




摘要
在数据处理和分析领域,Join(连接)操作是最核心、最耗时的任务之一。传统上,Join 在数据库中进行,但随着数据量的爆发式增长和实时处理需求的提升,内存计算(In-Memory Computing)因其极高的性能优势而变得越来越重要。将数据加载到内存中进行 Join 操作,可以避免昂贵的磁盘 I/O 和网络传输开销,从而实现毫秒级甚至微秒级的响应。
本文将深入探讨在 Java 生态中实现内存 Join 的多种技术方案。将从最基础的集合操作开始,逐步深入到使用现代 Stream API、高性能第三方库(如 Eclipse Collections、Joinery),并最终介绍利用嵌入式内存数据库实现完整的 SQL Join 功能。此外,还将详细分析每种方案的适用场景、性能瓶颈和优化策略,并提供大量的实战代码示例。
本文的目标读者是需要在应用程序中实现高效数据关联的 Java 开发工程师、数据工程师和架构师。
第一章:内存 Join 的核心概念与挑战
1.1 什么是内存 Join?
内存 Join 是指将多个数据集完全加载到应用程序的内存(RAM)中,并在此使用编程语言(如 Java)提供的原语或库函数来执行关联查询的操作。它跳过了传统数据库管理系统(DBMS)的查询解析、优化、执行计划生成和磁盘访问阶段,直接在内存中进行数据关联,从而获得极高的性能。
1.2 为什么需要内存 Join?
-
极致性能:内存访问速度比磁盘快几个数量级,避免了数据库查询的网络往返延迟和磁盘 I/O 瓶颈。
-
减轻数据库压力:将复杂的 Join 操作从生产数据库卸载到应用层,可以显著降低数据库的 CPU 和内存负载。
-
实时数据处理:对于流式处理或实时分析,数据可能尚未持久化到数据库,需要在内存中进行即时关联。
-
离线数据分析:在数据挖掘、机器学习特征工程等场景中,需要频繁地对大规模数据集进行关联操作。
-
架构灵活性:不依赖于外部数据库,可以在任何 Java 运行环境中执行复杂的数据操作。
1.3 内存 Join 的主要挑战
-
内存容量:数据集必须能够完全放入内存,且需要预留空间用于中间计算结果。对于超大规模数据,需要进行分片处理。
-
算法效率:Join 算法的时间复杂度至关重要。错误的实现可能导致 O(n²) 的复杂度,无法处理大规模数据。
-
数据一致性:在内存中管理多个数据集的同步和更新比在数据库中更复杂。
-
JVM 优化:需要深入了解 JVM 的内存管理、垃圾回收机制,以避免 GC 停顿影响性能。
1.4 Join 的类型
与 SQL 类似,内存 Join 也支持多种类型:
-
内连接(INNER JOIN):只返回两个数据集中键匹配的记录。
-
左外连接(LEFT OUTER JOIN):返回左数据集的所有记录,以及右数据集中匹配的记录。
-
右外连接(RIGHT OUTER JOIN):返回右数据集的所有记录,以及左数据集中匹配的记录。
-
全外连接(FULL OUTER JOIN):返回两个数据集的所有记录,匹配的合并,不匹配的填充空值。
-
交叉连接(CROSS JOIN):返回两个数据集的笛卡尔积。
-
半连接(SEMI JOIN):只返回左数据集中在右数据集中存在匹配键的记录,但不对右数据集进行展开。
1.5 实现方案
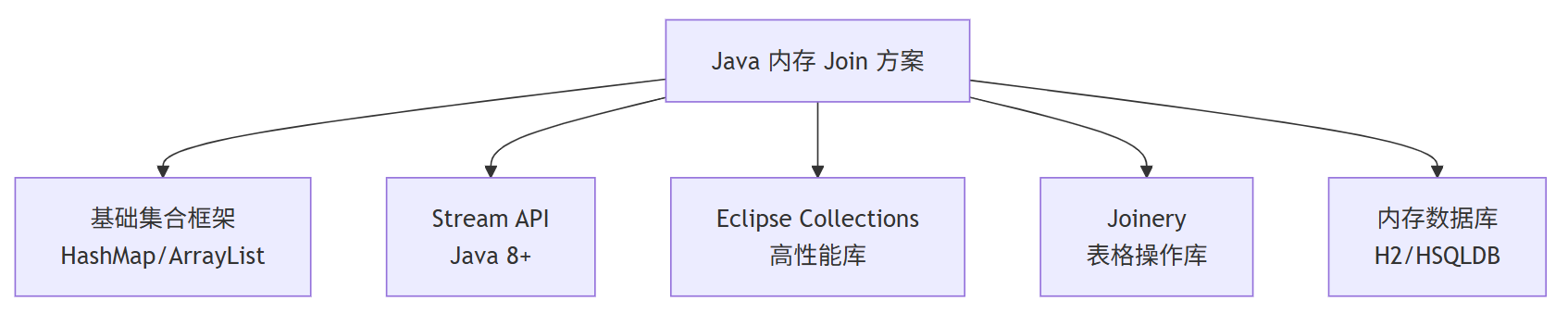
第二章:基于 Java 集合框架的基础实现
2.1 内连接(INNER JOIN)实现
内连接是最常用的 Join 类型,以下是基于 HashMap的高效实现方式:
import java.util.*;
import java.util.stream.Collectors;
public class BasicInnerJoin {
// 订单实体类
static class Order {
int orderId;
int customerId;
double amount;
String product;
Order(int orderId, int customerId, double amount, String product) {
this.orderId = orderId;
this.customerId = customerId;
this.amount = amount;
this.product = product;
}
}
// 客户实体类
static class Customer {
int customerId;
String name;
String email;
Customer(int customerId, String name, String email) {
this.customerId = customerId;
this.name = name;
