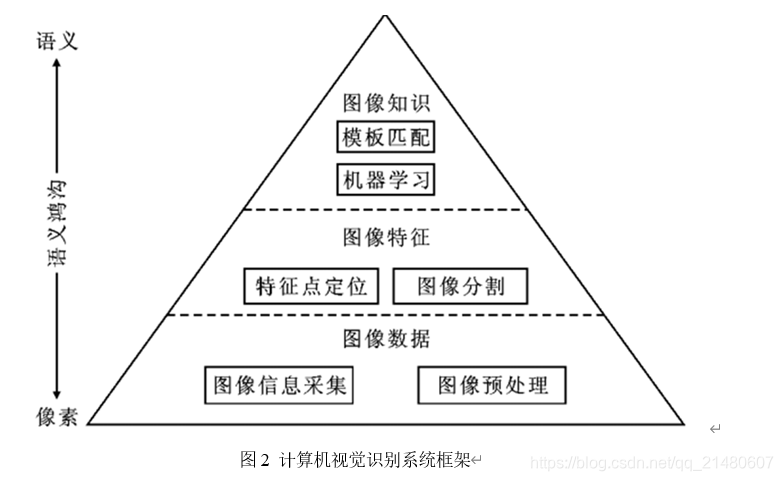
- 图像数据处理层
对图像像素或者频域进行相应处理,比如图像获取、传输、压缩、降噪、装换、存储、增强和复原等。 - 图像识别获取层
图像识别是指利用计算机对图像进行处理、分析和理解,以识别不同模式的目标和对象的技术,主要包括图像匹配和机器学习。图像匹配的研究内容大致集中在三个方面:特征空间;相似性度量;搜索策略 - 计算机视觉识别五大技术
1、图像分类
给定一组各自被标记为单一类别的图像,我们对一组新的测试图像的类别进行预测,并测量预测的准确性结果,这就是图像分类问题。图像分类问题需要面临以下几个挑战:视点变化,尺度变化,类内变化,图像变形,图像遮挡,照明条件和背景杂斑.
2、对象检测
识别图像中的对象这一任务,通常会涉及到为各个对象输出边界框和标签。这不同于分类/定位任务——对很多对象进行分类和定位,而不仅仅是对个主体对象进行分类和定位。在对象检测中,你只有 2 个对象分类类别,即对象边界框和非对象边界框。例如,在汽车检测中,你必须使用边界框检测所给定图像中的所有汽车。
3、目标跟踪
目标跟踪,是指在特定场景跟踪某一个或多个特定感兴趣对象的过程。传统的应用就是视频和真实世界的交互,在检测到初始对象之后进行观察。现在,目标跟踪在无人驾驶领域也很重要,例如 Uber 和特斯拉等公司的无人驾驶。
根据观察模型,目标跟踪算法可分成 2 类:生成算法和判别算法。
4、语义分割
计算机视觉的核心是分割,它将整个图像分成一个个像素组,然后对其进行标记和分类。特别地,语义分割试图在语义上理解图像中每个像素的角色(比如,识别它是汽车、摩托车还是其他的类别)。除了识别人、道路、汽车、树木等之外,我们还必须确定每个物体的边界。因此,与分类不同,我们需要用模型对密集的像素进行预测。
5、实例分割
除了语义分割之外,实例分割将不同类型的实例进行分类,比如用 5 种不同颜色来标记 5 辆汽车。分类任务通常来说就是识别出包含单个对象的图像是什么,但在分割实例时,我们需要执行更复杂的任务。我们会看到多个重叠物体和不同背景的复杂景象,我们不仅需要将这些不同的对象进行分类,而且还要确定对象的边界、差异和彼此之间的关系!















 9217
9217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