this.email = email;
}
}
// 连接结果类
static class JoinedResult {
int orderId;
String customerName;
String product;
double amount;
String email;
JoinedResult(int orderId, String customerName, String product, double amount, String email) {
this.orderId = orderId;
this.customerName = customerName;
this.product = product;
this.amount = amount;
this.email = email;
}
@Override
public String toString() {
return String.format("Order %d: %s bought %s for $%.2f (Email: %s)",
orderId, customerName, product, amount, email);
}
}
public static void main(String[] args) {
// 模拟数据
List<Order> orders = Arrays.asList(
new Order(1, 101, 100.0, "Laptop"),
new Order(2, 102, 200.0, "Phone"),
new Order(3, 101, 150.0, "Tablet"),
new Order(4, 103, 300.0, "Monitor") // 客户103不在客户表中,将被内连接过滤
);
List<Customer> customers = Arrays.asList(
new Customer(101, "Alice", "alice@example.com"),
new Customer(102, "Bob", "bob@example.com"),
new Customer(104, "Charlie", "charlie@example.com") // 没有订单,不会出现在结果中
);
// 核心实现:使用HashMap构建查找表
Map<Integer, Customer> customerMap = new HashMap<>();
for (Customer customer : customers) {
customerMap.put(customer.customerId, customer);
}
// 执行INNER JOIN
List<JoinedResult> joinedData = new ArrayList<>();
for (Order order : orders) {
Customer customer = customerMap.get(order.customerId);
if (customer != null) { // 只添加匹配的记录
joinedData.add(new JoinedResult(
order.orderId,
customer.name,
order.product,
order.amount,
customer.email
));
}
}
// 输出结果
joinedData.forEach(System.out::println);
// 输出统计信息
System.out.println("\n统计信息:");
System.out.println("订单数: " + orders.size());
System.out.println("客户数: " + customers.size());
System.out.println("连接结果数: " + joinedData.size());
}
}
算法分析:
-
时间复杂度:O(m + n),其中 m 是 customers 的大小,n 是 orders 的大小。构建 HashMap 是 O(m),遍历 orders 是 O(n)。
-
空间复杂度:O(m + k),其中 m 是 customers 的大小,k 是匹配的结果数。
-
优势:极其高效,适用于大多数场景。
-
劣势:需要足够的内存来存储 HashMap 和结果集。
2.2 左外连接(LEFT OUTER JOIN)实现
左外连接需要保留左表(orders)的所有记录,即使右表(customers)中没有匹配项。
// 接上面的类定义...
public class LeftOuterJoin {
public static void main(String[] args) {
// 使用相同的数据...
List<Order> orders = Arrays.asList(...);
List<Customer> customers = Arrays.asList(...);
Map<Integer, Customer> customerMap = customers.stream()
.collect(Collectors.toMap(c -> c.customerId, c -> c));
// 执行LEFT OUTER JOIN
List<JoinedResult> joinedData = new ArrayList<>();
for (Order order : orders) {
Customer customer = customerMap.get(order.customerId);
// 与内连接的关键区别:即使customer为null也保留订单记录
joinedData.add(new JoinedResult(
order.orderId,
customer != null ? customer.name : "Unknown Customer", // 处理空值
order.product,
order.amount,
customer != null ? customer.email : "N/A" // 处理空值
));
}
joinedData.forEach(System.out::println);
}
}
2.3 使用 Java 8 Stream API 实现函数式 Join
Java 8 引入的 Stream API 提供了更声明式的实现方式:
import java.util.*;
import java.util.stream.*;
public class StreamJoinExample {
public static void main(String[] args) {
List<Order> orders = Arrays.asList(...);
List<Customer> customers = Arrays.asList(...);
// 使用Stream API实现INNER JOIN
Map<Integer, Customer> customerMap = customers.stream()
.collect(Collectors.toMap(c -> c.customerId, Function.identity()));
List<JoinedResult> joinedData = orders.stream()
.filter(order -> customerMap.containsKey(order.customerId)) // 过滤掉不匹配的
.map(order -> {
Customer customer = customerMap.get(order.customerId);
return new JoinedResult(
order.orderId,
customer.name,
order.product,
order.amount,
customer.email
);
})
.collect(Collectors.toList());
// 使用Stream API实现LEFT OUTER JOIN
List<JoinedResult> leftJoinedData = orders.stream()
.map(order -> {
Customer customer = customerMap.get(order.customerId);
return new JoinedResult(
order.orderId,
customer != null ? customer.name : "Unknown Customer",
order.product,
order.amount,
customer != null ? customer.email : "N/A"
);
})
.collect(Collectors.toList());
}
}
第三章:使用高性能第三方库
对于更复杂或大规模的场景,使用专门的库可以提供更好的性能和更丰富的功能。
3.1 使用 Eclipse Collections
Eclipse Collections 是高性能的 Java 集合框架,提供了丰富的内存计算功能。
首先添加依赖:
<dependency>
<groupId>org.eclipse.collections</groupId>
<artifactId>eclipse-collections</artifactId>
<version>11.0.0</version>
</dependency>
实现代码:
import org.eclipse.collections.api.list.ImmutableList;
import org.eclipse.collections.api.list.MutableList;
import org.eclipse.collections.impl.factory.Lists;
public class EclipseCollectionsJoin {
static class Product {
int id;
String name;
double price;
Product(int id, String name, double price) {
this.id = id;
this.name = name;
this.price = price;
}
}
static class Sale {
int productId;
int quantity;
String date;
Sale(int productId, int quantity, String date) {
this.productId = productId;
this.quantity = quantity;
this.date = date;
}
}
public static void main(String[] args) {
// 使用Eclipse Collections的特殊列表
MutableList<Product> products = Lists.mutable.with(
new Product(1, "Laptop", 999.99),
new Product(2, "Phone", 699.99),
new Product(3, "Tablet", 399.99)
);
MutableList<Sale> sales = Lists.mutable.with(
new Sale(1, 2, "2023-01-01"),
new Sale(2, 1, "2023-01-02"),
new Sale(1, 3, "2023-01-03"),
new Sale(4, 5, "2023-01-04") // 没有对应产品
);
// 转换为基于ID的Map
Map<Integer, Product> productMap = products.toMap(Product::getId, p -> p);
// 实现INNER JOIN
MutableList<String> report = sales.select(s -> productMap.containsKey(s.productId)) // 过滤
.collect(s -> {
Product p = productMap.get(s.productId);
return String.format("%s: %d x $%.2f = $%.2f on %s",
p.name, s.quantity, p.price, s.quantity * p.price, s.date);
});
report.forEach(System.out::println);
}
}
优势:
-
更丰富的数据操作API
-
更好的内存布局和性能优化
-
延迟计算能力
3.2 使用 Joinery 进行表格化 Join
Joinery 是一个专门用于数据操作和可视化的 Java 库,提供了类似 pandas 的 DataFrame API。
添加依赖:
<dependency>
<groupId>joinery</groupId>
<artifactId>joinery</artifactId>
<version>1.9</version>
</dependency>
实现代码:
import joinery.DataFrame;
import java.util.Arrays;
public class JoineryExample {
public static void main(String[] args) {
// 创建第一个DataFrame
DataFrame<Object> dfCustomers = new DataFrame<>("customer_id", "name", "email");
dfCustomers.append(Arrays.asList(101, "Alice", "alice@example.com"));
dfCustomers.append(Arrays.asList(102, "Bob", "bob@example.com"));
dfCustomers.append(Arrays.asList(103, "Charlie", "charlie@example.com"));
// 创建第二个DataFrame
DataFrame<Object> dfOrders = new DataFrame<>("order_id", "customer_id", "amount", "product");
dfOrders.append(Arrays.asList(1, 101, 100.0, "Laptop"));
dfOrders.append(Arrays.asList(2, 102, 200.0, "Phone"));
dfOrders.append(Arrays.asList(3, 101, 150.0, "Tablet"));
dfOrders.append(Arrays.asList(4, 104, 300.0, "Monitor")); // 客户104不存在
System.out.println("Customers DataFrame:");
System.out.println(dfCustomers);
System.out.println("\nOrders DataFrame:");
System.out.println(dfOrders);
// 执行INNER JOIN
DataFrame<Object> innerJoined = dfOrders.joinOn("customer_id").inner(dfCustomers);
System.out.println("\nInner Join Result:");
System.out.println(innerJoined);
// 执行LEFT JOIN
DataFrame<Object> leftJoined = dfOrders.joinOn("customer_id").left(dfCustomers);
System.out.println("\nLeft Join Result:");
System.out.println(leftJoined);
// 添加计算列
leftJoined.add("amount_with_tax");
for (int i = 0; i < leftJoined.length(); i++) {
Double amount = (Double) leftJoined.get(i, 2); // amount列
leftJoined.set(i, 5, amount != null ? amount * 1.1 : null); // 添加10%的税
}
System.out.println("\nLeft Join with Tax Calculation:");
System.out.println(leftJoined);
}
}
优势:
-
类似 SQL 的声明式语法
-
支持多种 Join 类型
-
内置数据清洗、转换功能
-
支持数据可视化
第四章:高级主题与性能优化
4.1 并行处理大规模数据
对于超大规模数据集,可以使用 Java 的并行流来加速处理:
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.stream.Collectors;
public class ParallelJoin {
public static void main(String[] args) {
// 生成大规模测试数据
List<Order> orders = generateOrders(100_000);
List<Customer> customers = generateCustomers(10_000);
// 使用并发安全的Map
Map<Integer, Customer> customerMap = customers.parallelStream()
.collect(Collectors.toConcurrentMap(c -> c.customerId, c -> c));
// 并行执行JOIN
List<JoinedResult> joinedData = orders.parallelStream()
.filter(order -> customerMap.containsKey(order.customerId))
.map(order -> {
Customer customer = customerMap.get(order.customerId);
return new JoinedResult(
order.orderId,
customer.name,
order.product,
order.amount,
customer.email
);
})
.collect(Collectors.toList());
System.out.println("处理了 " + joinedData.size() + " 条记录");
}
private static List<Order> generateOrders(int count) {
List<Order> orders = new ArrayList<>(count);
Random random = new Random();
for (int i = 0; i < count; i++) {
orders.add(new Order(
i,
random.nextInt(10000), // customerId在0-9999范围内
random.nextDouble() * 1000,
"Product_" + random.nextInt(100)
));
}
return orders;
}
private static List<Customer> generateCustomers(int count) {
List<Customer> customers = new ArrayList<>(count);
for (int i = 0; i < count; i++) {
customers.add(new Customer(
i,
"Customer_" + i,
"customer_" + i + "@example.com"
));
}
return customers;
}
}
4.2 内存分页与批处理
当数据量超过可用内存时,需要实现分页处理:
public class PagedJoin {
public static void main(String[] args) {
int pageSize = 1000;
int totalPages = getTotalPages(pageSize);
Map<Integer, Customer> customerMap = loadAllCustomers();
for (int page = 0; page < totalPages; page++) {
List<Order> ordersPage = loadOrdersPage(page, pageSize);
List<JoinedResult> pageResults = ordersPage.stream()
.filter(order -> customerMap.containsKey(order.customerId))
.map(order -> {
Customer customer = customerMap.get(order.customerId);
return new JoinedResult(...);
})
.collect(Collectors.toList());
// 处理当前页的结果
processPageResults(pageResults);
// 手动触发GC管理内存
if (page % 10 == 0) {
System.gc();
}
}
}
private static List<Order> loadOrdersPage(int page, int pageSize) {
// 实现分页数据加载逻辑
return Collections.emptyList();
}
private static int getTotalPages(int pageSize) {
// 计算总页数
return 100;
}
}
4.3 使用内存数据库进行复杂 Join
对于需要完整 SQL 功能的场景,可以使用嵌入式内存数据库:
import org.h2.jdbcx.JdbcConnectionPool;
import java.sql.*;
public class InMemoryDatabaseJoin {
public static void main(String[] args) throws SQLException {
// 创建内存数据库连接池
JdbcConnectionPool cp = JdbcConnectionPool.create(
"jdbc:h2:mem:test;DB_CLOSE_DELAY=-1", "sa", "");
try (Connection conn = cp.getConnection();
Statement stmt = conn.createStatement()) {
// 创建表
stmt.execute("CREATE TABLE customers (" +
"customer_id INT PRIMARY KEY, " +
"name VARCHAR(50), " +
"email VARCHAR(100))");
stmt.execute("CREATE TABLE orders (" +
"order_id INT PRIMARY KEY, " +
"customer_id INT, " +
"amount DECIMAL(10,2), " +
"product VARCHAR(50), " +
"FOREIGN KEY (customer_id) REFERENCES customers(customer_id))");
// 插入数据
stmt.execute("INSERT INTO customers VALUES " +
"(101, 'Alice', 'alice@example.com'), " +
"(102, 'Bob', 'bob@example.com'), " +
"(103, 'Charlie', 'charlie@example.com')");
stmt.execute("INSERT INTO orders VALUES " +
"(1, 101, 100.0, 'Laptop'), " +
"(2, 102, 200.0, 'Phone'), " +
"(3, 101, 150.0, 'Tablet'), " +
"(4, 104, 300.0, 'Monitor')");
// 执行复杂JOIN查询
String sql = "SELECT o.order_id, c.name, o.product, o.amount, c.email " +
"FROM orders o " +
"LEFT JOIN customers c ON o.customer_id = c.customer_id " +
"WHERE o.amount > 100 " +
"ORDER BY o.amount DESC";
try (ResultSet rs = stmt.executeQuery(sql)) {
while (rs.next()) {
System.out.printf("Order %d: %s bought %s for $%.2f (Email: %s)%n",
rs.getInt("order_id"),
rs.getString("name"),
rs.getString("product"),
rs.getDouble("amount"),
rs.getString("email"));
}
}
}
}
}
第五章:性能对比与最佳实践
5.1 各方案性能对比
|
方案 |
适用场景 |
性能 |
功能丰富度 |
内存使用 |
学习曲线 |
|---|---|---|---|---|---|
|
基础集合 |
简单Join,小数据集 |
高 |
低 |
低 |
低 |
|
Stream API |
中等复杂度,函数式风格 |
中高 |
中 |
中 |
中 |
|
Eclipse Collections |
高性能需求,复杂操作 |
很高 |
高 |
低 |
中高 |
|
Joinery |
表格操作,数据分析 |
中 |
很高 |
高 |
中 |
|
内存数据库 |
复杂SQL,完整事务支持 |
中低 |
极高 |
高 |
高 |
5.2 最佳实践
-
选择合适的数据结构:根据数据特性和访问模式选择 HashMap、TreeMap 或并发集合。
-
预热JVM:对于性能敏感的应用,进行JVM预热以避免即时编译带来的性能波动。
-
监控内存使用:使用 -Xmx 参数合理分配内存,避免 OutOfMemoryError。
-
使用对象池:对于频繁创建和销毁的对象,考虑使用对象池减少GC压力。
-
批处理与分页:处理超大规模数据时,采用分页策略避免内存溢出。
-
选择合适的GC算法:对于内存计算密集型应用,选择 G1GC 或 ZGC 减少停顿时间。
5.3 常见陷阱与解决方案
-
内存泄漏:长时间持有不再需要的对象引用。解决方案:定期清理缓存和使用弱引用。
-
GC停顿:大量对象创建导致频繁GC。解决方案:使用对象池和调整GC参数。
-
数据倾斜:某些键的数据量远大于其他键。解决方案:检测并处理倾斜键,或使用自定义分区策略。
-
并发问题:多线程环境下数据竞争。解决方案:使用并发集合或同步机制。
第六章:结论
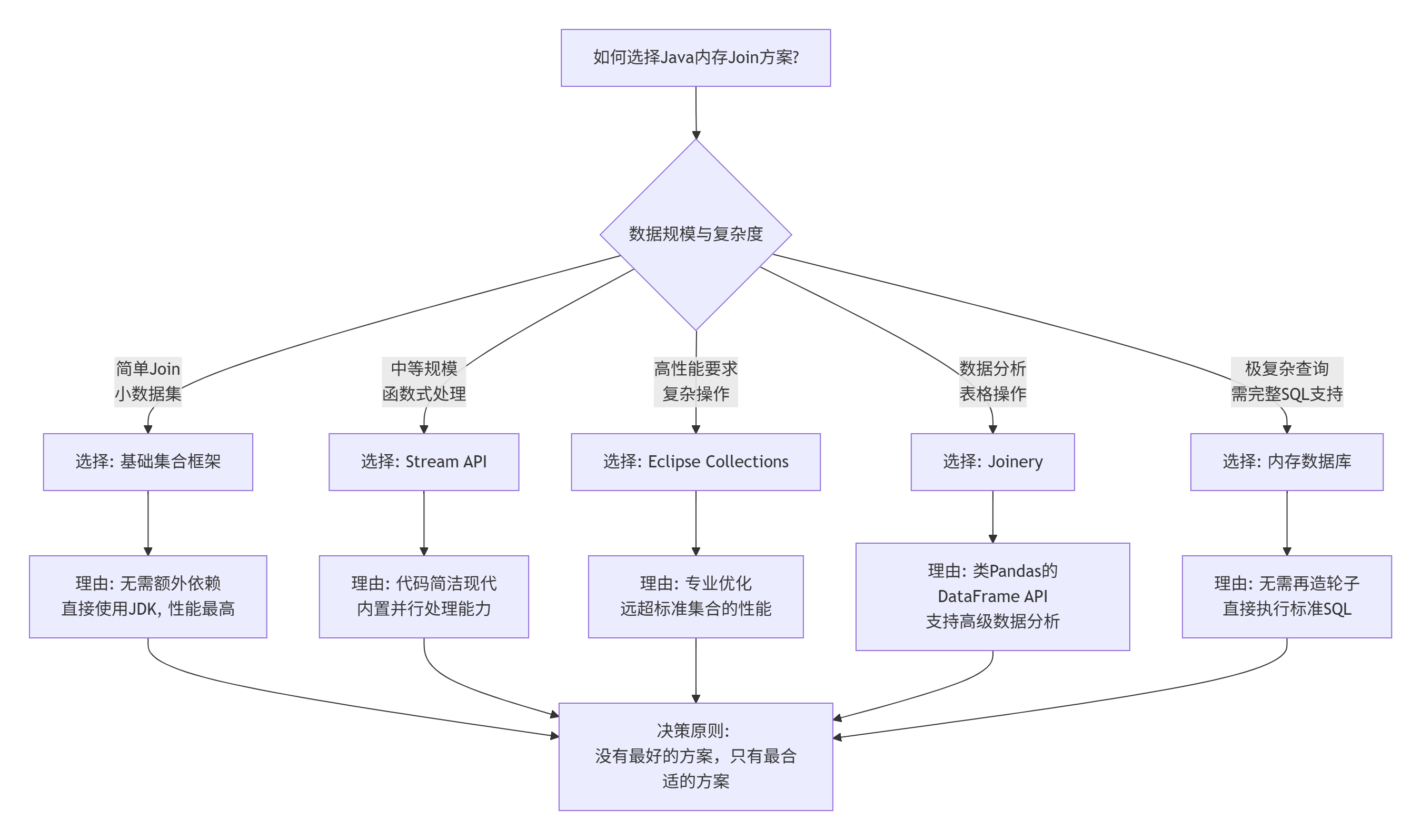
Java 提供了多种强大的内存 Join 实现方式,每种方案都有其独特的优势和适用场景。选择哪种方案取决于具体的需求:
-
对于简单、小规模的 Join 操作,使用基础集合框架是最直接的选择。
-
对于需要函数式编程风格和中等复杂度的场景,Stream API 提供了良好的平衡。
-
对于高性能、大规模数据处理,Eclipse Collections 是优秀的选择。
-
对于需要类似 pandas 的表格操作和数据分析,Joinery 提供了丰富的功能。
-
对于需要完整 SQL 功能和复杂查询的场景,内存数据库是最佳选择。
无论选择哪种方案,都需要注意内存管理、性能优化和并发处理。正确实施内存 Join 可以显著提升应用程序的数据处理能力,为实时分析和决策提供强大支持。
随着硬件成本的降低和内存容量的增加,内存计算将成为越来越重要的技术趋势。掌握 Java 内存 Join 技术,将为你在数据处理领域的职业发展提供有力支持。



















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











